13 minute read · August 16, 2021
5 Limitations of Data Warehouses in Today’s World of Infinite Data

· Product Marketing Director, Dremio

Does it feel like you are pouring your budgets into data warehousing solutions with very little ROI? Well, you are not alone! Here are some alarming facts from a recent June 2021 Wakefield survey:


You can get more details on the above study here and learn more about how you can improve your ROI in data management and data analytics solutions.
The Situation Today
Today, organizations are modernizing to catch up with the speed of unimaginable amounts of data created daily by modern-day apps and users. As cloud data lake storage becomes increasingly cheap, enterprises are storing near-infinite amounts of data. According to a March 2021 IDC study, in 2020, 64.2 ZB of data was created or replicated and the amount of digital data created over the next five years will be greater than twice the amount of data created since the advent of digital storage!
Enterprises today need data architectures that can rapidly adapt to zettabytes of data and to the exponential increase in user requests for data. Executives and IT leaders want to empower their business users to have timely and self-service access to organizational data, so that they can support new initiatives and evolving business needs. At the same time, they also want their organizations and architectures to be flexible, open, scalable and ready to change quickly to adopt new technologies and innovations as they become available in the market.
Does your organization still use data warehousing solutions? If so, what exactly is a data warehouse? And why are organizations of all sizes across industries trying to free themselves from the shackles of traditional, proprietary data warehouses? Let’s explore this!
What Is a Data Warehouse?
Data warehouses originated in the late 1980s and were intended to be central repositories of data for long-term storage and analysis and the basis for business intelligence on top of raw transactional data across different systems. Simply put, a data warehouse is a system used for storing, analyzing and reporting data.
Typically, raw data was collected from multiple systems and a central copy of that data was stored within the data warehouse so users from different divisions or departments within an organization could access and analyze the data according to their varied business needs.
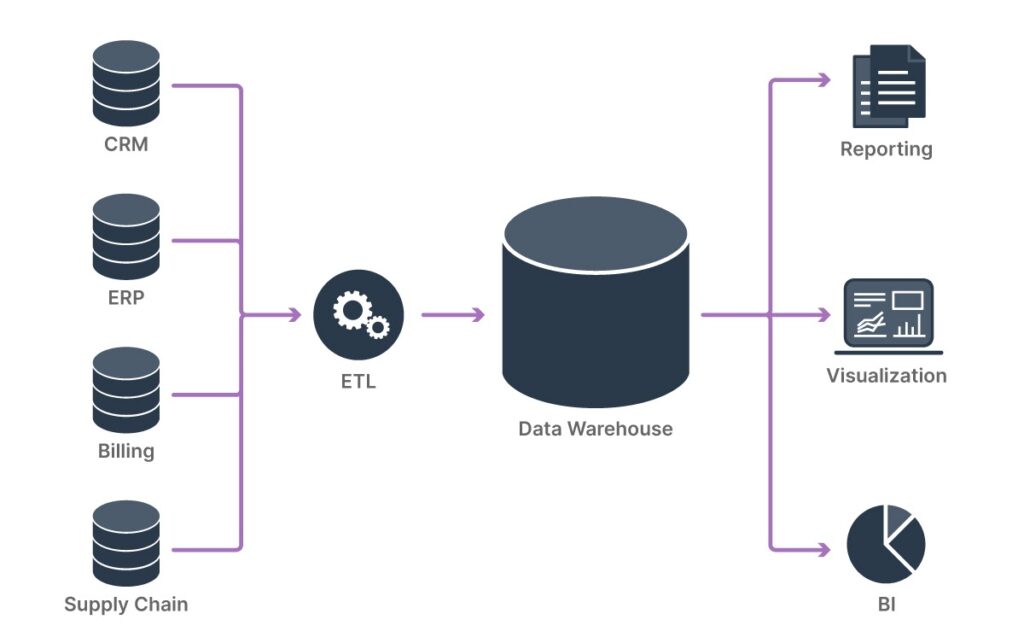
The purpose of a data warehouse is to house standardized, structured, consistent, integrated and “cleaned” data, extracted from various operational systems in an organization, and to serve as an analytical tool to support decision making and reporting needs across varied departments. Data warehouses also serve as archives, holding historical data not maintained in operational systems. Learn more about data warehouses here.
Issues with Data Warehouse Architecture and Approach
Data warehouses were intended to create a single, unified system of truth for an entire organization. Unfortunately, as you might imagine, the manipulation of the data itself and the creation of multiple data copies for different purposes at different levels in the data warehouse architecture has resulted in a very complex system that is incredibly difficult, time-consuming and expensive for organizations to create and maintain. There is a very high risk of data drift and data inconsistencies in data warehouses because of the multiple data copies that are created at different levels of the architectural model — this is called the “Pyramid of Doom.”
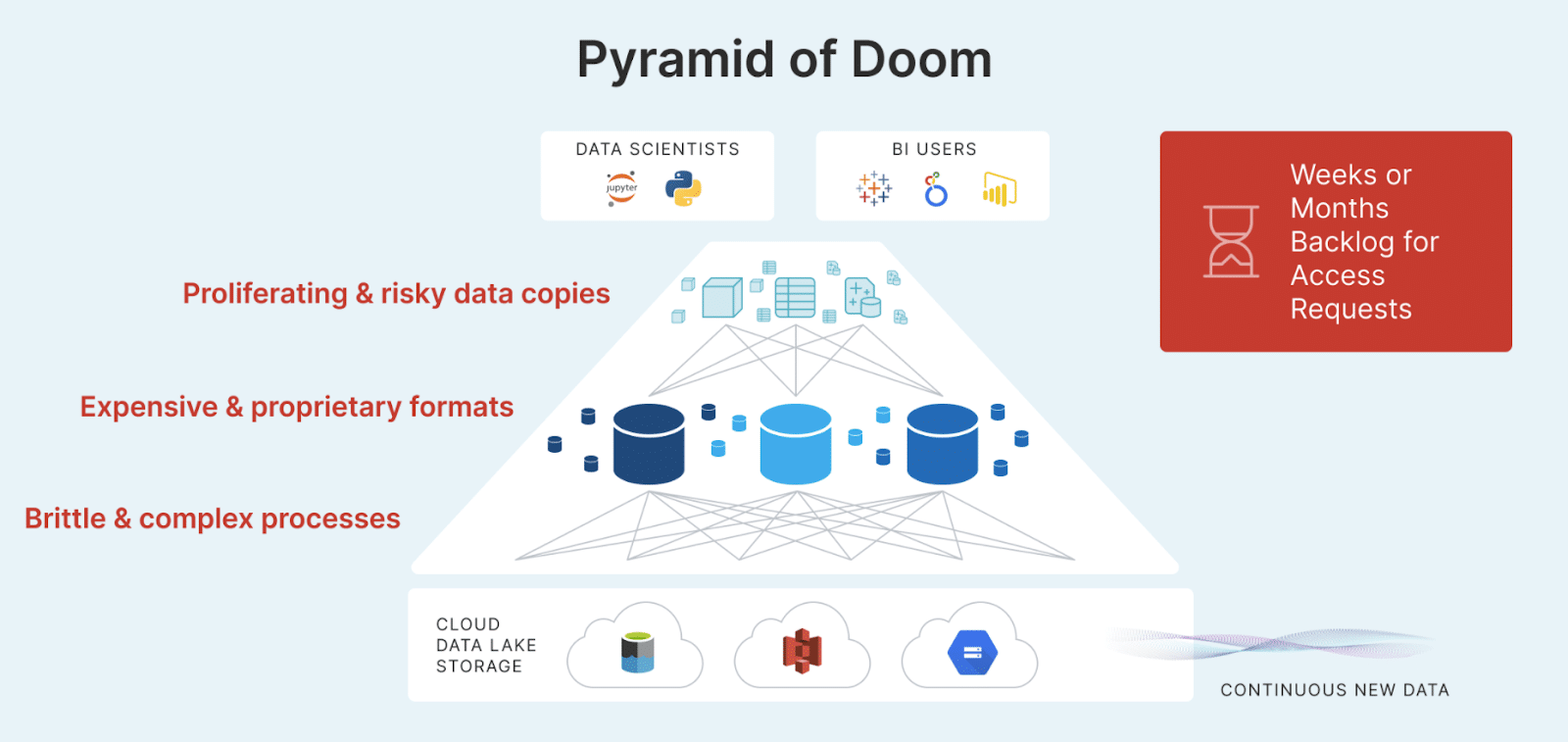
The Problem of Multiple Data Copies and the TCO of Data Warehouses
The sheer design of the data warehouse architecture — the ETL processes inherent to data warehousing, the entire replication of the data from the transactional systems into the data warehouse, the OLAP cubes created to optimize reporting on data warehouses and the several layers of personalized and optimized data copies created — is responsible for creating multiple copies of data at different layers of the data warehouse, which creates unnecessary redundancies and duplication of data and efforts and exponentially increases the infrastructure and maintenance costs over time. Data leaders are frequently concerned about the out-of-control costs of data warehouses, particularly as their workloads grow — a big surprise to them since the data warehouse cost of entry can be low to start. Here is a handy guide to help you calculate the TCO of data warehouses, so that your budgets do not get out of hand.
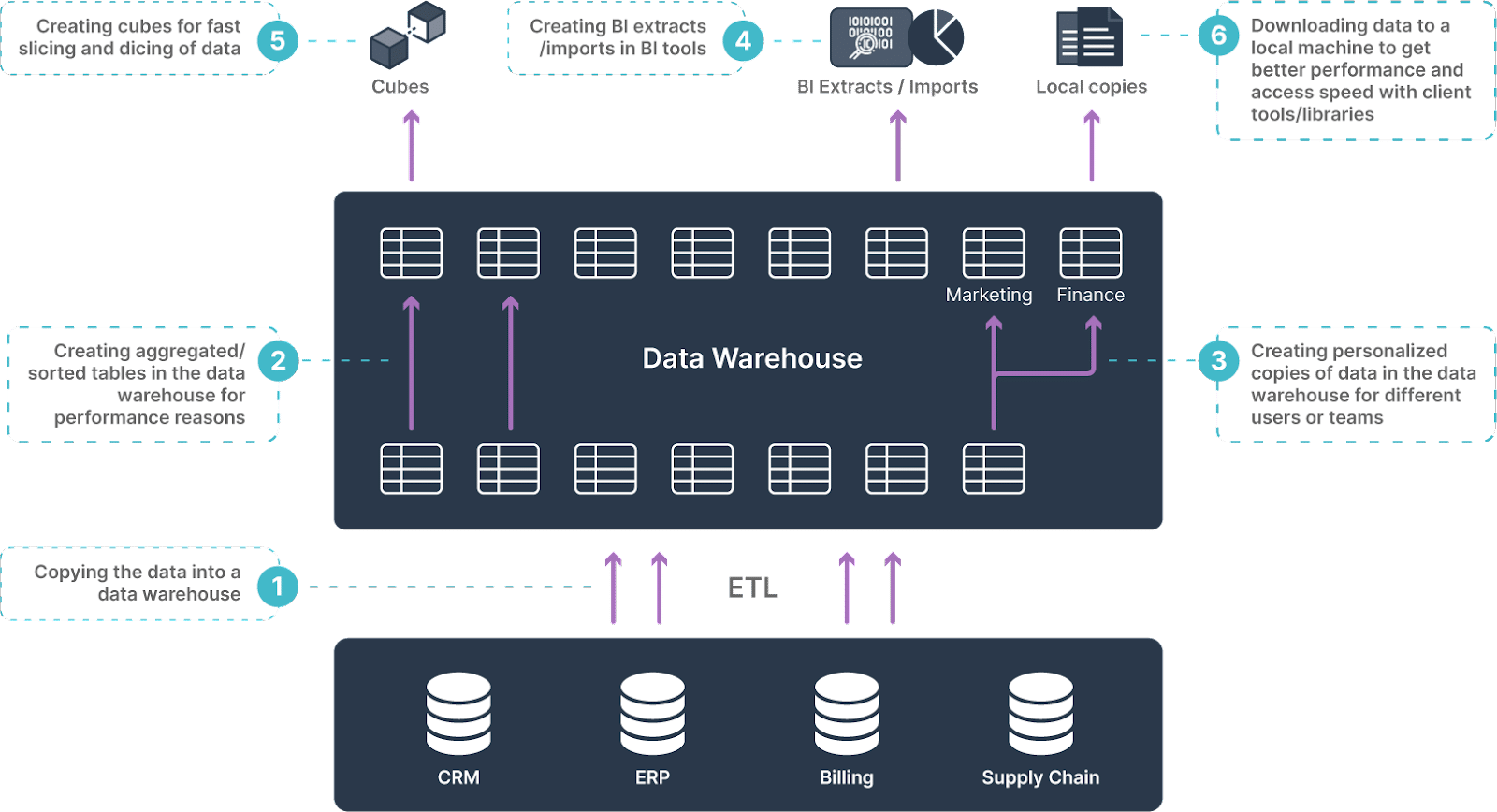
The Pyramid of Doom created by data warehouses leads to inevitable proliferation of multiple data copies, just due to the inherent design of data warehouses and of the data warehousing processes that make data available for analytics and reporting.
To cope with the exponential growth of modern-day data and to keep pace with new technologies in the market, companies must eliminate the need to copy and move data in proprietary data warehouses or the need to create cubes, aggregation tables and BI extracts. Learn more about the high costs of multiple data copies in your data warehouse and how you can eliminate expensive data copies with a data lakehouse.
If Data Warehouses Are So Complex to Build and Maintain, Why Do Organizations Bother?
Data warehouses were designed to provide the following benefits:
- A consolidated point of access to all data in a single database and data model, rather than requiring users to connect to dozens or even hundreds of systems individually
- Separation of analytical systems from the day-to-day operational (transactional) systems in terms of reporting as well as access and security
- To ensure standardization and data quality across multiple systems
- A history of all the data collected from multiple systems, rather than just transactional details, even if the source systems do not have this historical data
- A standard set of semantics maintained in a single database and data model around data collected from multiple systems in terms of: consistency in naming conventions, codes for different types of products, languages, currencies and so on
- Restructure of the raw data that business users and departments can use for their specific needs and use cases
- Transformation of data collected from multiple systems in such a way that the query performance is enhanced
5 Crippling Limitations of Data Warehouses in Today’s World of Infinite Data
Multiple data copies: Unfortunately, data warehouses have delivered the above benefits but the inherent design of data warehousing has provided these benefits at the cost of creating multiple, redundant data copies throughout the organization’s architecture, exponentially increasing the infrastructure setup and maintenance costs and time to value.
Designed to create redundancies: And to make things worse, additional copies of data are frequently created in the data warehouse for personalized needs, aggregated analysis, specific use cases and dashboards. With this magnitude of data explosion, the bigger question is where and how organizations will store the data and how they will access this data without making multiple copies of that data and at what price.
Inconsistency and inaccuracy of data: Chief Data Officers and data architects constantly worry about data drift and lack of data governance and security as they deal with the complexity of such data architectures and multiple data copies. Additionally, they know the pain and time-consuming processes required to set up and maintain complex ETL processes to copy multiple subsets of data into a data warehouse for different use cases and reporting purposes. The costs, in terms of manpower and infrastructure, just keeps increasing with time to a point where it gets out of control.
Lack of self-service data access and delayed time to insight: And after much effort and exponential costs, data consumers cannot even access the data themselves and end up relying heavily on data teams, who in turn get overwhelmed with weeks or months of data request backlogs. It takes weeks or even months for users to get access to the data in the form that suits their reporting and dashboard needs. Data warehouse architectures delay time to value and slow down business insight.
Economic burden due to vendor lock-in: The architecture of data warehouses is also designed in a way that increases dependency of the organization on the proprietary data warehouse vendor to a point where the organization cannot access their own data without paying the vendor. This is called vendor lock-in, and is inherently designed into the pricing strategies of data warehouse architectures — such that companies cannot free themselves from proprietary data warehouse vendors, even when there is a new, better technology alternative available in the market. Learn how and why companies are breaking free from vendor lock-in and long-term economic dependencies.
Time to Stop “Band-Aiding” Data Warehouses
Data warehouses have been around for so many years that they have become a well-established discipline in many organizations. Also, because of their closed, inflexible architectures, companies are “locked-in” with data warehousing vendors and find it difficult to break free from their shackles. Decision-makers as well as data teams recognize and understand the challenges of data warehouses, and over the years several workarounds have been created to overcome the inherent problems of data warehouses (although those workarounds are slow and extremely expensive). Read this article to understand how the continued use of a data warehouse is nothing but a “Band-Aid” — used to make existing data preparation methods for analytics last longer. This Business Wire press release discusses how Dremio empowers your teams with mission-critical SQL workloads directly on the data lake and enables your users to directly query data for high-performing dashboards and interactive analytics, without the need for copying data into data warehouses or creating aggregation tables, extracts, cubes and other derivatives.
Why Are Organizations Dumping Their Data Warehouses and Moving Their Data to Data Lakes?
As more and more organizations migrate to the cloud, or aspire to optimize their existing investments in the cloud, decision-makers are trying to break free from the intrinsic dependencies on traditional data warehouse vendors and liberate their organizations and budgets from the lock-in and economic extortion of proprietary data vendors. Chief Technology Officers (CTOs) and CDOs want their organizations and architectures to be flexible, open, scalable and ready to change quickly to adopt new technologies and innovations as they become available in the market. Organizations are quickly modernizing their data architectures to data lakes and data lakehouse platforms that provide solutions that combine the flexibility, cost-effectiveness and scalability of data lakes as well as the performance and data management capabilities that traditional data warehouses have provided. Companies are adopting solutions that complement their current investments in data warehouses, and at the same time open up a broader set of data to a larger group of data consumers for diverse analytical needs and reduce time to value from weeks or months to seconds. Read how you can shorten the development time of data pipelines, accelerate queries and deliver results even with complex queries in seconds.
It’s too expensive to create multiple data copies just to expedite your reporting and dashboards! Your data analysts, data scientists and business users need a better solution rather than something that forces them to create multiple layers of copies for all the above mentioned reasons. Ideally, data teams and business users should be able to analyze the data directly in the data lake at interactive speed, with instantaneous results, without needing to copy data into expensive data warehouses or create multiple, redundant performance-optimized copies in different data stores. Learn how you can enable your data teams and business users to eliminate the high cost of data copies!
To achieve this, they need a high-speed query engine that delivers high-performing BI dashboards and interactive analytics directly on the data lake, works seamlessly with existing BI tools that users are familiar with and provides security and data governance features equivalent to those in a data warehouse.
Fortunately, Dremio’s modern data architecture makes it possible to query data lakes directly at interactive speed — at the speed of business — avoiding the need for a data warehouse and redundant data copies. Read this whitepaper to understand how the Dremio SQL lakehouse platform helps you break free from the intrinsic dependencies on traditional, closed data warehouse vendors and liberates your organizations from proprietary vendor lock-in, empowers your teams with accelerated time to value and enables you to put your data in the hands of more people, faster, with self-service access and high-levels of enterprise-grade security.
Don’t just take our word for it. Datanami, the news portal dedicated to providing insight, analysis and up-to-the-minute information about emerging trends and solutions in big data, recently proclaimed,“Did Dremio Just Make Data Warehouses Obsolete?”
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->