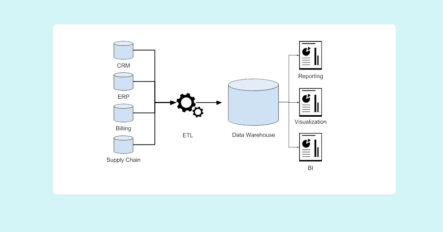
What Is a Data Warehouse?
A data warehouse is a system used for storing and reporting on data. The data typically originates in multiple systems, then it is moved into the data warehouse for long-term storage and analysis. Data warehouses are on-premises or in the cloud. This storage is structured so users from many divisions or departments within an organization can access and analyze the data according to their needs.

Why Organizations Use Data Warehouses
Organizations typically use data warehouses for analytical, structured reporting and business intelligence. They integrate data from various sources and make it available to analysts and other data consumers.
How a Data Warehouse Can Create Structured, Useful Data
Raw data from source systems and applications often needs processing before it can be used for analysis. Data warehouses are used to store data that’s been integrated, cleansed and formatted so that it’s ready for analytics and reporting systems.
You might hear both “data warehouse” and “enterprise data warehouse” (EDW) used. They’re exactly the same — the “enterprise” part refers to a single master warehouse for a large organization, collating from multiple sites and departments.
Benefits of a Data Warehouse
Many businesses rely on a Data Warehouse to tap into the value of their enterprise data. One of the main benefits of data warehouses is that they contain structured data. Structured data refers to the way that data is stored, with fields, formats, and so on, defined in advance. Data stored in the warehouse follows this structure (or schema) rigorously. As a result, data in the warehouse is relatively consistent and stable.
Data warehouses can be created on-premises or in the cloud. Both offer similar basic functionality, but on-premises solutions are significantly more expensive and result in a higher total cost of ownership. They also tend to have fewer security mitigations and fewer options for accessing the data.
On-Premises Versus Cloud Data Warehouse
There are two basic types of data warehouses:
- Virtual or ‘Traditional’ Data Warehouse: This type of setup collects data from lots of locations and files, and turns them into a common format, ready to be queried.
- Cloud Data Warehouse (CDW): Cloud data warehouses don’t require any extra hardware as everything is collated and organized “in the cloud.” They are more scalable and cost-effective. Major CDW vendors like AWS, Google and Microsoft Azure offer 99%+ uptime service-level agreements, unlike on-premises which is subject to the whims of the IT infrastructure. Most enterprise data warehouses are cloud-based —it’s a much simpler way for the system to keep track of lots of data sets from all over the world, without having to create local versions of each.
Advantages of a Cloud Data Warehouse
Cloud systems have a lower total cost of ownership compared to on-premises solutions, and also offer better performance and higher speeds of data transfer.
If you need external access to the data, a cloud-based solution offers a much more holistic and seamless interface over a more secure connection, which can be integrated with existing applications, APIs and software stacks.
The biggest advantage of using a CDW is its elasticity. You can expand and contract the size of your warehouse seamlessly as your needs change without the need for regular optimization.
Why Use a Data Warehouse?
Data warehouses can provide:
- A single point of access for all data, rather than requiring users to connect to dozens or even hundreds of systems individually
- An assurance of data quality
- A history of the data they store
- Separation between day-to-day operational systems and analytical systems, for security reasons
- A standard set of semantics around data, for example: consistency in naming conventions, codes for different types of products, languages, and currencies
Storing comprehensive data in structured relationships means that data warehouses can also provide answers to a whole variety of complex questions, like:
- How much revenue has each of our product lines brought in per month over the past ten years, broken out by city and state?
- What is the average transaction size at one of our ATMs, broken out by time of day and total customer assets?
- What is the percentage of employee turnover for the past year in stores that have been open for at least three years? How many hours did those employees work per week?
Data Warehouse Architecture
When it comes to building data warehouse architecture, there are three approaches.
One-Tier Architecture
This architecture creates a compact data set, and manages a minimal amount of stored data.
One-tier architecture removes data redundancies but doesn’t scale in terms of users. There’s very little processing of the data as there is no data mart, and no OLAP Layer, which we discuss in a moment.
It’s primarily a way of storing data at minimal cost with minimal redundancy — in other words, it’ll remove the “junk” data and any duplication, but that’s all. You won’t see these very often, because they generally don’t have any kind of failsafe if things go wrong. Plus, if the data is being updated, it can cause some issues with the results of your searches and reports. This is a cheaper option, but cheaper isn’t always better.
Two-Tier Architecture
A second-tier adds what’s called a “data mart,” which is a bit like the lobby in a hotel. As new data is added, it is analyzed and categorized “on-the-fly” before being added to the warehouse pool. That process reduces the clash between warehouse data and live data in the system. The only problem is that once a two-tier system is full, you’re stuck and upgrading is tricky.
Three-Tier Architecture
A three-tier system adds what’s called an “OLAP Layer.” The OLAP layer is like a filing clerk. It files all of the data using the most space-efficient option and remembers where it all is. So, when you need to access the data, it can be found quickly. The system is always making the best use of your storage space, plus it’s scalable, so you can add extra storage as the business grows.
Dremio and Data Warehouses
Dremio is complementary to your data warehouse, and opens up a broader set of data to a larger set of data consumers for diverse analytical needs. Dremio's forever-free lakehouse platform.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI




