13 minute read · May 28, 2024
The Nessie Ecosystem and the Reach of Git for Data for Apache Iceberg
· Head of DevRel, Dremio
· Founder, Bauplan Labs
· CEO, Bauplan

Introduction
The Data Lakehouse is rapidly emerging as the ideal data architecture, utilizing a single source of truth on your data lake. This is made possible by technologies like Apache Iceberg and Project Nessie. Apache Iceberg, a revolutionary table format, allows you to organize files on your data lake into database tables and execute efficient transactions with robust ACID guarantees. Project Nessie complements Iceberg as a catalog for these data lake tables, making them accessible to various tools. Its unique strength lies in enabling a "Git for Data" experience at the catalog level, allowing you to track changes, isolate modifications with branching, merge changes for publication, and create tags for easily replicable points in time across all your tables simultaneously.
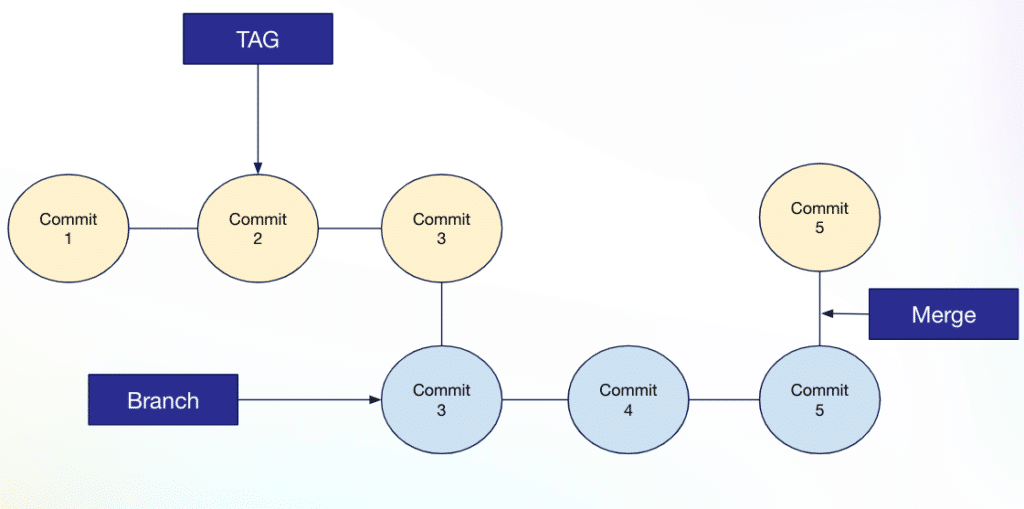
Apache Iceberg's ecosystem has flourished, offering many tools for reading, writing, and optimizing Iceberg tables. Similarly, Project Nessie's ecosystem is experiencing rapid growth, embraced by platforms like Dremio where it was initially created, Bauplan, and open-source tools such as Apache Spark, Apache Flink, Presto, and Trino.
Beyond these core platforms, the recent Subsurface conference keynote announced Nessie's adoption of the Apache Iceberg REST catalog specification. This move opens the ecosystem to numerous new tools, simplifies usage with the Apache Iceberg Python API, and paves the way for emerging Rust and Go Apache Iceberg APIs.
In this blog, we'll explore the two platforms built around Nessie technology—Dremio and Bauplan—to showcase Nessie's power and how they utilize this cutting-edge open-source technology.
Dremio
Dremio, a comprehensive Data Lakehouse Platform, offers unified access to your data across diverse sources, a powerful SQL query engine, and robust lakehouse management features. This makes managing an Apache Iceberg-based lakehouse as effortless as your preferred data warehouse, without excessive data replication.

At the core of Dremio Cloud's data lakehouse management capabilities lies its integrated catalog, powered by Project Nessie. Dremio enhances Nessie's core functionality for tracking tables, changes, and query history and provides a user-friendly interface with several notable advantages:
- Effortless Catalog Creation: Generate as many catalogs as needed with a simple click.
- Automated Optimization and Cleanup: Set rules to ensure your tables consistently perform optimally.
- Intuitive Dashboard: Monitor commits, branches, and tags across your catalogs with ease.
Try out this tutorial to get hands-on experience and learn about the power of Nessie’s Git for Data features alongside the Dremio Lakehouse Platform. It can be done locally on your laptop using a dockerized environment. You can watch a walkthrough of this exercise on the Dremio Youtube channel.
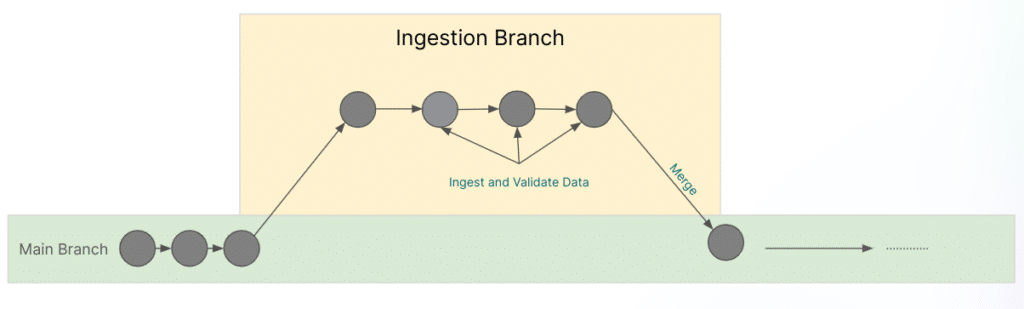
Dremio's open architecture empowers a data-anywhere, deliver-everywhere approach. It supports many data sources, including databases, data lakes, and warehouses. Users can access all datasets via open interfaces such as a REST API, JDBC/ODBC, and Apache Arrow flight for analytics, data science, and more. Apache Iceberg tables cataloged in Dremio's Nessie-based catalogs can be seamlessly utilized in other tools like Apache Spark, Apache Flink, and Bauplan.
Dremio is a unified access layer for curating, organizing, governing, and analyzing your data. It simplifies the implementation of cutting-edge dataops and data mesh patterns, optimizes costs, and enhances overall productivity within your data platform through its open nature. Dremio has also recently announced Enterprise Support for Nessie in the Dremio Software product.
Get Started with Dremio Today!!!
Bauplan
Bauplan is a programmable data lake, offering optimized multi-language runtimes (Python and SQL) for data workloads over object storage (e.g. parquet files on S3). Bauplan's main abstraction is the data pipeline, that is, a series of tables produced by repeatedly applying transformations to source, “raw” datasets.
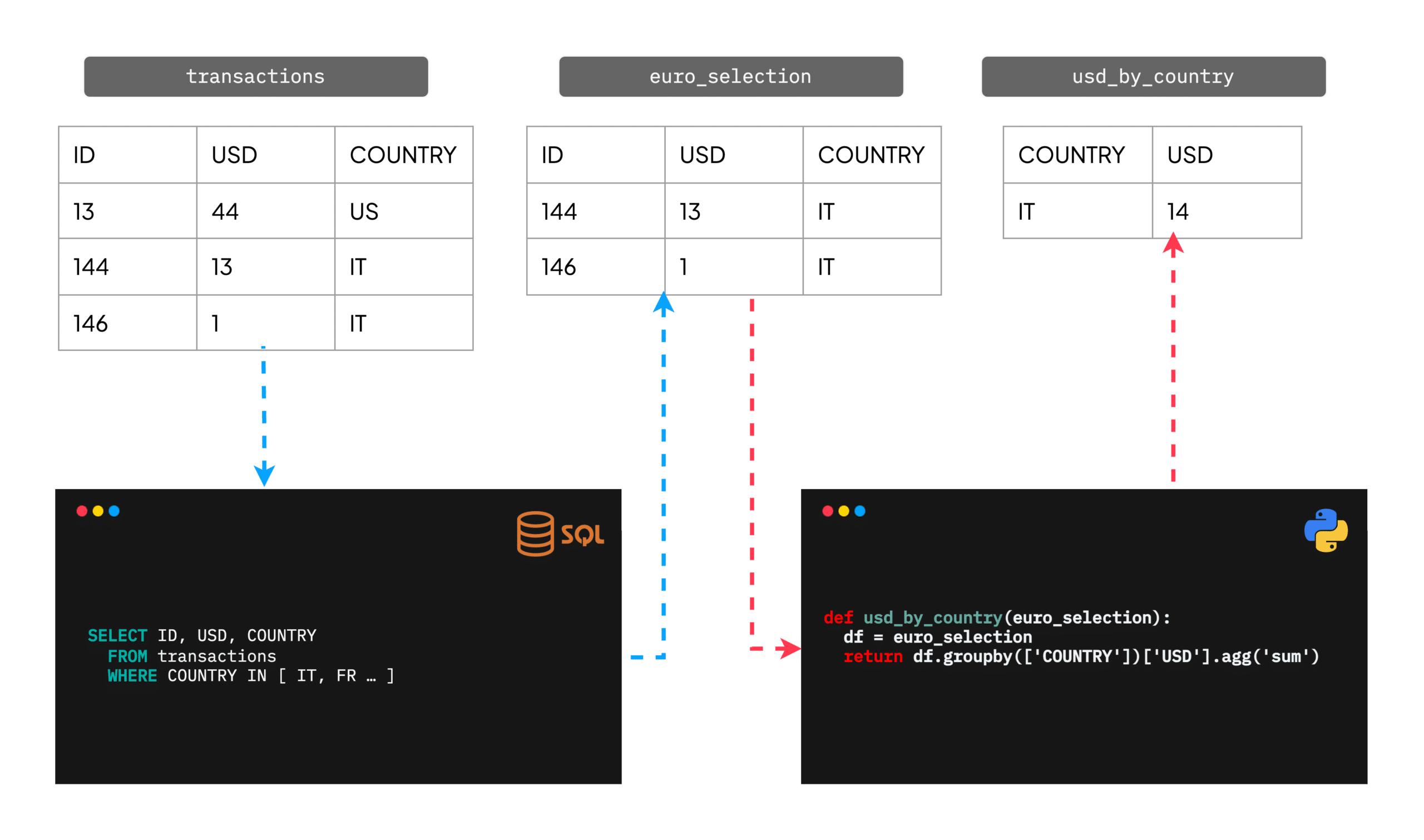
A data pipeline is a collection of tables obtained by applying SQL or Python to source tables.
In this example, the source table “transactions” logs individual transactions for several countries; the child table “euro_selection” is created from it by filtering for countries in the euro-zone; finally, “usd_by_country” is an aggregation table created by applying a Pandas transformation to “euro_selection”. Bauplan interoperates with SQL engines such as Dremio SQL Engine to provide a unified runtime to run the above transformations, abstracting away data movement, containerization, and caching to the final user.
The easiest way to appreciate Nessie for Bauplan is to start from a concrete example in pipeline maintenance. Jacopo wakes up Tuesday with an alert: the pipeline that ran Monday night produced unexpectedly an empty “usd_by_country” table that needs to be investigated. We can’t just re-run the code on production Tuesday, as data may have changed in the meantime and you wouldn’t want your debugging pipelines to create conflict with your colleagues depending on a clean, stable production data lake. The picture below depicts our ideal scenario:
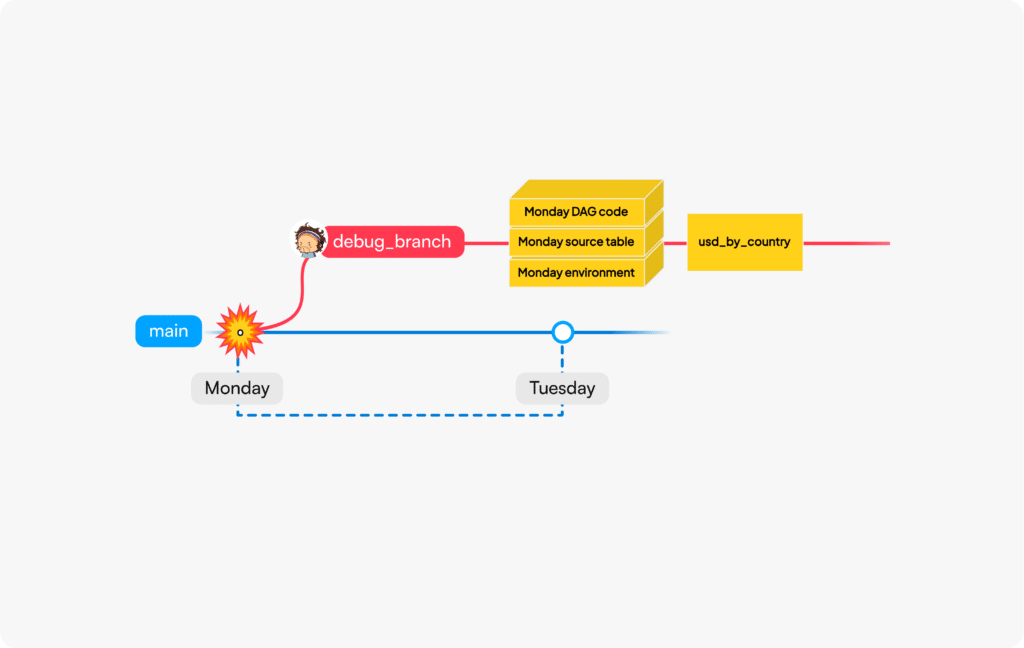
A production incident: to debug Monday’s failure we need Git for code and for data.
- Jacopo can branch out from production data as of Monday to create a new debug branch; this debug branch will host temporary tables during debugging;
- Jacopo can retrieve the code that ran on Monday and apply it to the source tables in the debug branch to recreate the bug (i.e. the empty table).
Walking back from our ideal debugging scenario, it should now be clear why Nessie is our catalog of choice: the Nessie abstraction over Iceberg tables allows us to perform both time-travel - how did the data look like on Monday? - and sandboxing - can I debug on production data without creating conflicts in the production environment? Through its zero-copy, multi-table capabilities, Nessie enables seamless Git-like experience on data pipelines, not just data tables: when combined with Bauplan meta-store (which is storing the code), the entire debugging can be performed with three commands in the terminal:
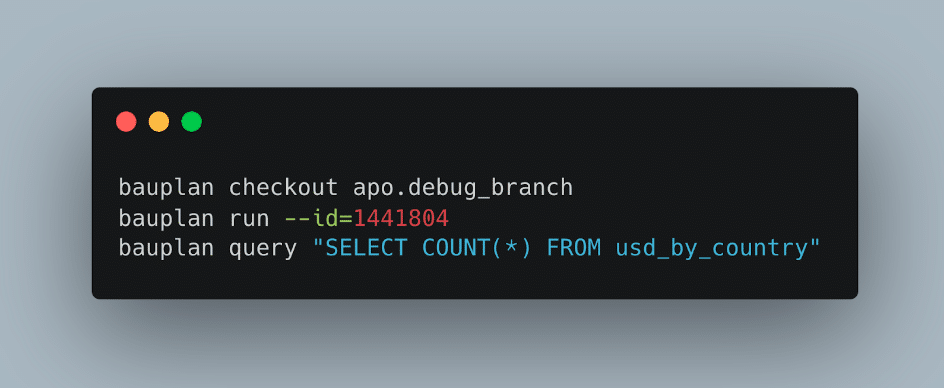
Re-running an arbitrary pipeline in Bauplan leveraging Nessie.
- Create a new branch;
- Re-run the pipeline from Monday by id: it’s Bauplan responsibility to retrieve from its metastore both the state of the data lake and the code base from Monday;
- Verify that in the debug branch the “usd_by_country” is actually empty: it is again Bauplan's responsibility to route the query to the appropriate engine and branch, and stream back results to the user.
Finally, while interactions for Bauplan users are high-level, Git-like APIs, the underlying system speaks natively Iceberg and Arrow, and it’s therefore fully interoperable with the Dremio lakehouse: you can create a table in Python with Bauplan and query it with Dremio by simply accessing the underlying Nessie catalog; viceversa, you can start a Bauplan pipeline from an table you created with Dremio Engine in the Dremio Integrated Catalog. Building on Nessie and open standards allowed us to move faster and immediately gained access to a thriving ecosystem of interoperable tools.
If you want to know more about the interplay between pipelines and Nessie, Bauplan will present their paper on reproducible pipelines at SIGMOD2024.
Conclusion
As platforms like Dremio and Bauplan embrace Nessie, they underscore its pivotal role in enhancing data governance and operational efficiency through its 'Git for Data' approach. The recent adoption of the Apache Iceberg REST catalog specification by Nessie not only broadens its accessibility and usability across different programming environments but also cements its position as a cornerstone in the data architecture landscape. This strategic move amplifies the utility of Nessie, enabling it to serve a wider array of applications and fostering a more robust, interoperable ecosystem. As such, the future of Nessie and the catalog versioning paradigm it enables looks exceedingly promising, setting a new standard for data management practices and offering profound value to organizations aiming to harness the full potential of their data assets.
Learn more about Dremio at Dremio University and Read the paper “Building a serverless Data Lakehouse from spare parts” by Jacopo Tagliabue & Ciro Greco of Baulplan.
Talks from Subsurface 2024 Related to Git-for-Data:
- Keynote | Next-Gen DataOps with Iceberg & Git for Data
- Achieving Full CI/CD in Dremio with DBT: A Case Study of Quebec Blue Cross
- DataOps at Dremio Lakehouse Management
- Prod is the New Dev: Using Nessie to Build the Definitive CI/CD for Data
- Flight as a Service (FaaS) for Data Pipelines:Combining fast Python functions w/Dremio through Arrow
- Automating Reflections Management with the Dremio-Airflow Plugin
- Using Dremio to Implement a DataOps Framework for Managing Data Products
Sign up for AI Ready Data content
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->