SQL Query Engine
Designed for high-performance BI and interactive analytics directly on the data lake
The Lakehouse Query Engine optimized for high performance and efficiency
Sub-second BI workloads directly on your data lake and across all your data sources with no data movement. Deliver a seamless end-user experience with transparent query optimization and acceleration.
Optimized price performance for every query
Execute every query with the optimal balance of speed and cost-effectiveness. Dremio's multi-engine architecture enables sophisticated workload management. It's simple to create multiple right-sized, physically isolated engines for various workloads in your organization, ensuring performance predictability and making it easy to manage critical SLAs. Intelligent autoscaling dynamically manages your query workload based on established engine parameters.
Cost-based optimization ensures the fastest path to complete every query by understanding deep data statistics, including location, cardinality, and distribution.
Learn how workload management drives best price performance ‑>
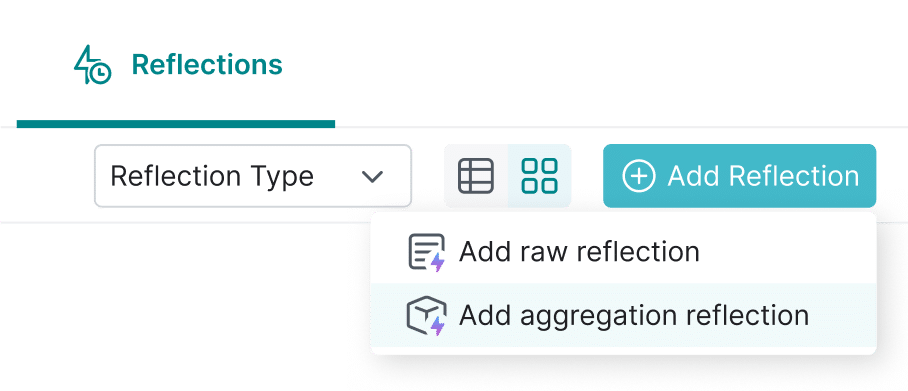
Up to 100x faster performance with Reflections query acceleration
Attain near-instantaneous query performance with Reflections query acceleration. Reflections are optimized relational caches that use algebraic matching to accelerate entire or partial queries. Reflections are completely transparent to data users. During the query process, the Dremio optimizer matches the best Reflections to accelerate the query. Performance for all queries is also accelerated using Columnar Cloud Cache (C3). C3 selectively caches only the data required to satisfy your workloads, eliminating 90% of I/O costs.
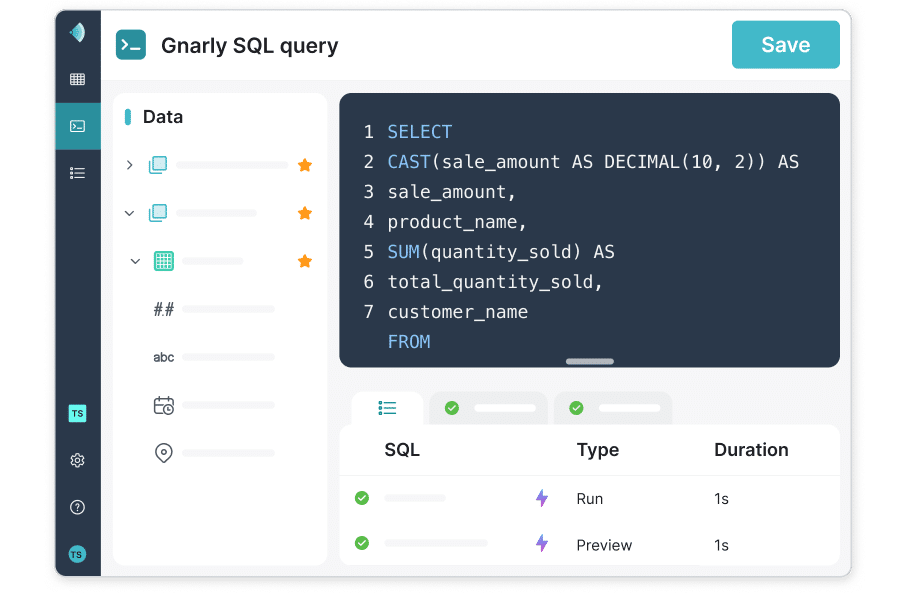
Flexible, fast, lightweight data transformation
Reduce reliance on costly ETL tools and brittle, complex data pipelines. Dremio makes it easy to apply last mile data transformations, including filtering, sorting, aggregating, joining, casting. These transformations can be quickly built as Dremio Views - governed virtual data sets with layered transformations - that can be flexibly shared and modified for downstream data projects.
Federated querying for all your data, everywhere
Designed for interactive analytics and DML on the data lake, the Dremio SQL Query Engine makes it easy to analyze all of your data - whether on the data lake or in other data sources. Our connector ecosystem features dozens of integrations with an array of sources, including object storage, metastores, and databases in the cloud and on premises. Because Dremio queries your data at the source, there is no data movement, no data copies, and no complex ETL.


Built for the Cloud, Multi-Cloud, on-premises, and hybrid environments
Query your data where it lives - whether in the Cloud, across clouds, on-premises, or in hybrid environments. Dremio understands that many organizations choose to distribute their workloads across different cloud platforms, allowing them to leverage the strengths of each provider while avoiding vendor lock-in. With Dremio, you can access all of your data to put it to analytic work in seconds.
Learn more about how Dremio connects your data everywhere ‑>
Dremio Customer Case Studies

Case Study
Improved Supply Chain with >10x Query Performance and 90% Faster Project Delivery
Dremio's data lakehouse helped Amazon achieve 10x faster query performance and reduce project completion times by 90%.
Learn more

Case Study
Improved Manufacturing Equipment Productivity and Lowered Costs
Improved Equipment Effectiveness by >10% across 250 manufacturing lines. Query price performance was 30x better, which resulted in significant...
Learn more

Case Study
Improved Project Delivery Speed and Lowered Costs.
Dremio's data lakehouse helps NCR complete analytics projects 90% faster and delivers >10x price performance.
Learn more