
Apache Iceberg is a data lakehouse table format revolutionizing the data industry with unique features such as advanced partitioning, ACID guarantees, schema evolution, time travel, and more. Central to the functionality of Apache Iceberg tables is their catalog mechanism, which plays a crucial role in the evolution of how these tables are used and their features are developed. In this article, we will take a deep dive into the topic of Apache Iceberg catalogs.
The Purpose of Iceberg Catalogs
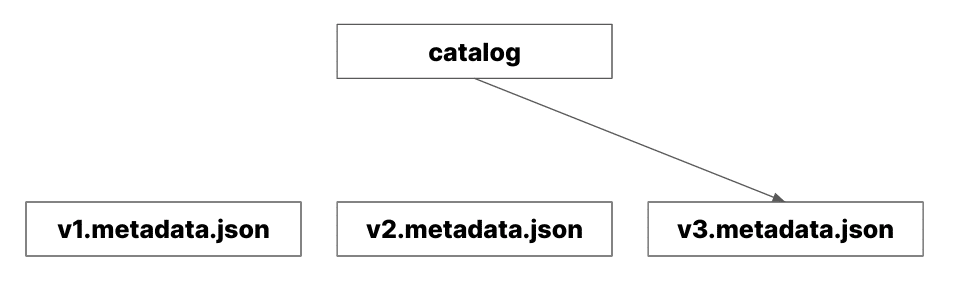
Apache Iceberg utilizes a top-level metadata file known as metadata.json, which provides a query engine with essential information such as the schema, snapshot history, and partitioning history of a table. Whenever an Apache Iceberg table changes, a new metadata.json file is generated, accumulating numerous versions (e.g., v1.metadata.json, v2.metadata.json) in your data lake. Although these excess files are routinely cleaned up during cleanup operations, the challenge remains: how do query engines like Dremio, Snowflake, and Apache Spark determine which file is the "current" metadata.json? This is where the catalog plays a crucial role. The catalog is responsible for two key functions:
- Maintaining a list of the existing Iceberg tables.
- Keeping a reference to the "current" metadata.json.
By fulfilling these responsibilities, the catalog ensures that multiple query engines can access the same table and retrieve a consistent data version, acting as the source of truth.
Types of Iceberg Catalogs
Apache Iceberg catalogs can be broadly classified into two categories: file-based catalogs and service-based catalogs. File-based catalogs use files to maintain these references, while service-based catalogs rely on a running service to track them.
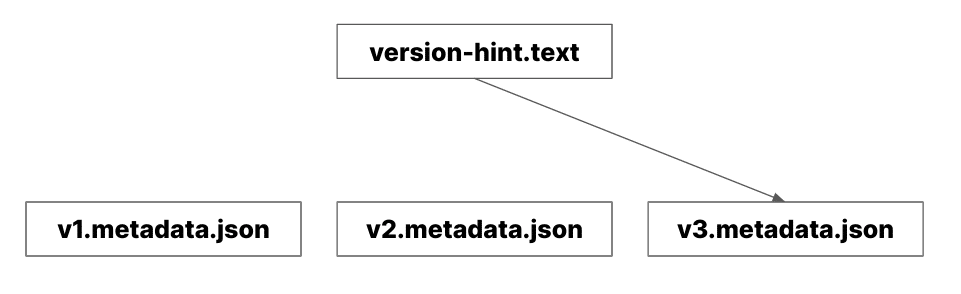
In the realm of file-based catalogs, there is a single catalog named the "Hadoop Catalog." Despite its name, it operates on any file system, whether Hadoop or object storage. This catalog maintains the reference to the latest metadata.json in a file named version-hint.text. When a query engine accesses a directory containing an Iceberg table, it checks for this file to locate the correct metadata.json. While this method is functional, it is generally not recommended for production environments, especially in scenarios with multiple writers to the tables, due to potential consistency issues across different storage systems (not all storage layers have the same file update guarantees).
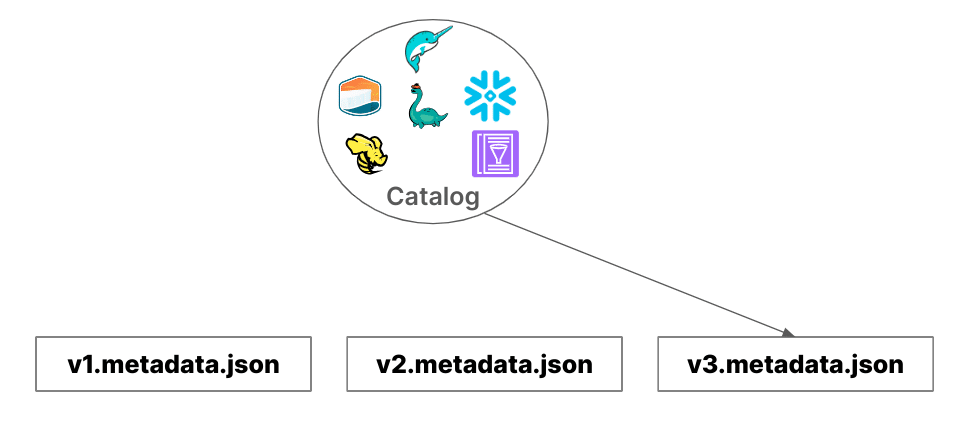
Conversely, service-based catalogs utilize a running service or server. A query engine sends requests to this service, which then provides the address of the metadata.json. These catalogs often develop their own locking mechanisms or leverage those of a backing database, enhancing their suitability for production use. Examples of service-based catalog implementations include JDBC, Hive, Glue, and Nessie.
The Challenges
Initially, Apache Iceberg offered only one API, the Java API. Consequently, catalogs were developed using a base class as a template for those creating custom catalogs. This catalog class handled most of the logic of requesting metadata and then planning which files to scan from that metadata on the client side. Thus, how a query engine interacted with a catalog depended not only on the catalog class used but also on the version of that class.
package org.apache.iceberg.catalog;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import java.util.function.Function;
import org.apache.iceberg.Schema;
import org.apache.iceberg.Table;
import org.apache.iceberg.exceptions.NamespaceNotEmptyException;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableSet;
public abstract class BaseSessionCatalog implements SessionCatalog {
private final Cache<String, Catalog> catalogs =
Caffeine.newBuilder().expireAfterAccess(10, TimeUnit.MINUTES).build();
private String name = null;
private Map<String, String> properties = null;
@Override
public void initialize(String catalogName, Map<String, String> props) {
this.name = catalogName;
this.properties = props;
}
@Override
public String name() {
return name;
}
@Override
public Map<String, String> properties() {
return properties;
}
public Catalog asCatalog(SessionContext context) {
return catalogs.get(context.sessionId(), id -> new AsCatalog(context));
}
public <T> T withContext(SessionContext context, Function<Catalog, T> task) {
return task.apply(asCatalog(context));
}
public class AsCatalog implements Catalog, SupportsNamespaces {
private final SessionContext context;
private AsCatalog(SessionContext context) {
this.context = context;
}
@Override
public String name() {
return BaseSessionCatalog.this.name();
}
@Override
public List<TableIdentifier> listTables(Namespace namespace) {
return BaseSessionCatalog.this.listTables(context, namespace);
}
@Override
public TableBuilder buildTable(TableIdentifier ident, Schema schema) {
return BaseSessionCatalog.this.buildTable(context, ident, schema);
}
@Override
public Table registerTable(TableIdentifier ident, String metadataFileLocation) {
return BaseSessionCatalog.this.registerTable(context, ident, metadataFileLocation);
}
@Override
public boolean tableExists(TableIdentifier ident) {
return BaseSessionCatalog.this.tableExists(context, ident);
}
@Override
public Table loadTable(TableIdentifier ident) {
return BaseSessionCatalog.this.loadTable(context, ident);
}
@Override
public boolean dropTable(TableIdentifier ident) {
return BaseSessionCatalog.this.dropTable(context, ident);
}
@Override
public boolean dropTable(TableIdentifier ident, boolean purge) {
if (purge) {
return BaseSessionCatalog.this.purgeTable(context, ident);
} else {
return BaseSessionCatalog.this.dropTable(context, ident);
}
}
@Override
public void renameTable(TableIdentifier from, TableIdentifier to) {
BaseSessionCatalog.this.renameTable(context, from, to);
}
@Override
public void invalidateTable(TableIdentifier ident) {
BaseSessionCatalog.this.invalidateTable(context, ident);
}
@Override
public void createNamespace(Namespace namespace, Map<String, String> metadata) {
BaseSessionCatalog.this.createNamespace(context, namespace, metadata);
}
@Override
public List<Namespace> listNamespaces(Namespace namespace) {
return BaseSessionCatalog.this.listNamespaces(context, namespace);
}
@Override
public Map<String, String> loadNamespaceMetadata(Namespace namespace) {
return BaseSessionCatalog.this.loadNamespaceMetadata(context, namespace);
}
@Override
public boolean dropNamespace(Namespace namespace) throws NamespaceNotEmptyException {
return BaseSessionCatalog.this.dropNamespace(context, namespace);
}
@Override
public boolean setProperties(Namespace namespace, Map<String, String> updates) {
return BaseSessionCatalog.this.updateNamespaceMetadata(
context, namespace, updates, ImmutableSet.of());
}
@Override
public boolean removeProperties(Namespace namespace, Set<String> removals) {
return BaseSessionCatalog.this.updateNamespaceMetadata(
context, namespace, ImmutableMap.of(), removals);
}
@Override
public boolean namespaceExists(Namespace namespace) {
return BaseSessionCatalog.this.namespaceExists(context, namespace);
}
}
}As Apache Iceberg grew, APIs in other languages, including Python, Rust, and Go, were introduced. Under the existing framework, client classes for each catalog had to be rebuilt for every language, which proved cumbersome. Several problems began to emerge:
- The challenge of reimplementing each catalog for each language API.
- The significant amount of logic encapsulated in the client exacerbated this difficulty.
- Difficulty in controlling which version of the catalog class users were utilizing, often leading to issues due to outdated versions unknowingly being used.
To address these issues, a new approach was developed to streamline the process and open up new possibilities.
The REST Catalog Specification
The new approach, termed the "REST catalog," was designed to establish a standard to eliminate the need for multiple catalog implementations across different languages. This standardization is achieved by creating an OpenAPI specification outlining the necessary server endpoints for a service catalog. The specific implementation logic can vary as long as a service adheres to this specification—ensuring all required endpoints are present, accept the appropriate inputs, and return the correct outputs. Consequently, any catalog that conforms to this standard does not require a separate catalog class for each language, as the standard "REST Catalog" class suffices.
Here is an example endpoint from the specification:
/v1/{prefix}/namespaces/{namespace}/tables:
parameters:
- $ref: '#/components/parameters/prefix'
- $ref: '#/components/parameters/namespace'
get:
tags:
- Catalog API
summary: List all table identifiers underneath a given namespace
description: Return all table identifiers under this namespace
operationId: listTables
parameters:
- $ref: '#/components/parameters/page-token'
- $ref: '#/components/parameters/page-size'
responses:
200:
$ref: '#/components/responses/ListTablesResponse'
400:
$ref: '#/components/responses/BadRequestErrorResponse'
401:
$ref: '#/components/responses/UnauthorizedResponse'
403:
$ref: '#/components/responses/ForbiddenResponse'
404:
description: Not Found - The namespace specified does not exist
content:
application/json:
schema:
$ref: '#/components/schemas/IcebergErrorResponse'
examples:
NamespaceNotFound:
$ref: '#/components/examples/NoSuchNamespaceError'
419:
$ref: '#/components/responses/AuthenticationTimeoutResponse'
503:
$ref: '#/components/responses/ServiceUnavailableResponse'
5XX:
$ref: '#/components/responses/ServerErrorResponse'
post:
tags:
- Catalog API
summary: Create a table in the given namespace
description:
Create a table or start a create transaction, like atomic CTAS.
If `stage-create` is false, the table is created immediately.
If `stage-create` is true, the table is not created, but table metadata is initialized and returned.
The service should prepare as needed for a commit to the table commit endpoint to complete the create
transaction. The client uses the returned metadata to begin a transaction. To commit the transaction,
the client sends all create and subsequent changes to the table commit route. Changes from the table
create operation include changes like AddSchemaUpdate and SetCurrentSchemaUpdate that set the initial
table state.
operationId: createTable
parameters:
- $ref: '#/components/parameters/data-access'
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTableRequest'
responses:
200:
$ref: '#/components/responses/CreateTableResponse'
400:
$ref: '#/components/responses/BadRequestErrorResponse'
401:
$ref: '#/components/responses/UnauthorizedResponse'
403:
$ref: '#/components/responses/ForbiddenResponse'
404:
description: Not Found - The namespace specified does not exist
content:
application/json:
schema:
$ref: '#/components/schemas/IcebergErrorResponse'
examples:
NamespaceNotFound:
$ref: '#/components/examples/NoSuchNamespaceError'
409:
description: Conflict - The table already exists
content:
application/json:
schema:
$ref: '#/components/schemas/IcebergErrorResponse'
examples:
NamespaceAlreadyExists:
$ref: '#/components/examples/TableAlreadyExistsError'
419:
$ref: '#/components/responses/AuthenticationTimeoutResponse'
503:
$ref: '#/components/responses/ServiceUnavailableResponse'
5XX:
$ref: '#/components/responses/ServerErrorResponse'This approach offers several advantages:
- Developers who create a conforming catalog service can immediately utilize it across most Apache Iceberg-compatible tools.
- Conforming catalog implementations can be built in any language and work with all clients in any language
- Operations are handled based on the server and not the client, allowing updates to be handled centrally in the catalog.
- Tools compatible with Apache Iceberg can more easily support a broader range of catalogs, including custom in-house catalogs developed by some institutions. This flexibility is particularly beneficial, as many tools might be reluctant to create custom connectors for each unique catalog.
The Future of REST Catalog Specification
The REST Catalog is currently supported by Tabular, Unity Catalog, and Gravitino, Polaris and Nessie. However, like any technology, it is not without its imperfections. There are numerous proposals aimed at evolving the REST specification to enable the server to handle more tasks, which would allow for optimizations and reduce the workload on the client.
The REST Catalog remains an exciting area for future developments in the Apache Iceberg table format. For those interested in getting hands-on experience with Apache Iceberg, consider exploring one of the many tutorials below.
- Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
- From SQLServer -> Apache Iceberg -> BI Dashboard
- From MongoDB -> Apache Iceberg -> BI Dashboard
- From Postgres -> Apache Iceberg -> BI Dashboard
- From MySQL -> Apache Iceberg -> BI Dashboard
- From Elasticsearch -> Apache Iceberg -> BI Dashboard
- From Apache Druid -> Apache Iceberg -> BI Dashboard
- From JSON/CSV/Parquet -> Apache Iceberg -> BI Dashboard
- From Kafka -> Apache Iceberg -> Dremio
Sign up for AI Ready Data content
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->