Today, we’re excited to announce our Dremio August 2021 (18.0) release!
This month’s release introduces major enhancements across the platform, including near real-time data freshness and infinite scale to SQL lakehousing, support for querying Apache Iceberg tables, a brand-new system observability interface, and extensions to our user security model.
Near Real-Time Data Freshness and Infinite Scale for the SQL Lakehouse
Dremio was built from the ground up to support high-performing BI dashboards and interactive analytics. Some of the world’s largest companies already use Dremio in production to power BI workloads directly on data lake storage, thanks to various innovations like our Columnar Cloud Cache (C3) and data reflections.
Dremio’s ability to efficiently compute, store, and leverage metadata also plays a major role in enabling interactive performance on data lake storage. While older query engines are limited by their requirement to perform all necessary processes for query execution at runtime, from metadata collection, query planning, and beyond*, Dremio gathers and caches metadata required for queries upfront, which drastically reduces the amount of computation required at runtime before a query can start to fully execute and return queries to a client. To push the boundaries of what’s possible in the SQL lakehouse even further and deliver the best BI experience possible for our customers, we saw a big opportunity in taking our metadata processes to the next level.
Over the past many months, we’ve rethought the way metadata is computed and stored within Dremio. Put simply, we’ve refactored metadata processing to become a parallel, executor-based process, with metadata now stored and managed in Iceberg tables on data lake storage. Parallelizing metadata processing across executors and leveraging capabilities and best practices from Iceberg makes all metadata operations much faster and more scalable, and in turn gives rise to a variety of benefits for users.
With this release, Dremio now provides near real-time metadata refresh for datasets, eliminates metadata refresh for data reflections altogether, and supports tables of unlimited size. These enhancements ensure users are leveraging the most current or near real-time version of data, and receive timely visibility into recent schema and data changes. In addition, there are no limits to how large their tables can be, and there are no limits to the amount of data that can be accessed at runtime.
Refactoring metadata processing also introduces new levels of observability and workload management to metadata. Because metadata jobs are now executor-based, users can observe and manage metadata jobs alongside any other jobs running on Dremio. In addition, users can create workload management rules on metadata jobs to ensure they are fully isolated from other concurrent workloads on the system.
The diagrams below illustrate the metadata refresh process prior to this release, and how metadata refresh is performed moving forward:
(Prior to Dremio August 2021 release)
(Dremio August 2021 release and onwards)
These significant enhancements to metadata processing, which bring tremendous impact to our customers across both performance and scale, are the culmination of nearly a year of engineering effort. This is a major enhancement to our platform, so we’ll be writing a more detailed technical blog about this work in the near future.
*Performing metadata processes on an ad hoc basis, starting from scratch every time a query is run, drastically slows down the data analysis process and prevents BI users from achieving the performance their workloads demand. In a real-life example, Ryan Blue, the creator of Iceberg, shared frustrations with Hive at Netflix, where it would take over 9 minutes just to plan a query due to Hive’s requirement to perform directory listings needed for large tables at runtime.
Workload Management for Reflection Refresh Jobs
Data Reflections are one of Dremio’s query acceleration technologies that enables interactive BI performance directly on data lake storage. Reflections intelligently precompute aggregations, sorts, and other data operations to minimize computation required at query runtime.
To ensure data freshness, reflections are refreshed periodically on a user-defined schedule or manually via an API call, and may combine data across multiple physical and virtual datasets. Reflection refresh jobs consume compute resources, so users often leverage Dremio’s workload management rules to route reflection refresh jobs to queues or engines dedicated to reflection refresh.
With this release, companies can now route reflection refresh jobs to different queues/engines based on the dataset. This additional granularity provides greater workload isolation by ensuring reflection refresh jobs for specific teams within an organization are routed to queues designated for respective teams.
Users can run a simple SQL command to route reflection operations to a specific queue or engine:
ALTER DATASET <path>.<dataset_name> ROUTE [ALL] REFLECTIONS TO
< DEFAULT QUEUE, QUEUE [queue_name or queue_uuid] >
For Dremio Cloud users, the syntax is as follows:
ALTER DATASET <path>.<dataset_name> ROUTE [ALL] REFLECTIONS TO
< DEFAULT ENGINE, ENGINE [engine_name or engine_uuid] >
The ability to route reflection refresh jobs at the dataset level is especially useful for anyone using Dremio as a multitenant platform to support multiple workloads across their organization. This also ensures reflections for one team that require fast refresh aren’t blocked by reflection refresh jobs from other teams using the platform.
As an example, suppose a company has two teams using Dremio: a sales team and a marketing team. Suppose each of these teams has their own Dremio space, where all of their respective datasets reside. With this release, the company can run the following SQL commands to route each team’s reflection refresh jobs to dedicated queues and ensure workload isolation:
ALTER DATASET Sales.SalesNYC ROUTE REFLECTIONS TO
QUEUE "Sales-Reflections"
ALTER DATASET Marketing.WebTraffic ROUTE REFLECTIONS TO
QUEUE "Marketing-Reflections"
The company can also restore default queue allocation behavior for reflection refresh jobs on a given dataset with a similar command:
ALTER DATASET Sales.SalesNYC ROUTE REFLECTIONS TO DEFAULT QUEUE
Queue routing for reflection refresh jobs can be set for both physical and virtual datasets (views). In addition, queue routing rules are resilient to queue name changes as Dremio internally registers queues by ID.
Reflection routing is currently supported in Dremio Enterprise Edition and Dremio Cloud.
Apache Iceberg Support
Apache Iceberg is an open source table format for analytic datasets. Iceberg enables multiple applications to work together on the same data in a transactionally consistent manner, and defines additional information on the state of datasets as they evolve and change over time.
The Iceberg table format has similar capabilities and functionality as SQL tables in traditional databases, but in a fully open and accessible manner such that multiple engines (Dremio, Spark, etc.) can operate on the same dataset. Iceberg provides many features such as:
- Transactional consistency between multiple applications where files can be added, removed or modified atomically, with full read isolation and multiple concurrent writes
- Full schema evolution to track changes to a table over time
- Partition layout and evolution enabling updates to partition schemes as queries and data volumes change without relying on hidden partitions or physical directories
- Time travel to query historical data and verify changes between updates
- Rollback to prior versions to quickly correct issues and return tables to a known good state
- Advanced planning and filtering capabilities for high performance on large data volumes
Iceberg achieves these capabilities for a table via metadata files (aka manifests) tracked through point-in-time snapshots by maintaining all deltas as a table is updated over time. Each snapshot provides a complete description of the table’s schema, partition and file information and offers full isolation and consistency. Additionally, Iceberg intelligently organizes snapshot metadata in a hierarchical structure. This enables fast and efficient changes to tables without redefining all dataset files, thus ensuring optimal performance when working at data lake scale.
With this month’s release, Dremio supports analyzing Iceberg datasets through a native, high-performance reader. Dremio automatically identifies which datasets are saved in the Iceberg format, and utilizes the table information from Iceberg manifest files.
Iceberg support is currently in preview. Analyzing Iceberg tables is currently supported for Azure Storage/ADLS, and will soon be supported for Hive Metastore catalogs as well.
To learn more about Iceberg, check out our technical deep-dive “Apache Iceberg: An Architectural Look Under the Covers”
User/Role Synchronization with Identity Providers via SCIM
Dremio’s security model allows companies to easily leverage existing roles and users configured in an enterprise identity provider like Azure Active Directory. However, companies may also want to configure identities within Dremio, separate from their corporate identity provider, for Dremio-specific use cases. For example, a company may want to create an identity within Dremio for automation tasks.
With this release, companies can now simultaneously manage identities within their corporate identity provider as well as identities defined within Dremio:
- Externally-managed identities: Companies can configure their corporate identity provider (IdP) to automatically synchronize external users, roles, and role memberships with Dremio using SCIM, the industry standard protocol for managing identities across cloud-based applications. With SCIM, IdPs automatically push any changes to IdP-managed users and groups to Dremio, and Dremio reflects these changes in near real-time. For example, if you have Okta set up as your corporate IdP with Dremio and make a change to that Okta user, the change will be reflected in Dremio automatically.
- Dremio-managed identities: Companies can configure and manage identities and role memberships within Dremio through standard SQL syntax. This extension to Dremio’s security model enables Dremio-specific customizations, including managing Dremio-specific users, and also supports group memberships unique to Dremio use cases.
Users can utilize SQL, a REST API, or the Dremio UI to manage local users and roles. For example, a user can use the following SQL to create roles and users local to Dremio, and assign users to these roles:
CREATE ROLE manager
CREATE ROLE sales
CREATE USER alice
CREATE USER bob
CREATE USER charlie
GRANT ROLE manager TO USER alice
GRANT ROLE sales TO USER bob
A screenshot of the user management UI is also shown below:
Dremio uses a local, Dremio-managed username and password to authenticate local users. In contrast, an externally-managed user authenticates against their respective external system.
For more information on role-based access control, including user/role synchronization with a corporate identity provider through SCIM as well as Dremio-configured roles, check out the Dremio docs.
Brand-New System Observability Interface
We want to make it as easy as possible for users to understand what’s happening within Dremio, so they can optimize their query performance and deliver the best BI experience for their companies.
Since we launched Dremio, the Dremio console has provided an overall view of all the jobs happening on the system, as well as views containing various details for each individual job (such as query profile, breakdown of execution time, and reflections considered and used).
With this release, we’re pleased to announce a brand-new interface for our jobs pages that broadens overall system observability while providing a much deeper view into performance metrics for individual queries. Specifically, this release delivers three key experiences for our Jobs UI.
First, we’ve revitalized our top-level Jobs page, which displays everything that’s happening in Dremio at a broader scale. We’ve embedded much more information on this initial view to maximize visibility into system utilization, and provide insight into top queries by a variety of metrics. In addition, we’ve embedded sleek interactions as part of the new experience that reveal additional system information for applicable metrics.
For example, in the screenshot below of the top-level Jobs page, hovering over the “Duration” column provides a breakdown of query execution time by phase:
In addition, you can customize this page by sorting columns and only displaying the columns that are most important to you:
With this release, we’ve also refined our individual query details page, which provides detailed visibility into performance, resource consumption, and acceleration details for an individual query. If you click into a specific query, we now provide an overview that displays all essential details about an individual query, including scans (and associated details including I/O and rows read by underlying source file), reflections used and considered, and breakdown of execution time:
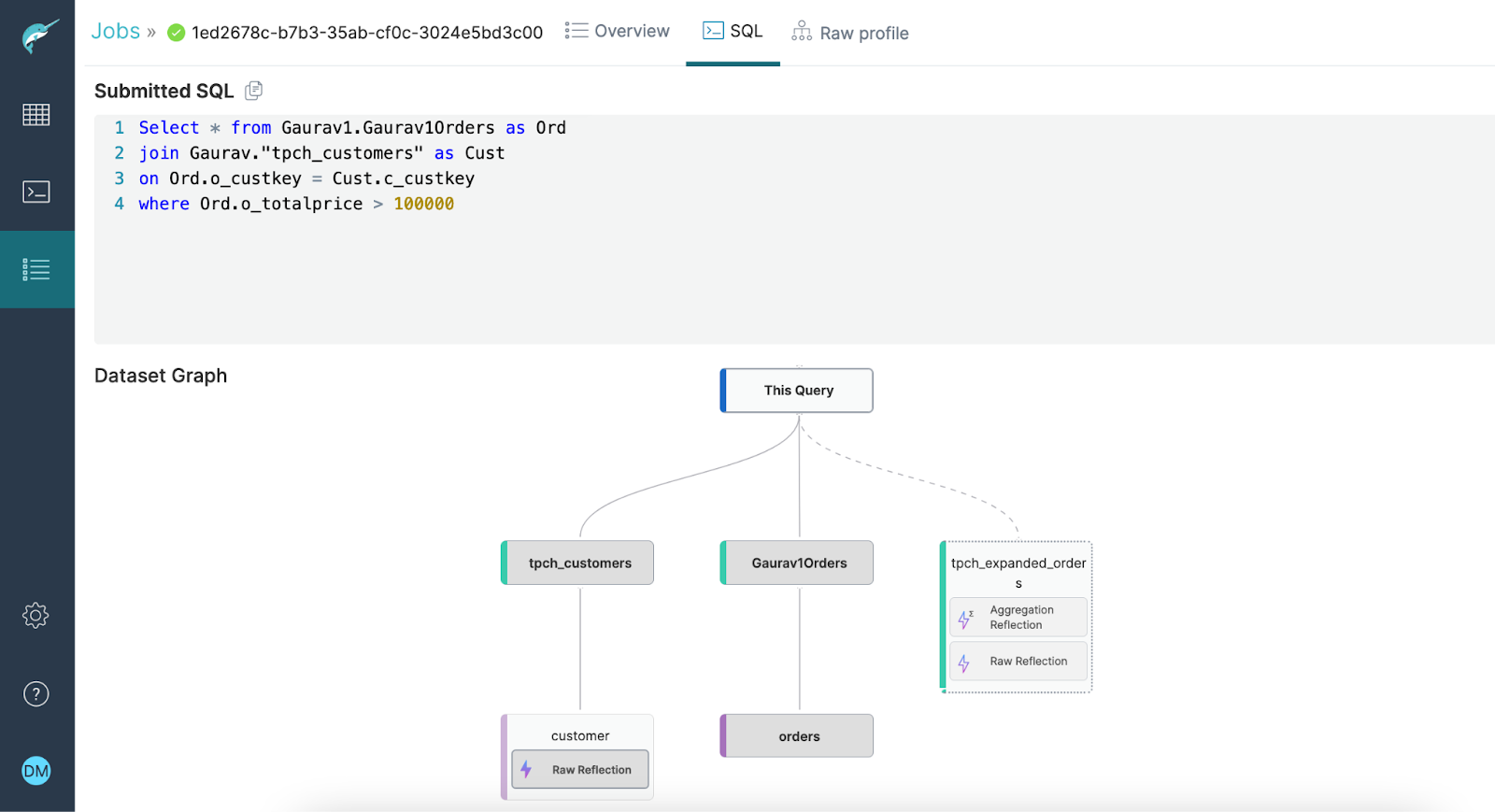
Aside from surfacing this top-level information about a particular query, unpacking where data for a query was derived from is important in understanding query performance. With this release, users can click into the SQL tab within the individual query view to see the dataset graph for their query, highlighting not only the tables and views referenced directly by the query, but also their ancestors.
With this major overhaul of our Jobs experience, we’re greatly enriching system observability and in turn empowering data engineers to deliver best-in-class BI experiences for their companies.
Learn More
We’re excited about the features and improvements we’ve made this month! For a complete list of additional new features, enhancements, changes, and fixes, check out the Release Notes. And, as always, we look forward to your feedback — please post any questions or comments on the Dremio Community!
P.S. — we just announced limited availability of Dremio Cloud, our fully-managed SQL lakehouse platform! We’d love to have you be a part of this journey. Join our limited availability program today for free!
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.