10 minute read · April 3, 2023
Using DuckDB with Your Dremio Data Lakehouse
· Head of DevRel, Dremio
Storage, compute, and regulatory costs can really add up when it comes to working with and managing your data. In traditional proprietary data warehouses, you must store your data in proprietary formats, organized in proprietary catalogs, to be queried with a proprietary engine. The result is vendor lock-in which over time, allows vendors to price the product in a way that results in runaway storage and compute costs.
Moreover, storage costs are magnified as you create data marts for all your business lines and make physical copies of your data. Unfortunately, this strategy doesn’t get the performance you need for BI dashboard and ad hoc analytics, leading to local BI extracts and copies that result in consistency and regulatory issues. Regulatory fines for sensitive data floating around in data copies adds further insult to injury.
So what is the solution to address vendor lock-in, runaway copies, and the overall costs of a traditional data architecture? An open data lakehouse creates an architecture that allows you to execute those same data warehouse workloads on your data lake at a lower cost in an open playing field.
In this article, we will discuss how you can use technologies like Dremio and DuckDB to create a low-cost, high-performance data lakehouse environment accessible to all your users.
What Is Dremio?
Dremio is an easy, open, and fast lakehouse platform:
- Easy: Dremio’s easy UI allows you to connect all your data sources to document, and organize and govern them through Dremio’s semantic layer, creating an easy-to-use central access point for all your data.
- Open: Dremio is an open platform built on technologies like Apache Arrow and Apache Iceberg. Dremio allows you to connect any data source and distribute it to any consumer through REST, JDBC/ODBC, and Apache Arrow Flight interface. Dremio also has integrations with tools like Tableau and Power BI, making dashboard creation on your lake easy.
- Fast: Dremio leverages the Apache Arrow in-memory format for blazing-fast data processing and uses unlimited concurrency, Dremio’s columnar cloud cache, and data reflections technology to optimize query performance.
Dremio is a powerful tool to unite, accelerate, and distribute data; the best way to try it is with the Dremio Test Drive.
What Is DuckDB?
You’ve probably heard of DuckDB’s ever-growing popular in-process columnar database. The beauty of DuckDB is that it enables your local hardware to process large amounts of data locally at high speeds. DuckDB allows you to run ad hoc analytics right from your laptop, avoiding the cost of cloud computing for these workloads by offloading them to your laptop.
However, there are limits to your local hardware memory and processing for big data at scale, so you need massively parallel processing systems like Dremio to get the 100GB you need out of a 10TB dataset which you can drill deeper into into locally with DuckDB. Dremio provides the additional benefit of being a data unification and governance layer, so users don’t have to think about governance or different connectors. If it connects to Dremio, they can pull it into DuckDB with the appropriate authorization.
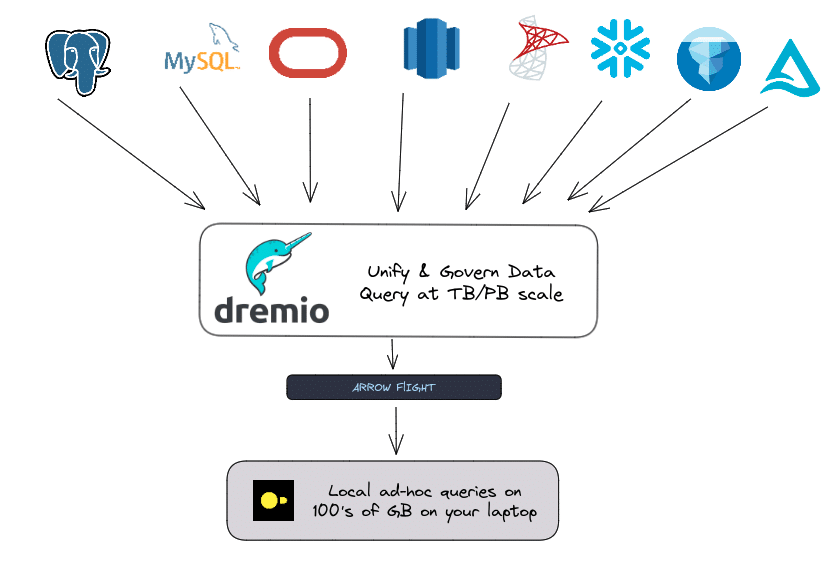
How to Use DuckDB with Dremio
Using Dremio out of the box with DuckDB is pretty simple. You can pull down from Dremio using Apache Arrow Flight with pyArrow, then convert the StreamReader into a table, and then into an Arrow dataset which can be used to create a DuckDB relation. Let’s walk through an example that allows you to locally run ad hoc analysis on first-quarter employee pay per shift.
In this example, we use pyArrow and DuckDB, pulling our Dremio access token from our environment variables. We create an Arrow Flight client and make a function we can use to execute queries. That function will return a FlightStreamReader which can be converted into a table and then into an Arrow dataset which can be passed to the DuckDB Arrow function, returning a DuckDB relation that we can use to run additional queries locally.
The Dremio query joins an Iceberg table from a Dremio Arctic Catalog, a Snowflake table, and a Delta Lake table; all three data sources in other tools may not be easy to work together, but for Dremio it is no problem. We query the data and pull down a subset representing the first quarter of employee pay per shift. With the result of the Dremio query now in a DuckDB relation, we can run ad hoc analysis on the quarter from our local machine, like a query adding up an employee's pay for the quarter.
#----------------------------------
# IMPORTS
#----------------------------------
## Import Pyarrow
from pyarrow import flight
from pyarrow.flight import FlightClient
import pyarrow.dataset as ds
## import duckdb
import duckdb
## Get environment variables
from os import environ
const token = environ.get('token', 'no personal token defined')
#----------------------------------
# Setup
#----------------------------------
## Headers for Authentication
headers = [
(b"authorization", f"bearer {token}".encode("utf-8"))
]
## Create Client
client = FlightClient(location=("grpc+tls://data.dremio.cloud:443"))
#----------------------------------
# Function Definitions
#----------------------------------
## makeQuery function
def make_query(query, client, headers):
## Get Schema Description and build headers
flight_desc = flight.FlightDescriptor.for_command(query)
options = flight.FlightCallOptions(headers=headers)
schema = client.get_schema(flight_desc, options)
## Get ticket to for query execution, used to get results
flight_info = client.get_flight_info(flight.FlightDescriptor.for_command(query), options)
## Get Results
results = client.do_get(flight_info.endpoints[0].ticket, options)
return results
#----------------------------------
# Run Query
#----------------------------------
## Query Dremio, get back Arrow FlightStreamReader
results = make_query(
"""
SELECT employee.name, payrates.rate * shifts.hours AS gross_pay, shifts.date_ts
FROM arctic.employee employee
INNER JOIN snowflake.payrates payrates
ON employee.payrate_id = payrates.id
INNER JOIN s3.deltalaketable.shifts shifts
ON shifts.employee_id = employee.id
ORDER BY employee.name ASC
WHERE shifts.date_ts BETWEEN '2023-01-01 01:00:00' and '2023-03-31 01:00:00';
"""
, client, headers)
## Convert StreamReader into an Arrow Table
table = results.read_all()
## Convert Arrow Table into Arrow Dataset
my_ds = ds.dataset(source=[table])
## Convert Arrow Dataset into a DuckDB Relation
my_duck_relation = duckdb.arrow(my_ds)
## run a query from DuckDB
duck_query_results = my_duck_relation.query("table1", "SELECT name, SUM(gross_pay) FROM table1 WHERE name = 'Alex Merced' GROUP BY name;").fetchall()
While this isn’t too bad, why not make this even simpler? So I created a library on Pypi called dremio-simple-query that simplifies the process:
from dremio_simple_query.connect import DremioConnection
from os import getenv
from dotenv import load_dotenv
## Load Environment Variables
load_dotenv()
## Dremio Person Token
token = getenv("TOKEN")
## Arrow Endpoint (See Dremio Documentation)
uri = getenv("ARROW_ENDPOINT")
## Create Dremio Arrow Connection
dremio = DremioConnection(token, uri)
## Query Dremio, get back DuckDB Relation
duck_rel = dremio.toDuckDB(
"""
SELECT employee.name, payrates.rate * shifts.hours AS gross_pay, shifts.date_ts
FROM arctic.employee employee
INNER JOIN snowflake.payrates payrates
ON employee.payrate_id = payrates.id
INNER JOIN s3.deltalaketable.shifts shifts
ON shifts.employee_id = employee.id
ORDER BY employee.name ASC
WHERE shifts.date_ts BETWEEN '2023-01-01 01:00:00' and '2023-03-31 01:00:00';
"""
)
## Run Queries on the Relation
result = duck_rel.query("SELECT name, SUM(gross_pay) FROM table1 WHERE name = 'Alex Merced' GROUP BY name;").fetchall()
## Print Result
print(result)With dremio-simple-query you can also use the Dremio connection object to return the data in Arrow format, then, if you convert it into an Arrow table, it can be directly referenced in DuckDB queries.
from dremio_simple_query.connect import DremioConnection
from os import getenv
from dotenv import load_dotenv
import duckdb
## DuckDB Connection
con = duckdb.connection()
## Load Environment Variables
load_dotenv()
## Dremio Person Token
token = getenv("TOKEN")
## Arrow Endpoint (See Dremio Documentation)
uri = getenv("ARROW_ENDPOINT")
## Create Dremio Arrow Connection
dremio = DremioConnection(token, uri)
## Get Data from Dremio as Arrow StreamReader
stream = dremio.toArrow(
"""
SELECT employee.name, payrates.rate * shifts.hours AS gross_pay, shifts.date_ts
FROM arctic.employee employee
INNER JOIN snowflake.payrates payrates
ON employee.payrate_id = payrates.id
INNER JOIN s3.deltalaketable.shifts shifts
ON shifts.employee_id = employee.id
ORDER BY employee.name ASC
WHERE shifts.date_ts BETWEEN '2023-01-01 01:00:00' and '2023-03-31 01:00:00';
"""
)
## Turn StreamReader into Arrow Table
my_table = stream.read_all()
## Query with Duckdb, just use the variable name
results = con.execute("SELECT name, SUM(gross_pay) FROM my_table WHERE name = 'Alex Merced' GROUP BY name;").fetchall()
print(results)Conclusion
With a well-curated semantic layer, Dremio makes access and discovery of data much easier for analysts to pull the data they need and have permission to access using Apache Arrow Flight. They can then proceed locally for ad hoc queries on the subset of the data they pulled from Dremio. Dremio simplifies how your users interface with your data and helps you save money on cloud compute and storage costs with its architecture. Duckdb complements Dremio and adds to those savings by growing the workloads that can be handled on your local machine.
Sign up for AI Ready Data content
Additional Resources

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->