11 minute read · April 1, 2023
Building Your Data Lakehouse Just Got a Whole Lot Easier with Dremio & Fivetran
· Principal Solutions Architect, Dremio

The data lakehouse has emerged as the next generation of data architecture, combining the best features and capabilities of data warehouses and data lakes into a single unified platform. For years, organizations have been using data lakes and data warehouses in a two-tiered architecture; they need the data lake’s flexibility and scalability in order to meet exponential data growth, but data consumers continue to rely on the data warehouse for enterprise-grade Business Intelligence (BI) and reporting. While data teams continue to make this architecture work, most organizations realize that it cannot continue to scale to meet the current growth of data or the demand from users. The data lakehouse provides a unified architecture that combines the reliability, transactional consistency, and data quality of the data warehouse with the scalability, flexibility, and low cost of the data lake, all at enterprise scale, and with far less effort with regards to management and maintenance than the two-tiered architecture most organizations have in place today.
However, building a data lakehouse can be challenging, particularly when it comes to ensuring data quality, managing metadata, and providing fast and reliable access to data. This is where Apache Iceberg comes in. Apache Iceberg is a table format providing a unified approach to managing and querying data stored in a data lakehouse, and it is a critical component of the architecture. It offers several advantages over traditional data lake table formats, including schema evolution, transaction consistency, and efficient indexing. Most importantly, Apache Iceberg is a truly open-source project, originating out of Netflix, and today it has contributors from organizations all over the world, including many of the largest technology companies who are dedicated to its success and continued evolution.
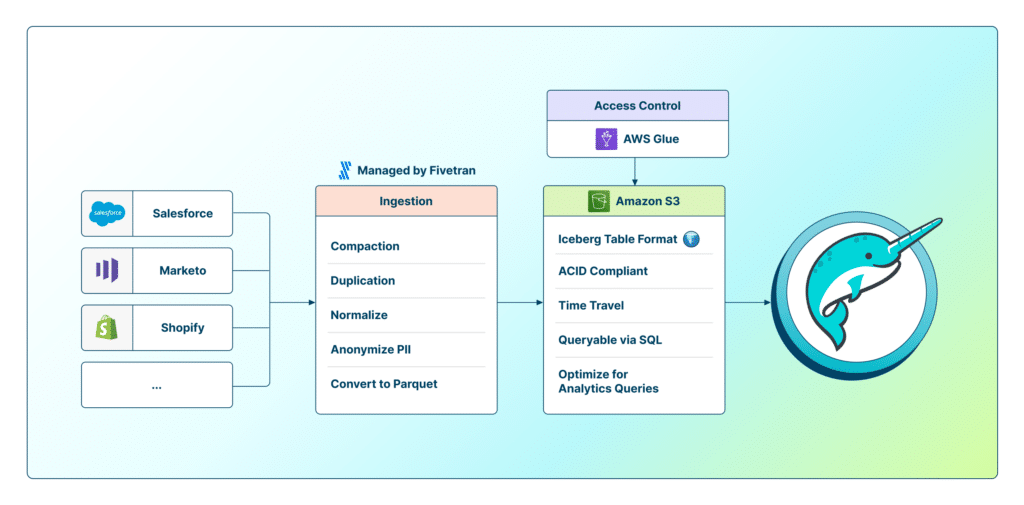
While Apache Iceberg is a critical component to building a data lakehouse, organizations have struggled to get their data into the Iceberg table format inside of the data lakehouse. This is where Fivetran comes in. To help organizations build their data lakehouse in a simple and automated way, Fivetran has developed a new Amazon Simple Storage Service (Amazon S3) destination, enabling users to create connections from their data sources to Amazon S3. The data is written in Iceberg format seamlessly and transparently to the user.
Fivetran’s Amazon S3 destination writes data files in Iceberg format. Then, Fivetran uses AWS Glue indexes the data files and to make them discoverable and queryable by Dremio, providing the transactional consistency, schema evolution, and indexing that are key lakehouse features. With the data now sitting in Iceberg format in Amazon S3, it is easy to use Dremio to create a data connection to your AWS Glue Catalog. Dremio’s integrated support for Iceberg tables enables users to leverage powerful SQL database-like functionality for data lakes. Additionally, Dremio supports time travel and metadata capabilities available in Iceberg tables.
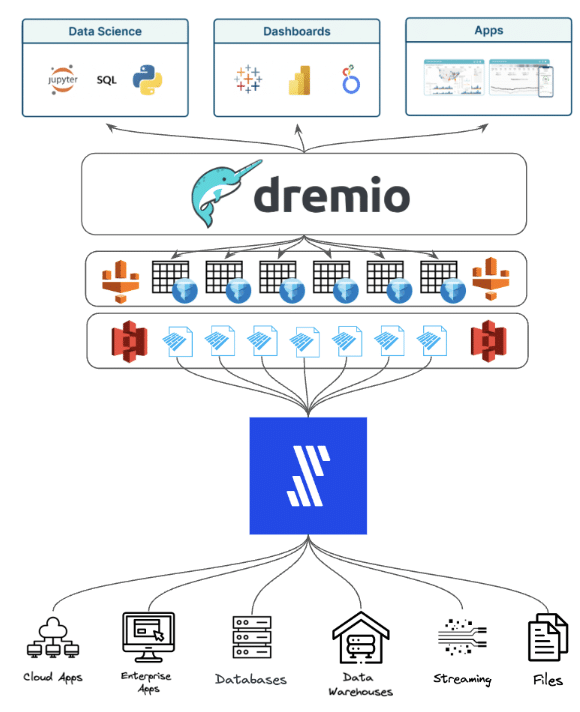
The result for data teams is an effortless and automated approach to building a data lakehouse with Iceberg tables, and making that data accessible to data consumers across the organization.
Let’s walk through how you can get started building your data lakehouse with Fivetran & Dremio.
Build your data lakehouse with Fivetran and Dremio
Step 1: Create your Fivetran Amazon S3 Destination
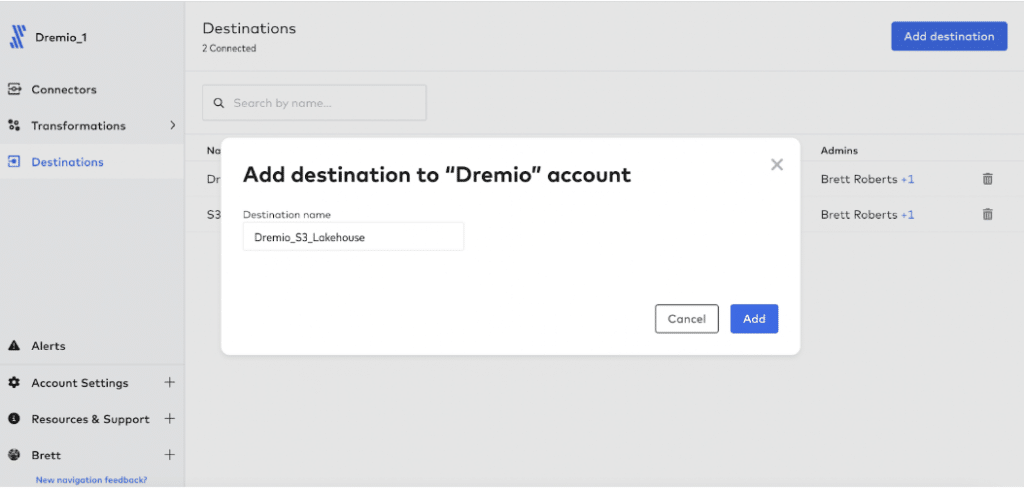
From your Fivetran dashboard, navigate to the Destinations tab, click “Add Destination” and enter a name for your destination.
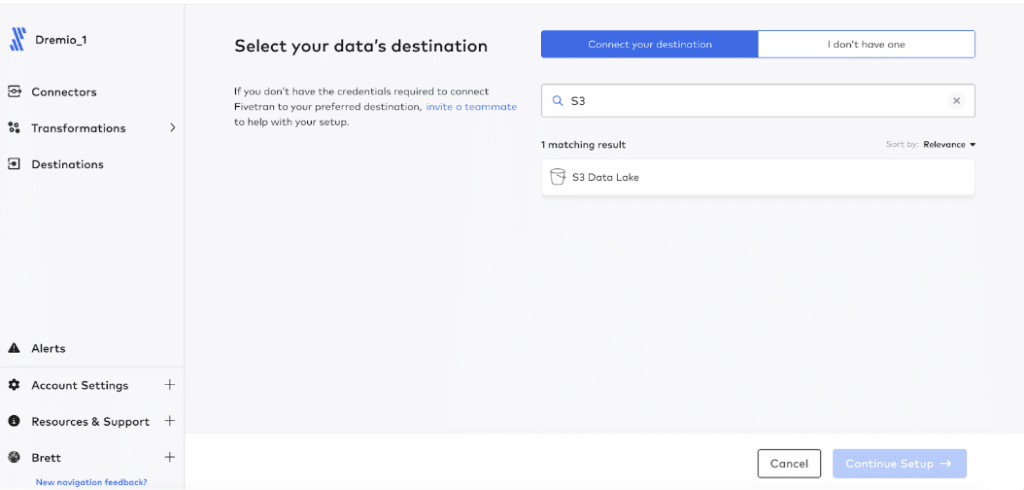
Next, search for “S3” and select “S3 Data Lake” from the destination options and select “Continue Setup.”
Step 2: Setup your Amazon S3 Destination
Using the Fivetran setup guide, fill in the correct AWS account information to set up your S3 destination. To connect your Amazon S3 data lake to Fivetran, you’ll need the following:
- An AWS account that does not have multiple resource groups in the same AWS Region.
- An Amazon S3 bucket in one of the supported AWS Regions. For more information about creating an Amazon S3 bucket, see AWS documentation.
- Access to an AWS Glue Data Catalog in the same Region as the S3 bucket.
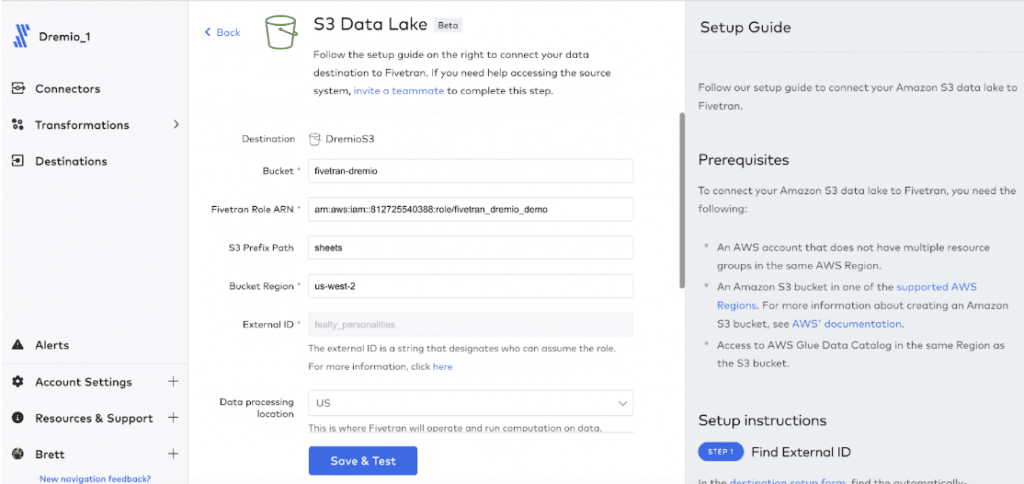
Once you have input the required information, click “Save & Test.” Fivetran will test the connection to AWS S3 & Glue. Once the connection tests have passed, click “View Destination.”
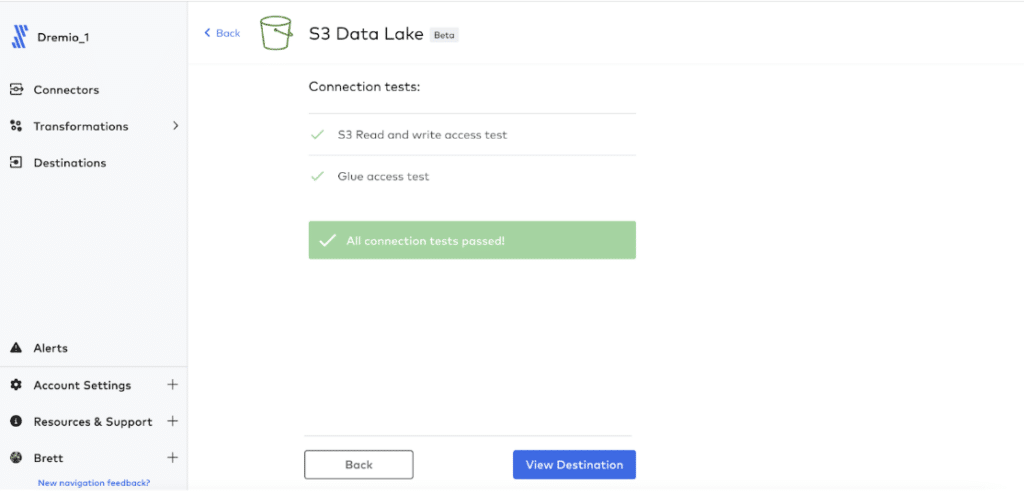
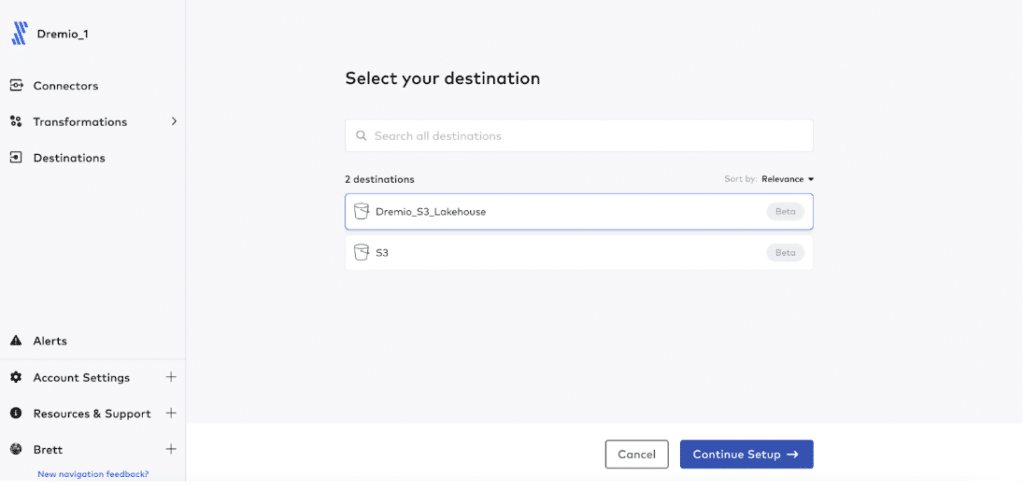
Step 3: Create your Connector
From your Fivetran dashboard, navigate to the Connectors tab and click “Add Connector.” On the next screen, select the destination you just created and click “Continue Setup.”
Select the data source you want to use to send data to your data lakehouse. For the purposes of this blog, we’re going to use Google Sheets. See Fivetran documentation for setup instructions for other data sources.
Search for and select the Google Sheets option, and select “Continue Setup.”
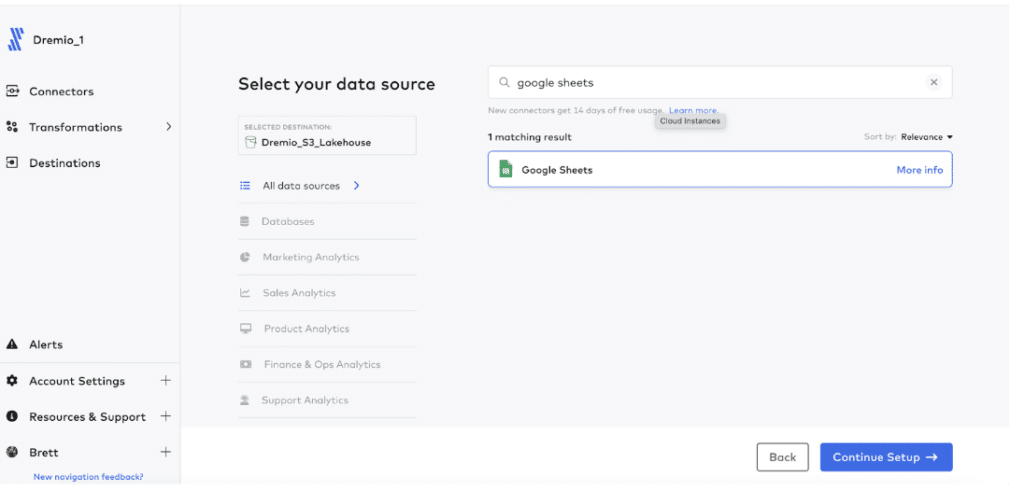
Follow the Fivetran setup guide to connect your data source to Fivetran. Once you’ve filled out the information, click “Save & Test.”
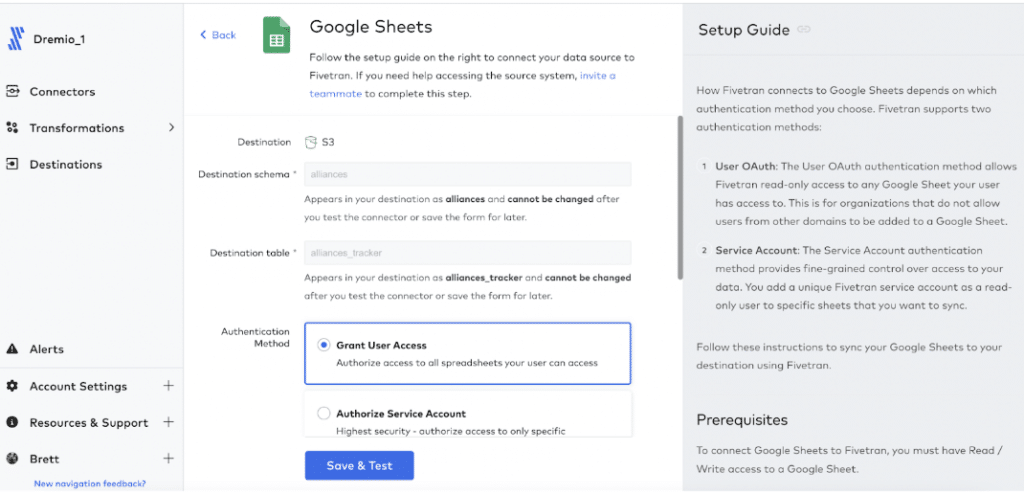
Once the connection has been successfully tested, click “View Connector.”
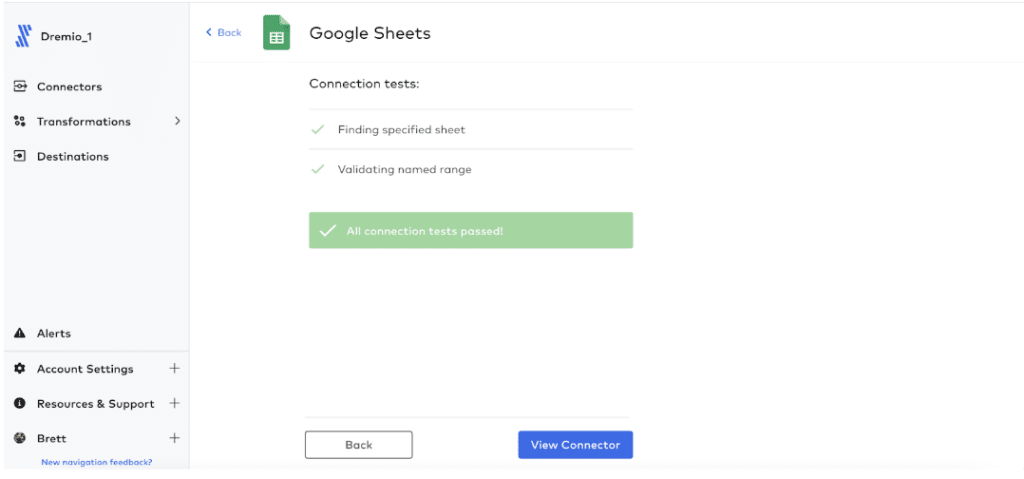
Next, choose if you want to sync all data, or only selected columns, and click “Continue.”
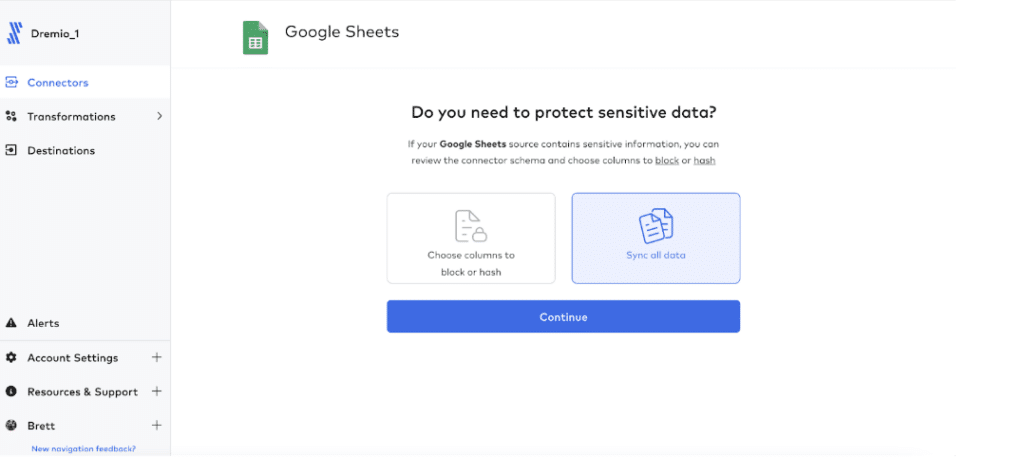
Now you’re ready to start your initial sync. Click “Start Initial Sync” to initiate the connection to the Amazon S3 destination.
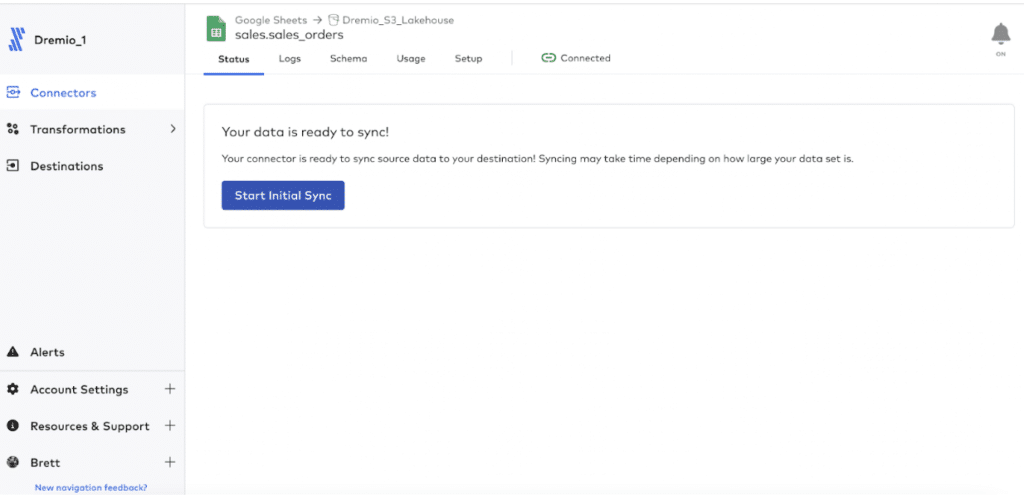
Fivetran will begin to sync your data.
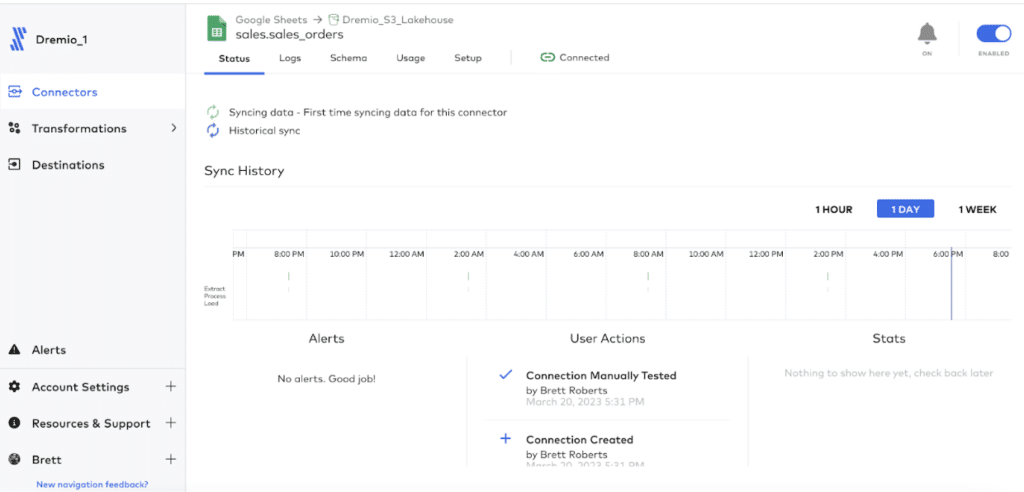
From the Setup tab, you can select the frequency that Fivetran will sync data to AWS.
Step 4: Connect Dremio to your AWS Glue account
From your Dremio homescreen, create a new data connection by clicking “Add Source” located in the bottom left corner, and select “AWS Glue Data Catalog.”
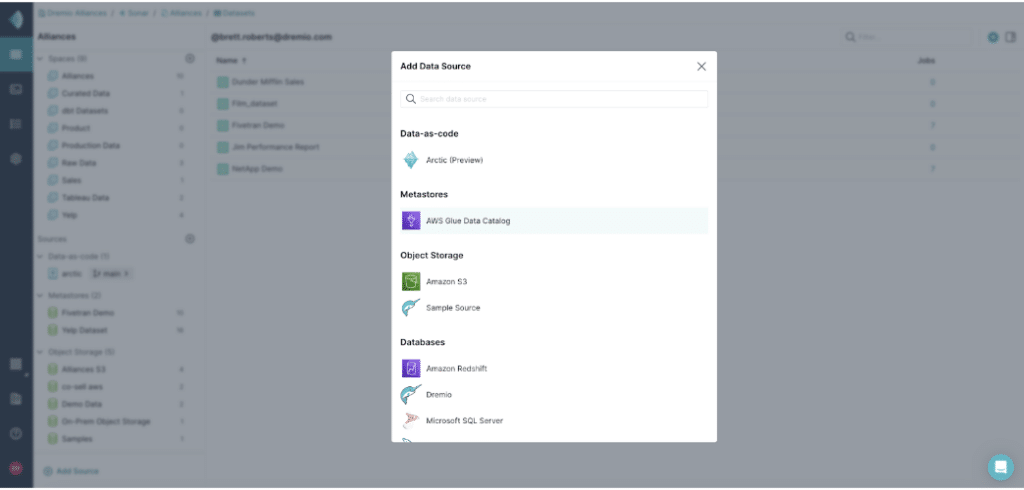
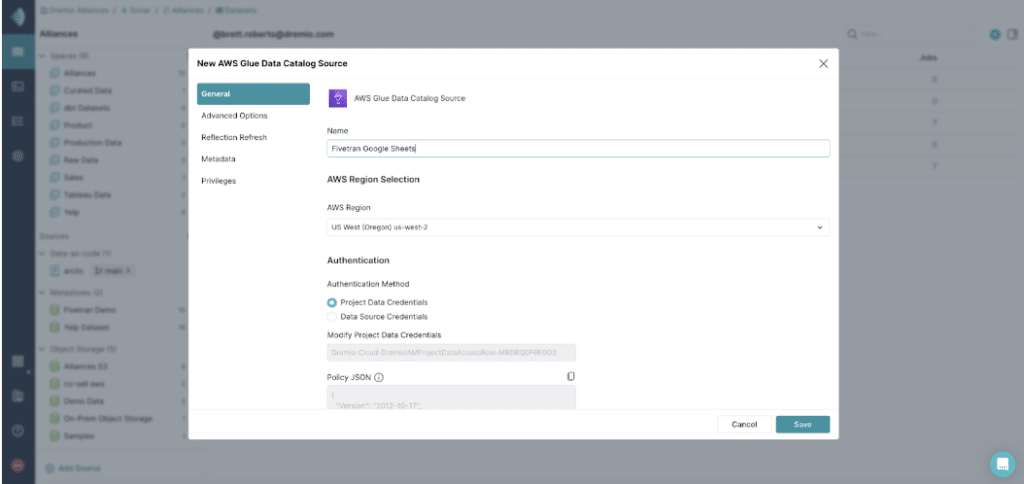
Create a AWS Glue connection by inputting the following required information:
- Name: <Name Data Connection>
- AWS Region: <Select the AWS Region you used with Fivetran>
- Authentication: Choose the correct authentication option based on your organization’s requirements. Refer to Dremio documentation to learn more about the different authentication options for AWS Glue.
Once you’ve entered the required information, click “Save.”
Once your connection has been established, you’ll be able to see the Iceberg tables written by Fivetran.
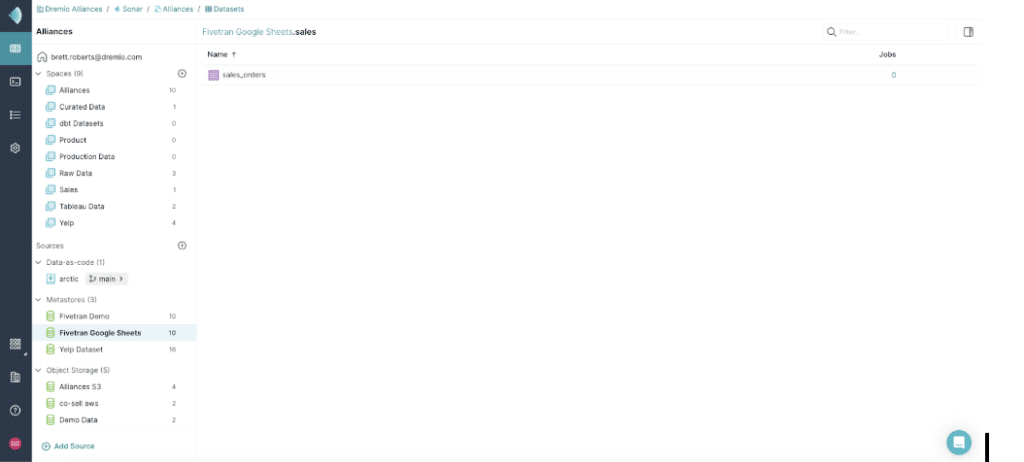
Now that Dremio is connected to your Iceberg tables, you have created the foundation for your data lakehouse.
Get started building your data lakehouse today! Try Dremio Cloud on AWS Today
If you want to give the open data lakehouse a try, it’s easy to get started. Visit www.dremio.com/get-started to try Dremio Cloud on AWS for free. All you pay for is AWS resources. You can also sign up and try Fivetran for free for 14 days! In minutes you can start building automated pipelines from countless data sources to your lakehouse and begin to query them with Dremio.
Sign up for AI Ready Data content
Additional Resources

BLOG
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights, Product Insights from the Dremio Blog,
Learn More ->

BLOG
Dremio Cloud on Azure Available Now
Dremio Blog: News Highlights,
Learn More ->