Over the past few years, we’ve reimagined the cloud data lake and have become the SQL engine of choice for many of the world’s leading companies across all industries.
Companies choose Dremio over cloud data warehouses because we enable mission-critical analytics and data democratization directly on cloud data lake storage without having to copy the data into a data warehouse beforehand. We’ve done this through innovations like Apache Arrow (an open-source, columnar standard for in-memory computing that we co-created), C3 (a columnar cloud cache), and Data Reflections (data structures that transparently accelerate common query patterns), and a semantic layer that makes data consumable, consistent, and secure for analysts and data scientists.
With Dremio, companies are able to leverage an open data architecture that gives them the flexibility to use best-of-breed engines directly on data as it resides in cloud object storage, and helps them avoid the vendor lock-in and rigidity of cloud data warehouses.
The clock is ticking for cloud data warehouses. Today, as part of our Dremio Summer 2021 Release, we’re announcing something that accelerates their obsolescence.
Dremio Summer 2021 Release: Introducing the Dart Initiative
Today’s Dremio Summer 2021 Release marks the first delivery of our Dart Initiative.
The Dart Initiative aims to bring all the features and performance of cloud data warehouses directly to the cloud data lake. Building on our existing innovations, the Dart Initiative helps companies run their mission-critical SQL workloads directly on the data lake and data lakehouse much faster than what they could do previously, accelerating the obsolescence of the cloud data warehouse.
This first Dart Initiative delivery is focused on performance, scalability and much faster availability of data as it lands on the lake. Here are the exciting key features that are part of this delivery:
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Fast and Optimal Query Planning
Database engines can choose from a wide range of strategies to plan queries, and the ability to generate an optimal query plan in any given situation can significantly impact performance. In this first release of the Dart Initiative, Dremio now gathers deep statistics about the underlying data, to help Dremio’s query optimizer choose the optimal execution path for any given query.
This release also introduces query plan caching, which eliminates planning overhead and latency for repeated queries. This is particularly impactful for BI dashboarding use cases, where many users are simultaneously firing similar queries against the SQL engine as they navigate through dashboards. In these scenarios, the planning phase of queries often consumes a large proportion of the total query runtime, so eliminating this repeated planning workload yields a significant improvement in application response time. This accelerates query planning by up to 8x:
Further, the Dart Initiative includes a high-performance compiler that enables much larger and more complex SQL statements with reduced resource requirements.
Comprehensive and ANSI-Standard SQL Coverage
This release empowers companies to run an even broader set of enterprise SQL workloads on Dremio by broadening SQL coverage to include additional functions, operators, and SQL grammar constructs, including additional window and aggregate functions, grouping sets, intersect, except/minor and more.
Faster Query Execution
Dremio is an in-memory engine powered by Apache Arrow, an open-source, columnar standard for in-memory computing that we co-created. Gandiva, a component of Apache Arrow, is an LLVM-based toolkit that enables vectorized execution directly on in-memory Arrow buffers, by generating code to evaluate SQL expressions that fully leverages the pipelining and SIMD capabilities of modern CPUs.
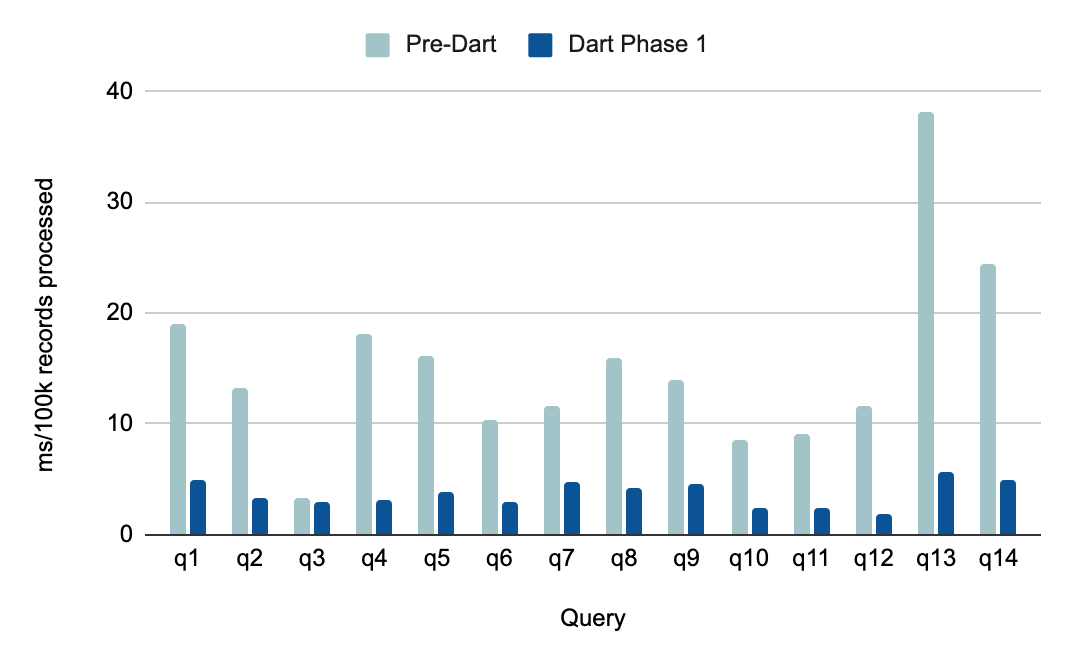
Dremio now provides a significant boost in performance of end-user queries with complex expressions by greatly extending Gandiva coverage to nearly all SQL functions, operators, and casts. Extending our Gandiva coverage maximizes the use of the underlying hardware optimizations, drastically improving the rate at which we process data, and ultimately query performance. The extended Gandiva coverage introduced in this release accelerates record processing rate by up to 6x:
The Dart Initiative also reduces the I/O required to run a query. While services like Amazon S3 and Azure Data Lake Storage (ADLS) make it extremely simple and cheap for companies to store their corporate data, companies are charged every time they read data from these services. We estimate cloud storage read operations (e.g., via the S3 API) constitute up to 30% of query execution costs in some workloads; other sources estimate over 60%.
Dremio now dramatically reduces the amount of data read from cloud object storage through extensive enhancements in scan filter pushdown (now supporting multi-column pushdown into source reads, the ability to push filters across joins, and more). These optimizations provide up to 8x faster query execution and less I/O:
Distributed and Real-Time Metadata Management
With the Dart Initiative, Dremio now supports unlimited table sizes with an unlimited number of partitions and files, as well as near-instantaneous availability of new data and datasets as they are persisted on the lake. This is now possible with the introduction of manifest-based metadata and version management, supporting the largest datasets in enterprises with the most demanding data freshness SLAs.
Enhanced Acceleration Management
A key feature of the Dremio engine is automated management of transparent query acceleration data structures (Data Reflections). This release greatly enhances Dremio’s ability to support the orchestrated refresh of hundreds of these reflections within multi-tenant environments.
Watch this space!
With the Dart Initiative, we’re excited to help companies run mission-critical SQL workloads on cloud data lakes faster and more efficiently than ever by optimizing every dimension of query execution in the Dremio Engine. These enhancements complement Dremio’s existing innovations, including Apache Arrow, C3, and Data Reflections.
Today’s release, which encompasses multiple facets of Dremio’s service and provides performance improvements of 2x over previous versions, is just the first phase in the Dart Initiative.
We’ll be delivering many more innovations this year, both within the Dart Initiative and beyond as we move closer to obsoleting the data warehouse. Stay tuned!
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.