Today I’d like to pursue a brief discussion about how changing the size of a Parquet file’s ‘row group’ to match a file system’s block size can effect the efficiency of read and write performance. This tweak can be especially important on HDFS environments in which I/O is intrinsically tied to network operations.
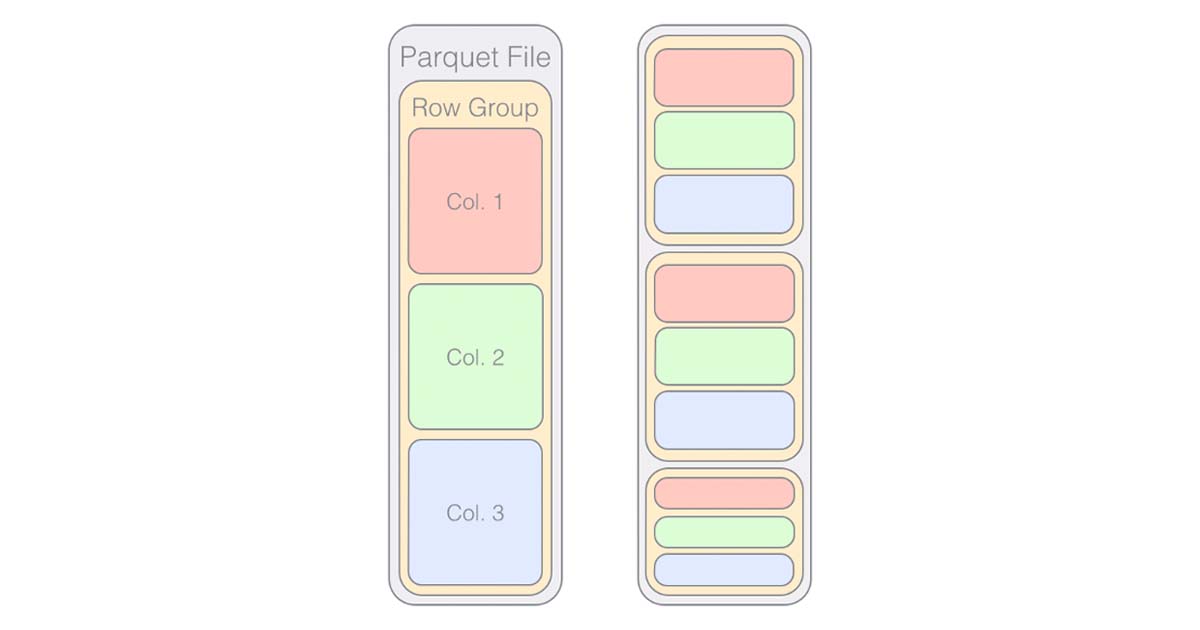
To understand why the ‘row group’ size matters, it might be useful to first understand what the heck a ‘row group’ is. For this let’s refer to Figure 1, which is a simple illustration of the Parquet file format.
As you can see, a row group is a segment of the Parquet file that holds serialized (and compressed!) arrays of column entries. Since bigger row groups mean longer continuous arrays of column data (which is the whole point of Parquet!), bigger row groups are generally good news if you want faster Parquet file operations.
But how does the block size of the disk come into play? Let’s look at Figure 2, which explores three different Parquet storage scenarios for an HDFS file system. In Scenario A, very large Parquet files are stored using large row groups. The large row groups are good for executing efficient column-based manipulations, but the groups and files are prone to spanning multiple disk blocks, which risks latency by invoking I/O operations. In Scenario B, small files are stored using a single small row group. This mitigates the number of block crossings, but reduces the efficacy of Parquet’s columnar storage format.
An ideal situation is demonstrated in Scenario C, in which one large Parquet file with one large row group is stored in one large disk block. This minimizes I/O operations, while maximizing the length of the stored columns. The official Parquet documentation recommends a disk block/row group/file size of 512 to 1024 MB on HDFS.
In Apache Drill, you can change the row group size of the Parquet files it writes by using the ALTER SYSTEM SET command on the store.parquet.block-size variable. For instance to set a row group size of 1 GB, you would enter:
ALTER SYSTEM SET `store.parquet.block-size` = 1073741824;
(Note: larger block sizes will also require more memory to manage.)
Parquet and Drill are already extremely well integrated when it comes to data access and storage—this tweak just enhances an already potent symbiosis!
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Aug 16, 2023·Dremio Blog: News Highlights
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.