13 minute read · April 15, 2024
Streaming and Batch Data Lakehouses with Apache Iceberg, Dremio and Upsolver
· Head of DevRel, Dremio

The quest for a unified platform that seamlessly integrates streaming and batch data processing has led to the emergence of robust solutions like Apache Iceberg, Dremio, and Upsolver. These technologies are at the forefront of a new wave of data architecture, enabling businesses to build robust data lakehouses that cater to diverse analytical and operational needs. This blog explores the synergy between Apache Iceberg, Dremio, and Upsolver in creating a dynamic ecosystem where data from various sources, including databases, files, and streams, is ingested into Apache Iceberg tables using Upsolver. We delve into how this integrated approach facilitates efficient querying and analysis with Dremio, serving up insights for analytics and data science in a previously unattainable way.
The convergence of streaming and batch processing within a data lakehouse architecture addresses critical challenges in data management, offering flexibility, scalability, and real-time analytics capabilities. By leveraging Apache Iceberg's table format, organizations can easily manage large datasets, ensuring consistency and reliability across their data infrastructure. Dremio comes into play by providing powerful SQL querying capabilities, making it more straightforward for analysts and data scientists to extract valuable insights without the complexities traditionally associated with big data processing. Meanwhile, Upsolver plays a crucial role in streamlining the extensive data ingestion process, ensuring that both real-time and historical data are seamlessly integrated into Apache Iceberg tables, ready for analysis.
Join us as we navigate the intricacies of setting up a modern data lakehouse powered by the robust combination of Apache Iceberg, Dremio, and Upsolver, and discover how this integrated solution is revolutionizing the data landscape.
Ingesting Data with Upsolver
Ingesting data into your Apache Iceberg tables begins with setting up your environment in Upsolver. Here's a step-by-step guide to get you started with data ingestion, using S3 as both the source and the target in our example:
Sign Up for Upsolver: The first step is to create a new account on Upsolver. If you're new to the platform, Upsolver offers a free 14-day trial to explore its features and capabilities without any initial investment. Navigate to the Upsolver sign-up page, enter your details, and get started with your trial account.
Initiate a New Job: Once your account is set up, the next phase is to create a new ingestion job. In Upsolver, a job represents the process of data ingestion from your selected sources to a specified target. To begin, navigate to the Upsolver dashboard and choose the option to create a new job.
Select Your Data Source: The right data source is crucial for your ingestion job. Upsolver provides a variety of sources, catering to both streaming and batch data needs. You can choose from Apache Kafka, Confluent Cloud, and Amazon Kinesis for streaming. For CDC sources, options include MySQL, PostgreSQL, SQL Server, and MongoDB. Finally, you can also ingest large and deeply nested files from S3 with ease in Upsolver. Select the source that aligns with your data storage or streaming service. We’ll select S3 as our source for this tutorial, assuming that our data resides in S3 buckets.
Choose Your Target Destination: After selecting your source, the next step is to define where you want to land your data. Since we are focusing on creating Apache Iceberg tables for analysis in Dremio, the target needs to be compatible with Iceberg and Dremio. Although Upsolver supports various targets, we’ll choose AWS Glue Data Catalog, backed by S3, as our target destination. This choice aligns with our source and simplifies the process, keeping both source and target within the same storage service.

Configure Source: On the next screen, you’ll configure your S3 connection, which can be done using IAM roles or Secret/Access Key pairs. You’ll configure the connection and then select the directory where the files to be ingested can be found.
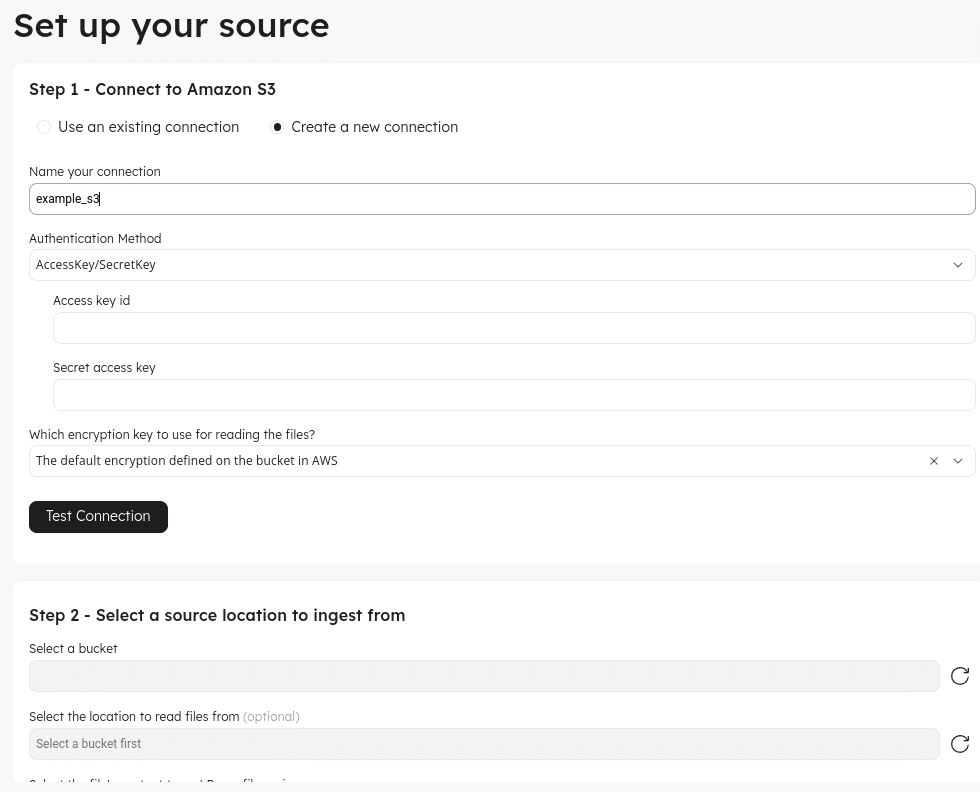
Configure Target: On the next screen, you’ll configure your AWS Glue connection, which can be done using IAM roles or Secret/Access Key pairs. You’ll configure the connection and then select the region the table should exist in, along with a bucket where files should be written to. Choose the table type to be “Upsolver Managed Iceberg." This will make the resulting table an Iceberg table that Upsolver will continuously optimize, as new data is streamed into the table. Make sure to test the connection, and then you should be able to select the schema (database) and a table name.
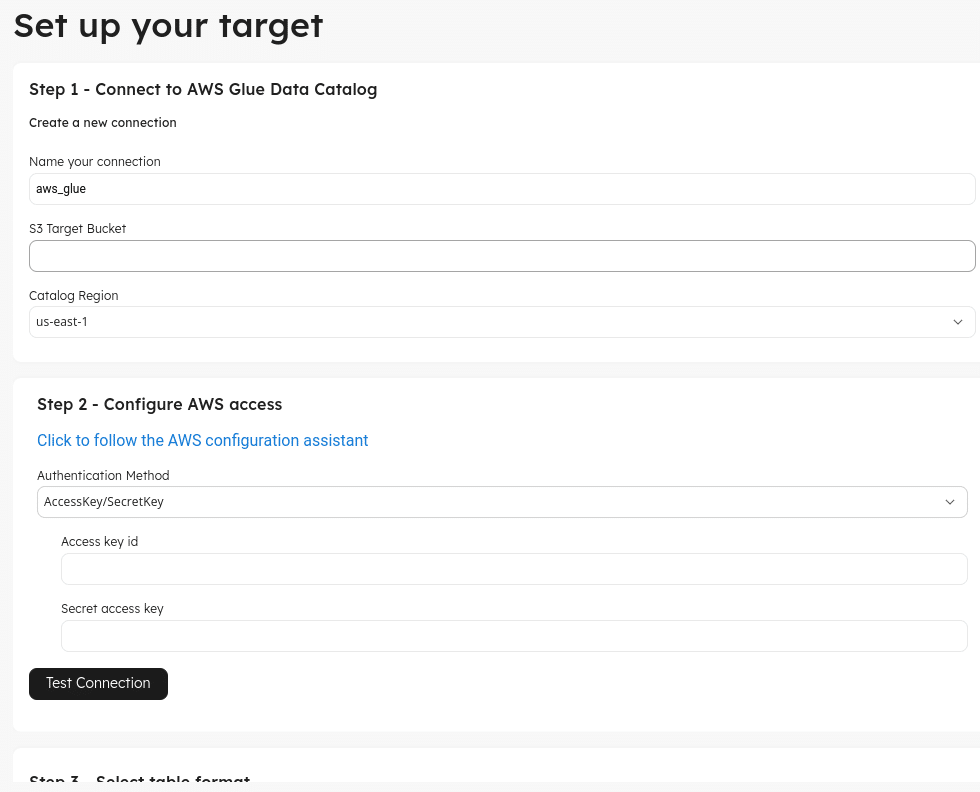
Configure The Job: On the next screen, you can configure the schema for data to be ingested, choosing to exclude, hash, or set expectations on columns, as well as whether or not to deduplicate data.
Edit the SQL Logic: On the next screen, you can review the resulting SQL generated based on your configurations. Once it is to your liking, it is time to run the job.
Data ingested directly by Upsolver into your Iceberg lakehouse in this way is automatically compacted and manifest files are optimized. Dremio also offers auto-optimization of Apache Iceberg tables in its Lakehouse Catalog, providing you with multiple angles to ensure your Iceberg lakehouse tables are always optimized.
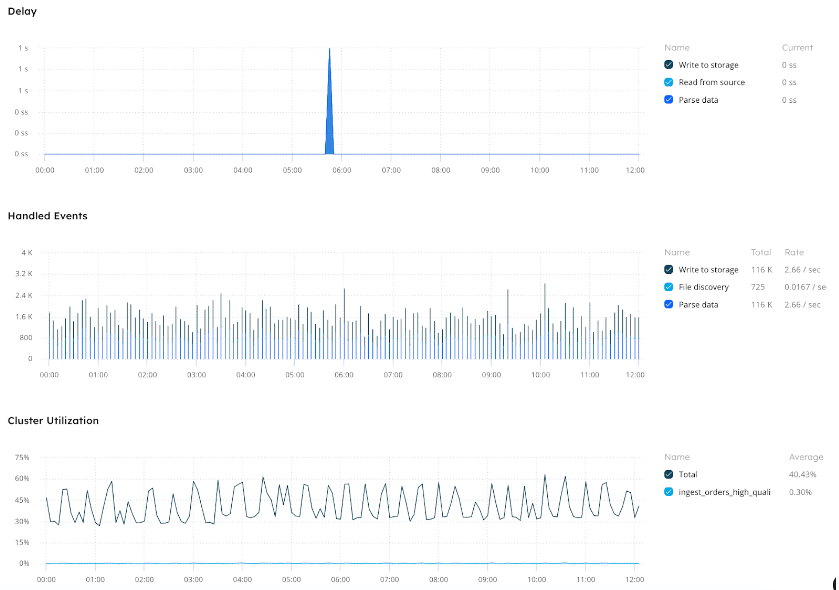
Monitor the job and data: You can monitor the ingestion job you just created from Upsolver, including volume of data processed and cluster utilization over time.
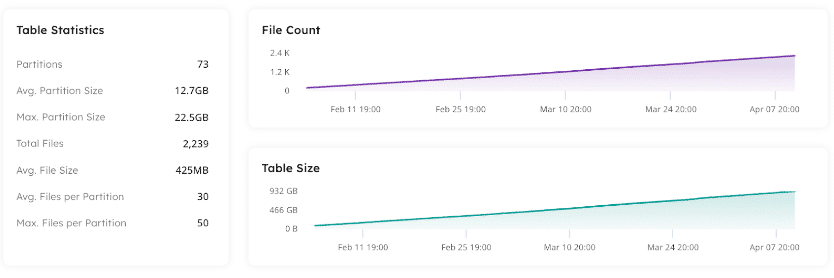
For an Iceberg lakehouse, it’s important to keep track of how the file, partition and table sizes grow. This information is readily available as well.
Finally, a new feature in preview, Upsolver now provides a full lineage view of the data you are ingesting. The source, job and target is shown below, and other connected jobs and datasets will also appear.

Following these steps, you create a pipeline in Upsolver that ingests data from S3, processes it according to your specified logic, and then lands as a managed Apache Iceberg table tracked in your AWS Glue catalog. This streamlined process facilitates efficient data management and ensures that your data is primed for analysis with Dremio.
Running Analytics with Dremio
Having successfully ingested data into an Apache Iceberg table using Upsolver, we now pivot to leveraging Dremio for analytical processing on this data. Dremio shines as a data lakehouse platform, offering three core advantages that make it an essential tool for managing and analyzing data in Apache Iceberg Lakehouses.
Unified Analytics: Dremio excels in providing a unified analytics layer, enabling seamless querying and data curation across diverse sources, including databases, data lakes, and data warehouses. It establishes a governed, unified semantic layer that facilitates self-service data access, ensuring that data consumers across the organization can easily interact with and derive insights from the data landscape.
SQL Query Engine: Dremio's query engine is unmatched in its prowess, allowing rapid queries across various data sources. Its performance rivals and often surpasses that of traditional data warehouses. This is largely due to its integration with Apache Arrow and Apache Iceberg. A notable feature is Dremio's data reflections, which negate the necessity for materialized views and BI extracts, streamlining the data querying process.
Lakehouse Management: While Upsolver adeptly handles the ingestion and management of streaming data into Apache Iceberg tables, Dremio extends its management capabilities to these tables within its lakehouse catalog. It offers automatic optimization and snapshot cleanup, ensuring the seamless operation of your Iceberg tables. Additionally, Dremio's Lakehouse catalog benefits from integrating with Nessie, an open-source project that provides a suite of Git-like versioning features for catalog management.
To commence analytics on the data ingested via Upsolver, the initial step involves setting up Dremio, which can be deployed through Dremio's Cloud Managed or Self-Managed solutions. Dremio can be run directly on your laptop for trial or demonstration purposes using Docker. The following Docker command initiates a local Dremio instance, facilitating a hands-on experience with the platform:
docker run -p 9047:9047 -p 31010:31010 -p 45678:45678 -p 32010:32010 -e DREMIO_JAVA_SERVER_EXTRA_OPTS=-Dpaths.dist=file:///opt/dremio/data/dist --name try-dremio dremio/dremio-oss
This command sets up a Dremio environment ready for exploration and interaction at localhost:9047. It allows you to interact directly with the data ingested through Upsolver, and experience Dremio's robust analytical capabilities.
Connecting Our Data
Once a Dremio environment is running and accessible at http://localhost:9047, click “add source” on the bottom left corner and select “AWS Glue Data Catalog” as our new data source.
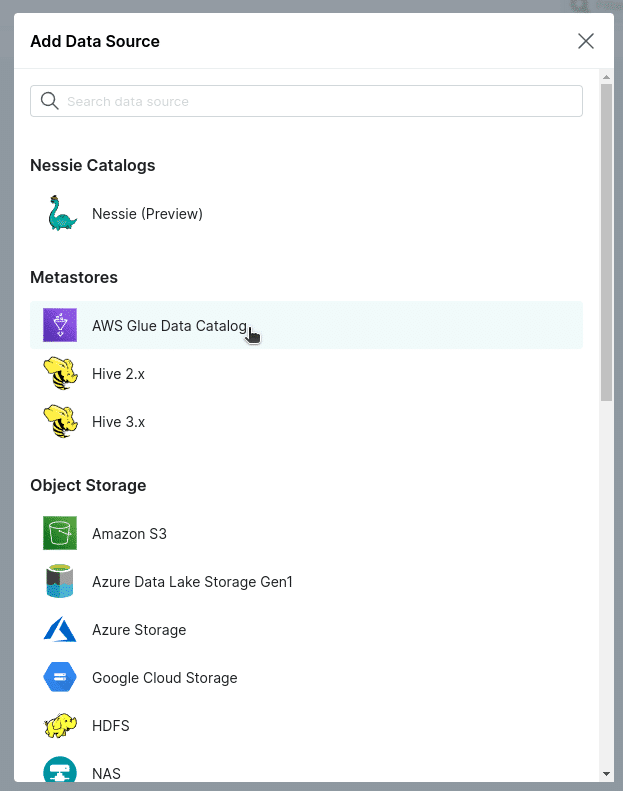
Then name the sources and authorize either through IAM Roles or a Secret/Access key pair.
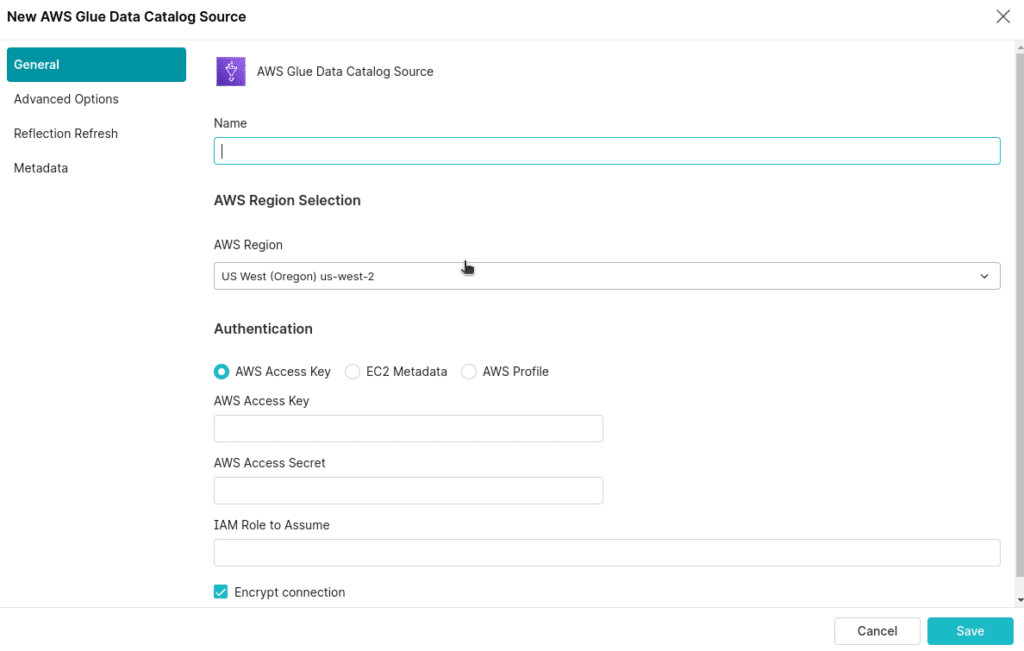
If you want to be able to write new tables to your AWS Glue catalog using Dremio, you need to set a warehouse directory, which can be set under advanced options. Just set the connection property of “hive.metadata.warehouse.directory” to the designed S3 location.
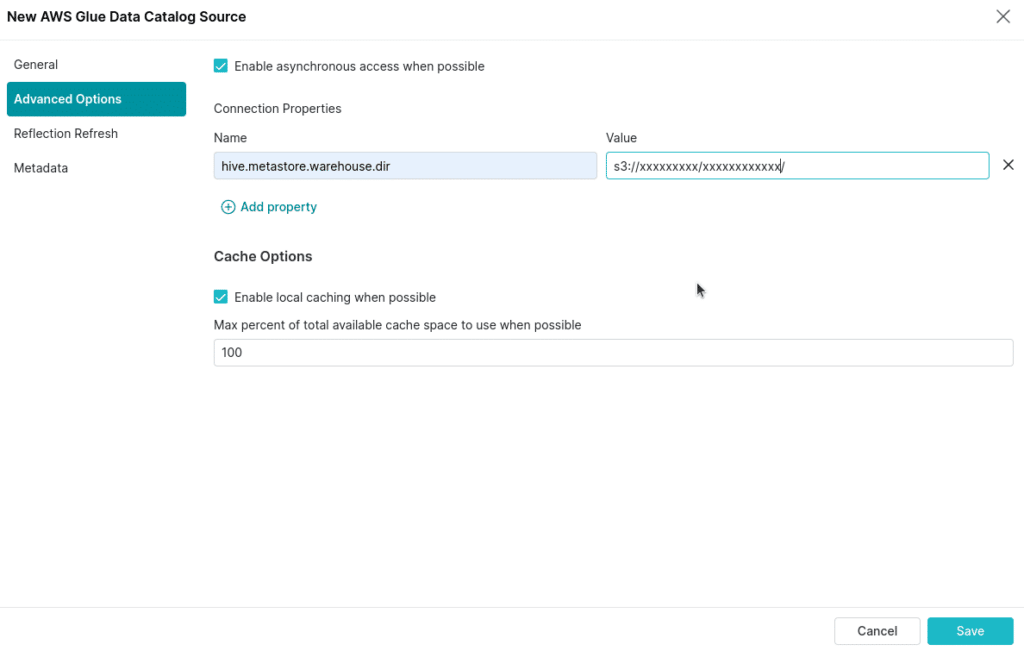
Once the connection is established, you’ll see the table with our ingested data from within Dremio.
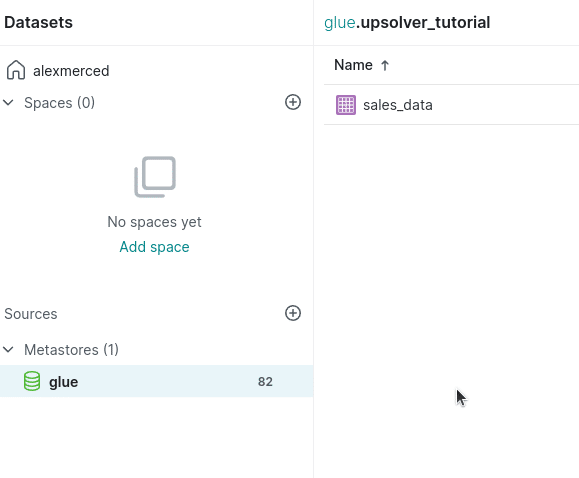
You can now click on the table and run queries on it.
Conclusion
With the capability to query the Iceberg data through Dremio, a wealth of possibilities unfolds. We can augment the data by incorporating information from other databases, data lakes, and warehouses that Dremio supports as data sources. Dremio facilitates seamless integration with many BI tools, allowing for efficient data delivery to BI dashboards. Finally, Dremio connects effortlessly with Python notebooks through JDBC/ODBC, REST API, or Apache Arrow Flight for more analytical and programmatic work. This connectivity enables the generation of comprehensive reports and the development of machine learning models on top of a fully-optimized Iceberg lakehouse.
Dremio serves as a bridge, connecting data from diverse sources and making it accessible across various platforms. In tandem with Upsolver, we can establish continuous data pipelines that ingest streaming data from sources like Apache Kafka or Amazon Kinesis, depositing this data into Iceberg tables within our AWS Glue catalog. This setup empowers Dremio to perform real-time analytics, creating a potent synergy that yields impactful outcomes.
Sign up for AI Ready Data content
Additional Resources

BLOG
Hadoop Modernization on AWS with Dremio: The Path to Faster, Scalable, and Cost-Efficient Data Analytics
Hadoop modernization on AWS with Dremio represents a significant leap forward for organizations looking to leverage their data more effectively. By migrating to a cloud-native architecture, decoupling storage and compute, and enabling self-service data access, businesses can unlock the full potential of their data while minimizing costs and operational complexity.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Enhancing your Snowflake Data Warehouse with the Dremio Lakehouse Platform
Integrating Snowflake with the Dremio Lakehouse Platform offers a powerful combination that addresses some of the most pressing challenges in data management today. By unifying siloed data, optimizing analytics costs, enabling self-service capabilities, and avoiding vendor lock-in, Dremio complements and extends the value of your Snowflake data warehouse.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Streaming Data, Instant Insights: Real-Time Analytics with Dremio & Confluent Tableflow
With Confluent Tableflow and Dremio, businesses can query real-time and historical data together in an open lakehouse architecture providing insights at the speed of operational data.
Dremio Blog: Partnerships Unveiled,
Learn More ->