
A semantic data layer that speaks the language of your business
Dremio's Universal Semantic Layer delivers consistent, collaborative, governed access across all your data
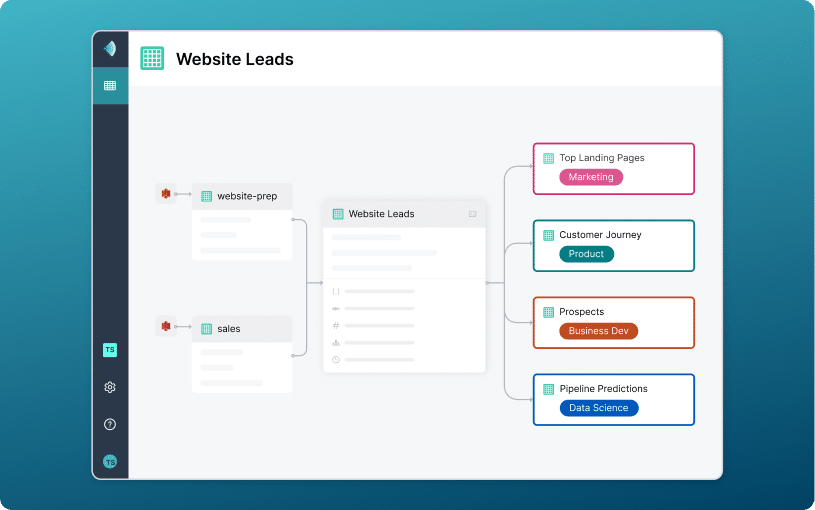
Curate a virtual data set with no data movement
It's easy to build views, virtual data sets and even virtual data marts across all of your data sources with Dremio's Universal Semantic layer. Users have self-service access to analyze data sets in the language of the business, without ETL.
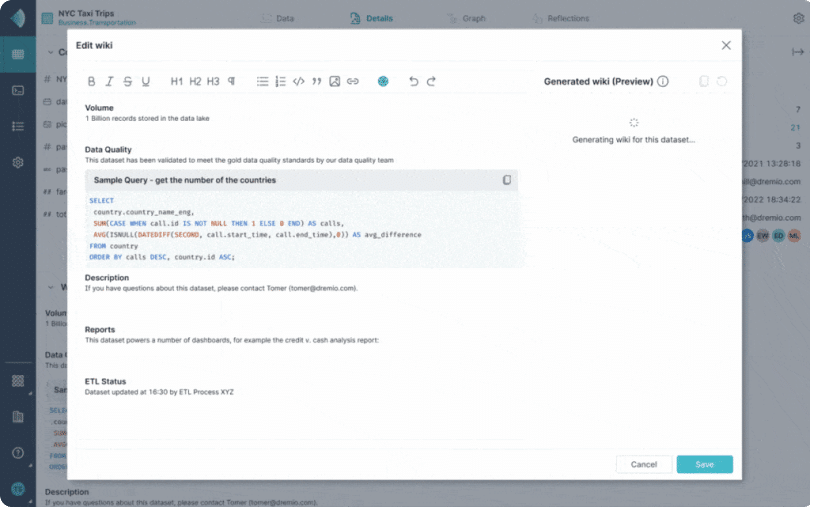
Intuitive business and technical metadata help put data to work
Gain a deeper understanding of curated sets and views of data with user-generated wikis and dataset definitions that make it easier to understand and collaborate on data projects. Wikis also include detailed column descriptions and can be automatically updated using REST API.
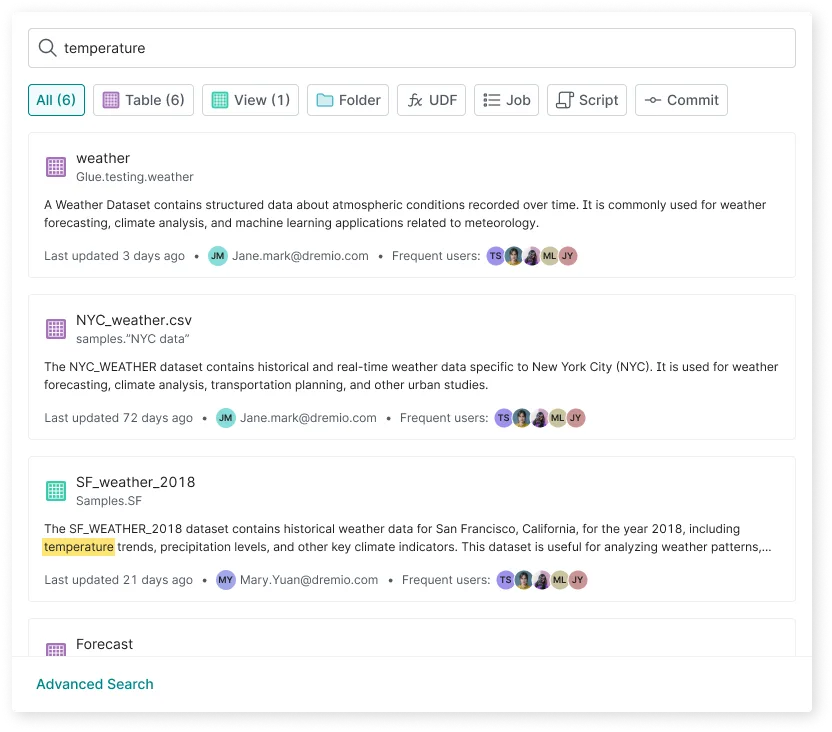
Easily label, search for and discover your data
Sets and views can be labeled for search and discovery, both manually and using GenAI. Dremio's centralized, scalable governance ensures that role and user-based permissions and data access are applied from the data source up, so the right users have access to the right data.
See how leading enterprises use Dremio’s semantic layer

Report
Ranked #1 semantic layer vendor by Dresner Advisory Services
Dremio's AI Semantic Layer is recognized as the industry leader, delivering the governed business context, semantic search, and metadata management that AI agents and analytics teams need to drive trusted insights at scale.
Learn More →

Case Study
Improved Supply Chain with >10x Query Performance and 90% Faster Project Delivery
Dremio's data lakehouse helped Amazon achieve 10x faster query performance and reduce project completion times by 90%.
Learn more

Case Study
Global Logistics Leader Maersk Scales Analytics from Zero to 1.6M Daily Queries with Dremio
Maersk transformed its global logistics operations by rebuilding its data infrastructure with Dremio’s open data lakehouse platform. Using Apache Iceberg and a scalable architecture, Maersk achieved 99.97% uptime and grew to 1.6 million daily queries across shipping, trucking, warehousing, and air cargo operations.
Learn more
FAQs
Frequently asked questions
The semantic data layer is an abstraction that sits between raw data and business users, translating complex technical data structures into intuitive business concepts that everyone can understand and use consistently. Instead of analysts needing to know that “customer lifetime value” requires joining five tables with specific filters and calculations, the semantic layer encapsulates that logic into a single, reusable definition like “Customer_LTV” that anyone can query. This layer defines standardized business metrics, dimensions, and relationships – things like “Revenue,” “Active Customer,” or “Product Category” – with the underlying SQL logic already handled. The key benefit is that it ensures consistency across the organization: when everyone uses the same semantic definitions, you eliminate the problem of ten different people calculating “monthly revenue” ten different ways and arriving at conflicting numbers in their reports. It also shields users from changes in underlying data structures – if your raw tables get reorganized or a new data source is added, the semantic layer is updated once and all downstream queries continue working with the same business-friendly interface.
The semantic business layer and the data lakehouse operate at different levels of the technology stack, serving different but complimentary functions. A data lakehouse is the central infrastructure layer, storing and facilitating the cost-effective analysis of massive volumes of data. The semantic business layer sits on top of the data lakehouse as a logical abstraction, translating the technical data structures in the lakehouse into easy to comprehend business language. The lakehouse makes data accessible and performant; the semantic layer makes it understandable and consistent.
A semantic layer in data analytics dramatically enhances Business Intelligence (BI) by centralizing business logic in a reusable data model that people, BI tools, and AI can leverage, eliminating inconsistencies and accelerating insight generation. The semantic layer encodes business logic in a centralized data model, with attributes defined with specific criteria or exact calculations. When this logic lives in the semantic layer rather than downstream reports, it ensures consistency and confidence across every analysis.
The Semantic Layer serves as an abstraction layer that translates complex, technical data into user-friendly, business-oriented terms. It assists business users to independently retrieve and analyze data without the need for extensive technical knowledge or assistance. Data Visualization is a technical integration layer that allows users to query data across multiple sources (e.g. databases, data lakes, data catalogs, etc.) without physically moving or copying it. In short, Data Virtualization connects siloed data sources together, whilst the semantic layer sits on top to define the business context for those connected data sources.
Applying a semantic layer to your data lakehouse delivers transformative benefits by turning raw, complex data into a governed, business-ready analytics platform. It establishes a single source of truth, democratizes data access, and accelerates time-to-insights. With a centralized repository of business metrics and definitions acting as your single source of truth, the semantic layer ensures all data teams align on how attributes are defined and derived. The semantic layer also abstracts away the technical complexity of data schemas or dataset versions in favour of business-friendly logic that democratizes data access to non-technical users. And finally, having centralized, easily comprehensible datasets dramatically reduces the time from question to answer, as users have readily available data models that do not require any hard work of locating, understanding, or building.
A semantic data layer dramatically improves data governance and security by clearly defining in a central location the ownership, lineage, and definitions of your data. This creates an auditable single source of truth, making compliance straightforward. When regulators ask how you calculate financial metrics or who accessed customer data, you have complete transparency and traceability that would be impossible when business logic is scattered across countless individual reports. The semantic layer also simplifies compliance with regulations like GDPR or CCPA by providing a control point for data protection – implementing “right to be forgotten” or restricting access to sensitive data happens once at the semantic layer rather than hunting through every dashboard. It prevents shadow IT by making governed data so easy to access that users don’t resort to creating ungoverned copies or extracting data into spreadsheets.
A semantic data layer and a data mart both aim to make data more accessible for business users, but they differ fundamentally in how they achieve this. Data marts are physical copies of data – subsets extracted from your data warehouse or lake, transformed, and stored separately for specific departments or use cases. For example, Marketing gets a marketing data mart with pre-aggregated campaign metrics, Finance gets a finance data mart with cleaned financial data, etc. Data Marts make data more accessible through replication of data, designed before the advent of Data Lakehouses when storage was expensive and query engines were slow.
In comparison a semantic data layer makes data more accessible by making datasets easier to understand, by defining the associated business logic and metrics. The semantic data layer is designed for self-service analytics in the modern, data lakehouse era with warehouse-like performance through query acceleration on virtualized data and physical data stored cheaply in data lakes.
Implementing a semantic layer presents organizational and technical challenges. The biggest hurdle is achieving cross-functional alignment on standard business definitions – different departments often have legitimate reasons for calculating metrics like “revenue” or “active customer” differently. Balancing standardization with flexibility can also be difficult; too rigid and analysts work around the semantic layer creating “shadow definitions” in their downstream tools, too flexible and you lose consistency. The next largest issue for implementing a semantic layer is migrating to the new agreed definitions. Even well-designed semantic layers fail if users don’t adopt them – people resist abandoning familiar workflows and tribal knowledge about existing data structures, requiring training and clear demonstrated value to overcome inertia. Migration is messy as the entire organization cannot switch at once, instead these large changes are rolled out incrementally across teams or departments. This staggered migration, while sensible, can create confusion as for periods of time the old and new systems coexist.
The common technical challenges derive from the design and maintenance of the semantic layer. A poorly designed semantic layer, with overly complex business logic executing across diverse data sources, causes query bottlenecks. Alleviating these performance issues then requires expertise in query optimization and ongoing performance tuning. Long-term success of the semantic layer also requires dedicated stewardship: the semantic layer needs continuous investment as business requirements evolve, new data sources emerge, and metrics change. Without processes for requesting changes, versioning definitions, communicating updates, and deprecating obsolete metrics, the semantic layer stagnates and stops being a valuable, living product that serves the organization.
A semantic data layer enables self-service analytics across domains by providing a unified, business-friendly abstraction over diverse data platforms. Through a Universal Semantic Layer, organizations can define consistent business metrics, dimensions, and relationships, meaning users interact with familiar terms like “customer” or “revenue” instead of table schemas. This ensures consistent logic and governance across your organization, allowing different domains to analyze and share insights using a common, trusted foundation.
By translating high-level business queries into optimized platform-specific code, the Universal Semantic Layer empowers users to perform ad hoc exploration without deep technical expertise. Domain teams can maintain their own models while aligning with enterprise-wide standards, balancing autonomy with consistency. As a result, analytics becomes operationalized at scale, with accelerated insight generation, reduced redundancy, and true self-service access to governed, reliable data across the organization.
A semantic data layer accelerates AI and machine learning (ML) initiatives by creating a unified, context-rich view of enterprise data. It standardizes business definitions, relationships, and metrics across disparate data platforms, ensuring that AI and ML models are trained on consistent, high-quality data. This semantic consistency eliminates the need for repeated data wrangling and manual feature engineering across teams, allowing data scientists to access trusted, ready-to-use datasets that reflect the organization’s shared business logic.
For AI agents, a Universal Semantic Layer acts as a powerful enabler of intelligence and autonomy. Because the layer encodes business context and relationships, AI agents can interpret, query, and reason about enterprise data using natural language or structured logic, without the need to understand underlying schemas or query languages. This allows agents to generate insights, perform ad hoc analysis, or trigger automated decisions directly against governed data assets. In essence, the semantic layer transforms raw data into an interpretable, machine-readable knowledge base, empowering AI agents to act as reliable, context-aware partners in analytics and decision-making.