11 minute read · May 30, 2025
Using Dremio with Confluent’s TableFlow for Real-Time Apache Iceberg Analytics
· Head of DevRel, Dremio

Download a Free Copy of Apache Iceberg: The Definitive Guide
Download a Free Copy of Apache Polaris: The Definitive Guide
Apache Iceberg tables provide a powerful, open table format designed for large-scale analytics, while Kafka topics deliver high-throughput, real-time data streams. Together, they form a foundation for modern data architectures that support both streaming and batch workloads with consistency, performance, and flexibility.
Confluent recently introduced a compelling new feature called TableFlow, which dramatically simplifies the process of ingesting Kafka topics into Apache Iceberg tables. With just a few clicks, TableFlow allows you to seamlessly convert streaming data from your Confluent clusters into open, analytics-ready Iceberg tables.
While users have the option to bring their own external catalogs and object storage, Confluent also offers a fully managed experience. By leveraging Confluent’s built-in catalog and managed storage, teams can reduce operational overhead and accelerate their time-to-insight. This creates an elegant path to making real-time data available across the Apache Iceberg ecosystem, enabling powerful, cost-efficient analytics using tools like Dremio.
Creating Tables with TableFlow
Before you can begin using TableFlow to stream Kafka data into Apache Iceberg tables, there are a few prerequisites and setup steps you’ll need to complete:
- Create a Confluent Account
Start by signing up for a Confluent Cloud account at confluent.io. This will give you access to the Confluent Cloud dashboard, where you can manage clusters, topics, connectors, and now TableFlow. - Provision a Confluent Cluster
Once logged in, create a Confluent cluster in your desired cloud provider and region. This cluster will serve as the Kafka backbone for managing and streaming your data. - Create a Kafka Topic
With your cluster ready, create a Kafka topic where data will be published. This topic will act as the source stream for your TableFlow pipeline. - Connect a Data Source to the Topic
You’ll need to start publishing data to the topic. This can be done via Kafka producers or connectors (e.g., JDBC source, REST proxy, etc.), depending on your use case. This step ensures that TableFlow has actual messages to process when initializing the Iceberg table.
Enabling TableFlow on a Kafka Topic
With these prerequisites in place, you can now enable TableFlow:
- Navigate to the "Topics" section within the Confluent Cloud dashboard.
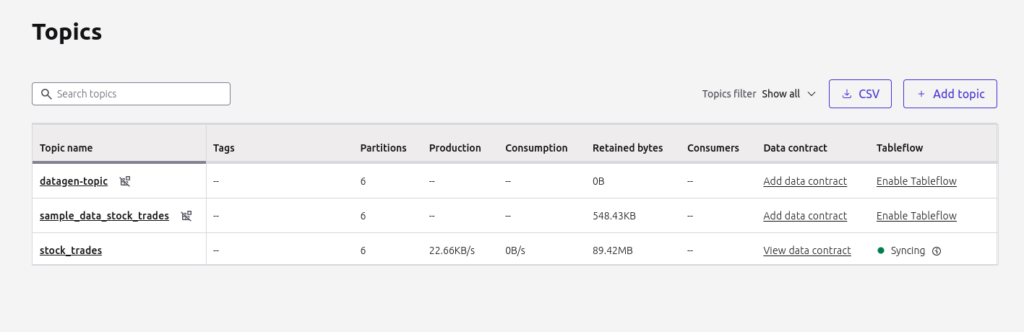
- Select the topic you wish to sync with Iceberg.
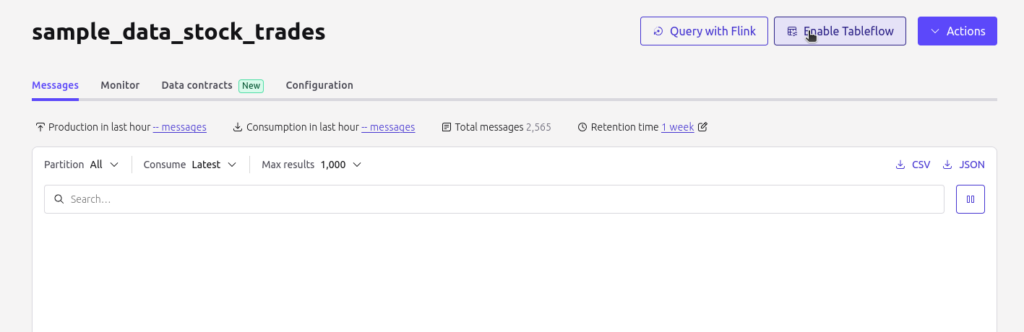
- You’ll see an option to “Enable TableFlow”. Click to begin the configuration process.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Schema Requirements
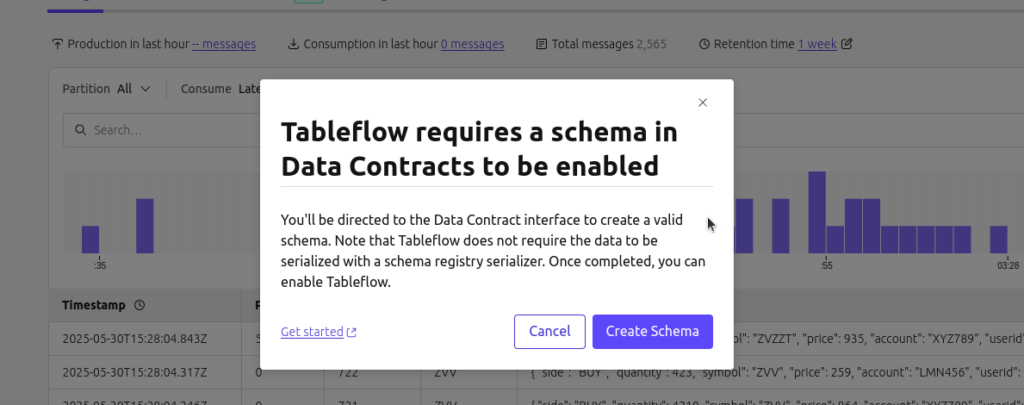
TableFlow relies on schema information to correctly map Kafka messages into Iceberg tables. If your topic uses Avro serialization and has an associated schema registered in the Confluent Schema Registry, the process is typically seamless. However, if your topic uses less schema-explicit formats like JSON, you may need to manually register a schema in the registry before proceeding. This ensures that TableFlow can accurately interpret the data structure and write it into Iceberg tables using the correct column mappings and types.
Choosing Your Storage and Catalog
After the schema validation step, you’ll be prompted to select your table format and storage option:
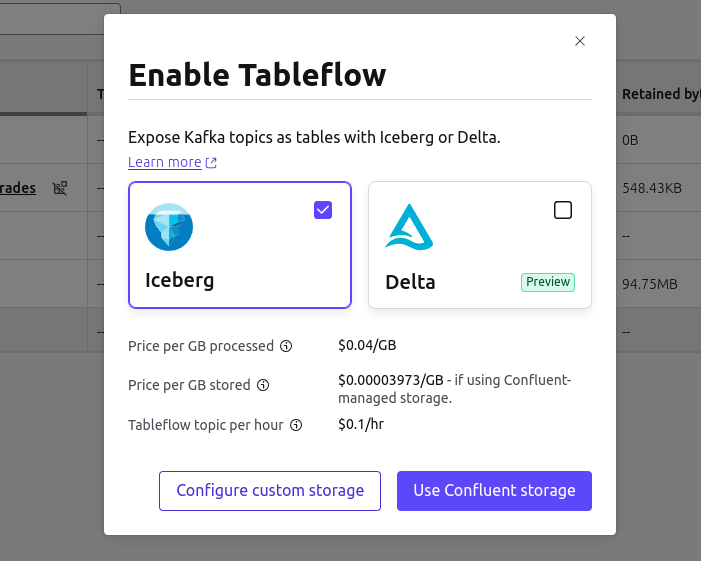
- Bring Your Own Catalog and Storage: If you already have an existing Iceberg catalog backed by object storage (e.g., S3, GCS), you can configure TableFlow to write directly into it.
- Use Confluent’s Managed Catalog and Storage: For a fully managed experience, choose Confluent’s integrated catalog and storage solution. This option reduces operational complexity and simplifies the process of getting started, eliminating the need to manage infrastructure.
Once your choice is confirmed, TableFlow will begin initializing the Iceberg table.
How TableFlow Works Behind the Scenes
After initialization, TableFlow sets up an Apache Iceberg table and begins committing data from your Kafka topic. The ingestion behavior is as follows:
- Initial Commit: A commit is made to create the table structure based on the schema.
- Ongoing Commits: TableFlow commits new Kafka messages into Iceberg on a time-based interval or when a configured file size threshold is reached—whichever comes first. This ensures efficient file sizes and optimal query performance.
Accessing Your Table and Catalog Information
If you chose to use Confluent’s built-in Iceberg catalog:
- You can find the Iceberg REST catalog URL under the "Monitor" tab of the topic’s detail page in the dashboard.
- Authentication is simple—use your Confluent API key associated with the cluster to access the catalog from tools like Dremio or Spark.
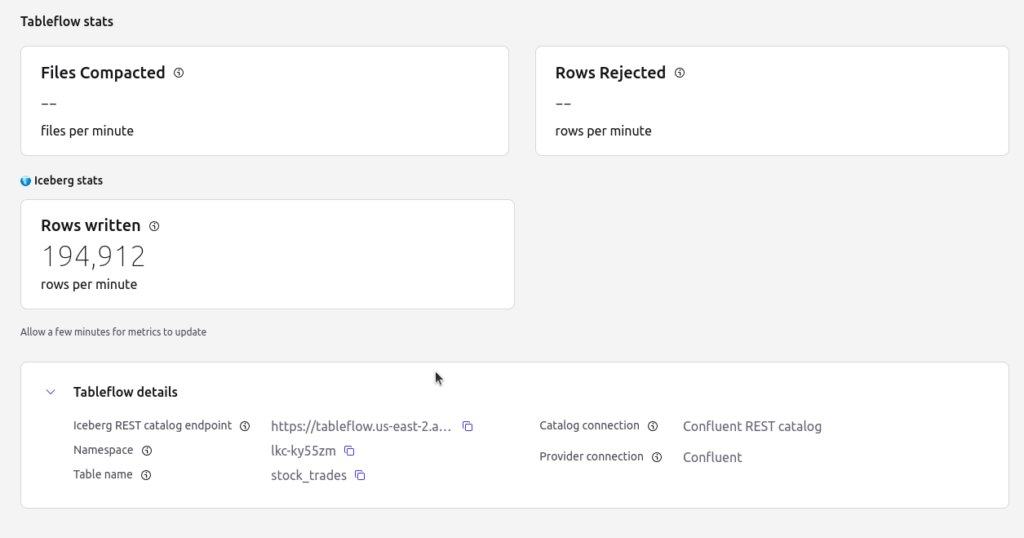
Connecting With Dremio
Once your Kafka topic has been ingested into an Iceberg table via TableFlow, querying that table in Dremio is fast and straightforward thanks to Dremio’s support for the Iceberg REST Catalog interface.
Follow these steps to connect Dremio to your Confluent-managed Iceberg tables:
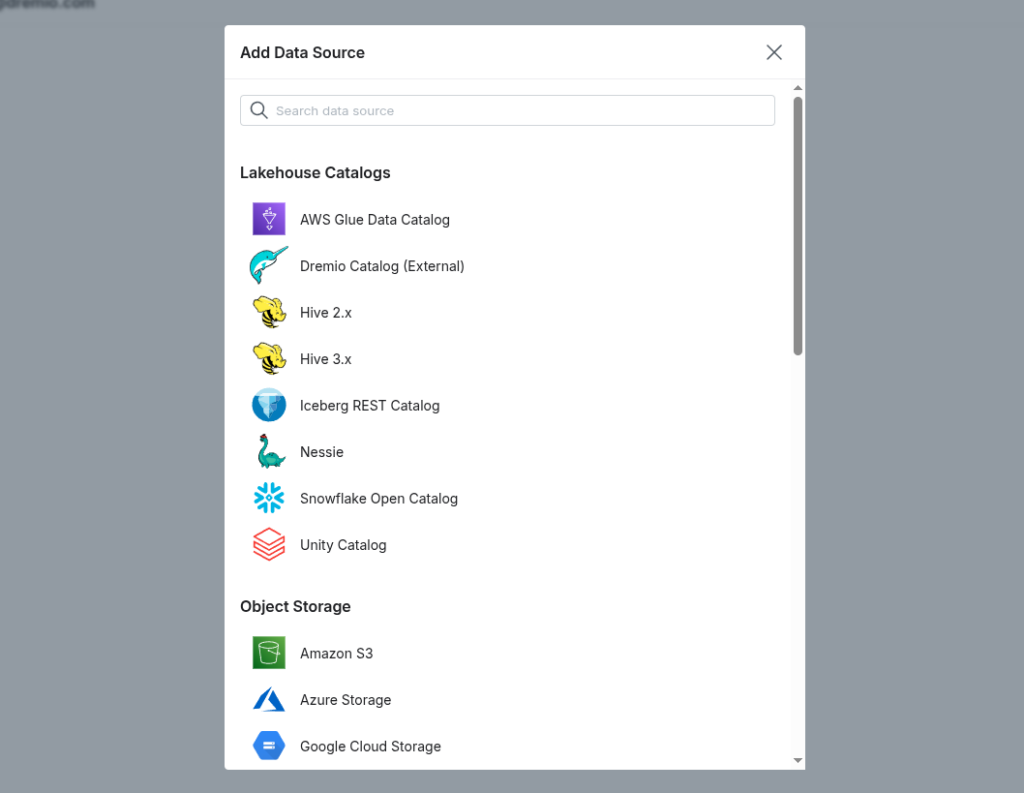
Step 1: Add the Iceberg REST Catalog Source
- In the Dremio UI, go to "Add Source".
- Choose “Iceberg REST Catalog” as the source type.
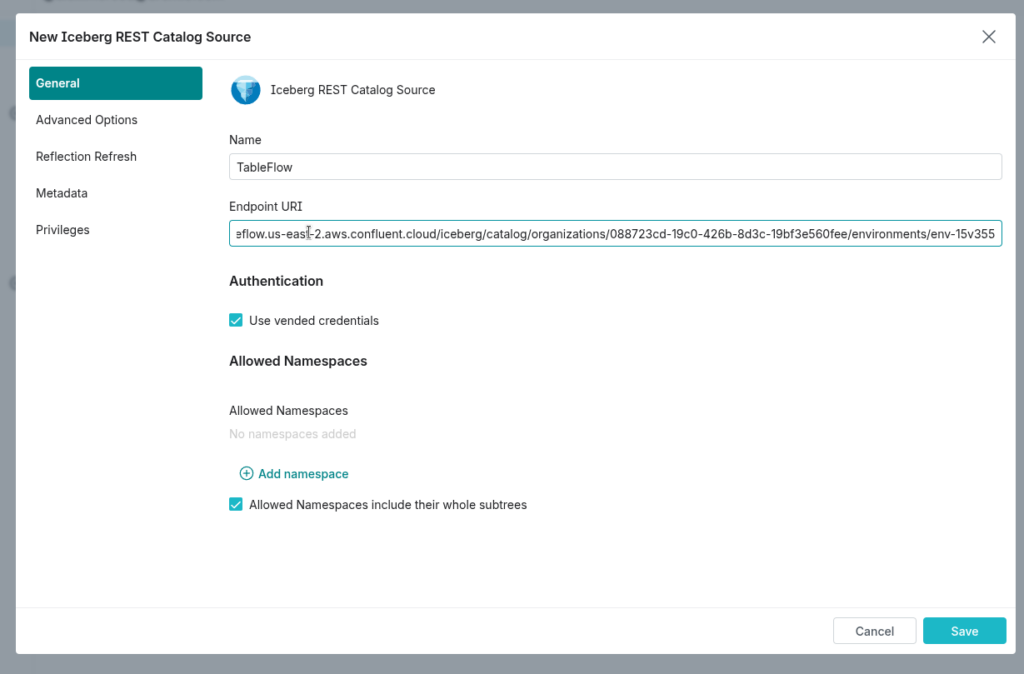
Step 2: Configure the General Settings
On the General Settings tab:
- Name the source something descriptive (e.g.,
confluent_iceberg). - Paste the REST catalog URL—you can find this in the Monitor tab of the Kafka topic’s detail page in Confluent Cloud.
- Leave “Use vended credentials” checked.
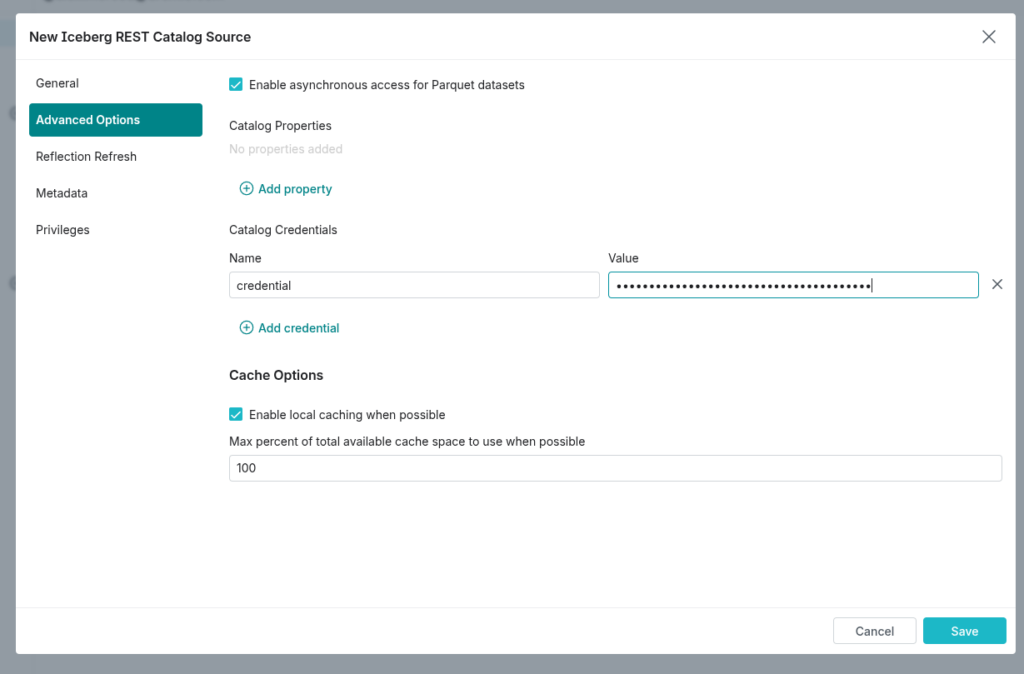
Step 3: Configure the Advanced Settings
Navigate to the Advanced Options tab and add one credentials property:
- Key:
credential - Value:
"API_KEY:SECRET_KEY"
(Use the API key and secret key from your Confluent Cloud cluster, separated by a colon.)
Step 4: Save and Explore
Click Save. Dremio will connect to your Iceberg REST catalog and automatically detect all available tables created by TableFlow. You can now begin browsing the dataset tree, running SQL queries, and joining your streaming data with other sources—all from the Dremio interface.
👉 Click here to see a full demo of the process.
Conclusion: Streaming Meets Open Analytics
Confluent’s TableFlow and Apache Iceberg unlock a powerful synergy: the ability to stream data from Kafka into open, queryable tables with zero manual pipelines. With Dremio, you can instantly access and analyze this real-time data without having to move or copy it—accelerating insights, reducing ETL complexity, and embracing the power of open lakehouse architecture.
By combining TableFlow’s simplicity with Dremio’s performance and self-service capabilities, you can build modern, scalable, and cost-effective data platforms that are ready for both operational agility and analytical depth.
Additional Resources

BLOG
Hadoop Modernization on AWS with Dremio: The Path to Faster, Scalable, and Cost-Efficient Data Analytics
Hadoop modernization on AWS with Dremio represents a significant leap forward for organizations looking to leverage their data more effectively. By migrating to a cloud-native architecture, decoupling storage and compute, and enabling self-service data access, businesses can unlock the full potential of their data while minimizing costs and operational complexity.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
Using Dremio, lakeFS & Python for Multimodal Data Management
With lakeFS, you version everything: Iceberg tables, images, models, logs. With Dremio, you query and analyze it all, structured or not, at scale. Together, they bring Git-style control and interactive querying to your data lake, so you can build more intelligent, version-aware workflows without sacrificing flexibility or performance.
Dremio Blog: Partnerships Unveiled,
Learn More ->

BLOG
What is ADLS Gen2 and Why it Matters
Described by Microsoft as a “no-compromise data lake”, ADLS Gen 2 extends the capabilities of Azure Blob Storage and is optimized for large scale analytics workloads.
Dremio Blog: Partnerships Unveiled,
Learn More ->