7 minute read · October 27, 2022
Puffins and Icebergs: Additional Stats for Apache Iceberg Tables
· Developer Advocate, Dremio

Puffin is here in Apache Iceberg
The Apache Iceberg community recently introduced a new file format called Puffin.

Hold on. We have Parquet, ORC. Do we really need another file format, and does it give us additional benefits? The short answer is Yes!
Until now, we had two ways of gathering statistics for efficient query planning.
- File formats like Parquet contain file, column (chunk), and page header metadata, allowing reading only a subset of columns and skipping possible rows within each data file.
- Iceberg table manifest files which hold column-level metrics for sets of files such as lower and upper bounds, NaN value counts, data size, etc. & partition information to select only the necessary files efficiently.
While file format like Parquet lets us skip rows based on the ‘footer,’ it would still require us to list out all the files present in a specific partition and look for non-matching records, which takes time at scale. Therefore, keeping column-level metrics in the table metadata (manifest) is also advantageous for query optimizers. Partition filtering, together with the column-level metrics in the manifest file, gives Apache Iceberg that ability to efficiently skip data files and select only the ones we need for a specific query. The engine can then look at Parquet footers in that subset of files to prune the data read even more.
Enter Puffin
As per the specification, Puffin is a file format designed to hold information such as statistics and indexes about the underlying data files (e.g., Parquet files) managed by an Apache Iceberg table to improve performance even further. The file contains arbitrary pieces of information called ‘blobs’, together with the metadata necessary to analyze them. As of now, blobs can be of the type: apache-datasketches-theta-v1.
Wait, what are blob types?
Blob types such as apache-datasketches-theta-v1 are produced by stochastic streaming algorithms and are commonly referred to as sketches. Sketches help queries that cannot scale due to the limited availability of compute resources & time to generate results. E.g., queries involving count distinct, quantiles, matrix computations, joins, etc. The sketch algorithm works by extracting information from a stream of data in a single pass. These approximated results are generally orders of magnitude faster. The sketch type currently supported with Apache Iceberg is generated using the Apache DataSketches library.

Why do we need Puffin?
Okay, so coming back to the point, why do we need a new file format?
Puffin lets us augment Apache Iceberg metadata with additional statistics or secondary indexes so we can do incremental work. For example, one of the first use cases of Puffin is to count the approximate number of distinct values (NDV) of a particular column of a table & supply it to the query optimizer. NDV is a critical piece of information that query engines can leverage for effective query planning on Iceberg tables. So, essentially, you can calculate the NDV for a column, produce a sketch and store it in the Puffin file format.
This is specifically important for cases such as join reordering on the part of query engines (think ten distinct values Vs. 1000). Typically, without sketches, you would have to read the entire table to calculate the values every single time. However, with the Puffin format, you can just read the table once, produce a sketch to be stored & incrementally update it. The size of these sketches can be pretty massive, which is why we cannot use file formats like Parquet or Avro to store them.
Additionally, this can be of immense value for users who want to do a faster computation of the number of distinct values and where there is a minimal impact when using the approximated values instead of the true ones. Some other applications of sketches in the Puffin format include users (such as data scientists) who can perform faster calculations like computing median, standard deviation, and average on huge tables.
What’s the format specification?
The Puffin format has the following specification.
Magic Blob₁ Blob₂ ... Blobₙ Footer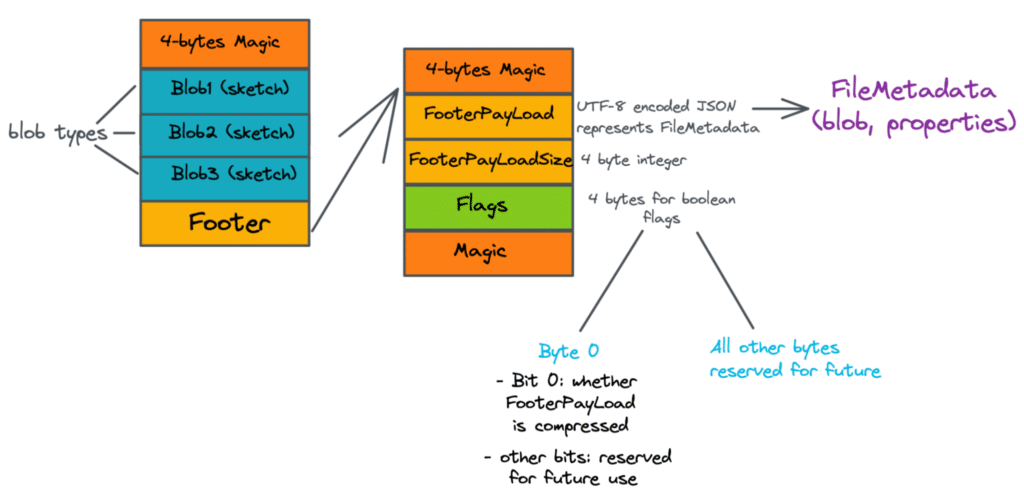
Conclusion
Puffin is in its very early stages and starts with one use case (NDV). However, in the future, we should see more advanced applications such as storing secondary indexes (e.g., bloom filters), which can get pretty size-heavy for individual values (order of megabytes). Ultimately the goal with Apache Iceberg is to let all the engines speak the same ‘language’ with respect to statistics & indexes that are imperative for better query planning, and Puffin opens up that avenue.
If you are looking to get started with Apache Iceberg, here are a few additional resources:
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->