As co-creators of Apache Arrow, here at Dremio it’s been really exciting over the past several years to see its tremendous growth, bringing more usage, ecosystem adoption, capabilities, and users to the project. Today Apache Arrow is the de facto standard for efficient in-memory columnar analytics that provides high performance when processing and transporting large volumes of data.
Apache Arrow’s growth
Since we co-created it in 2016, Apache Arrow's journey to becoming the “standard” for the columnar in-memory format has been fascinating to watch. One standout is its diverse application in today's data landscape for various analytical use cases. The project's growth has been on many axes, such as usage, ecosystem adoption, and capability. Let's take a look at some of these.
Arrow’s usage
Since Apache Arrow has diverse applications, its users are both direct and indirect. Software developers leverage Arrow to build high-performance applications specifically targeting data transport and interoperability aspects. Alternatively, there are data consumers who may not directly work with the format but have likely interacted with it under the hood with high-level libraries (such as Pandas, Spark, Streamlit, etc.).
As a surrogate for the usage of Arrow, we can see in the chart below the number of downloads of PyArrow from PyPI per month. PyArrow is the Python binding for Apache Arrow.
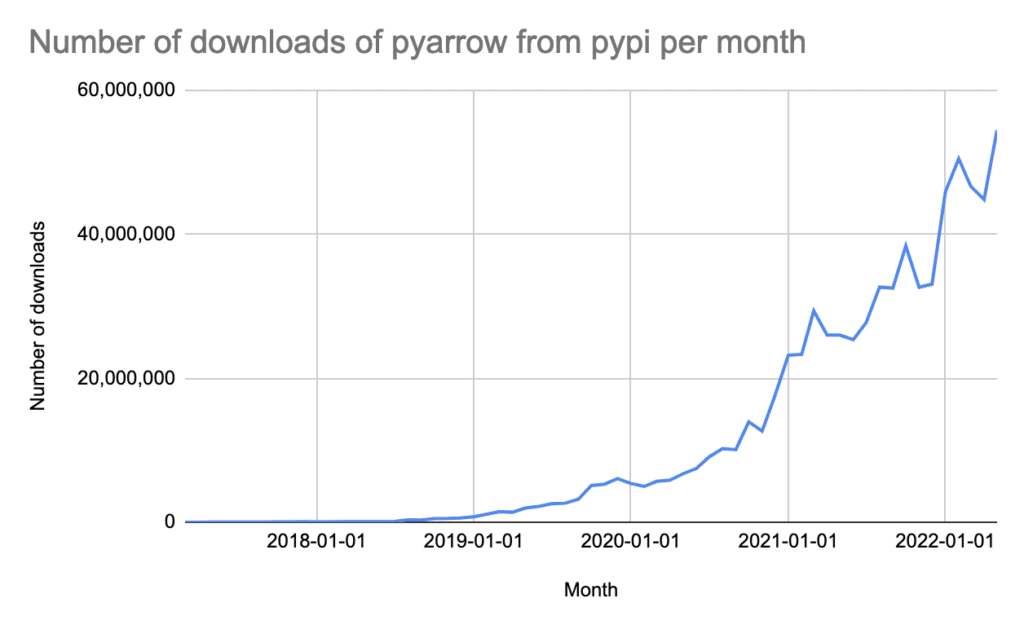
While this chart demonstrates Arrow’s impressive growth over the years, note that this actually undersells both the interest and use of Arrow since:
- This is only one language binding for interacting with Arrow (there are 11 others)
- This graphic only illustrates the public PyPI downloads data (there are other places to download PyArrow, such as Conda)
Arrow’s capability
From a capabilities perspective, Arrow has evolved quite a lot. What started as a format specification and a couple of basic implementations for interacting with that format, there are now many libraries and tools.
This growth has been genuinely community-driven, based on contributions from many individuals and organizations. The following details how the capabilities have grown over the years with some highly impactful projects.

- Arrow Flight, a high-performance data transfer framework, developed by Dremio, Ursa Labs (now Voltron Data Labs), and Two Sigma
- Arrow Flight SQL, a standard framework for interacting with databases via Arrow Flight, developed by Dremio
- Feather, a file format for Arrow, developed by Cloudera and RStudio
- Plasma, an in-memory object store for Arrow, developed by the RISELab at UC Berkeley
- Gandiva, a high-performance execution kernel for Arrow, developed by Dremio
- DataFusion, an in-memory compute engine for Arrow, developed by Nvidia, InfluxData & others
- Ballista, a distributed compute engine for Arrow, developed by Nvidia
Arrow’s ecosystem adoption
Arrow had grown tremendously in ecosystem adoption, in technologies created both before and after Arrow existed. When new tools or libraries decide how to handle data in memory and for transit, they often choose Apache Arrow, such as Google's BigLake, RISELab's Ray, and DuckDB. Technologies created before Arrow's existence are also choosing to introduce Arrow into their stacks, such as Apache Spark, Snowflake, and Amazon Athena. These adoptions prove that when people are deciding which memory format to use for data, they most often choose Apache Arrow.
Regardless of the programming language, leveraging Arrow has also gotten easier over the years. There are now 12 language bindings: C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby, and Rust. The applications range from doing I/O with columnar storage formats (e.g., Pandas uses it to read Parquet effectively) to building query engines (e.g., Dremio's in-memory representation of data), etc.
Community contributions
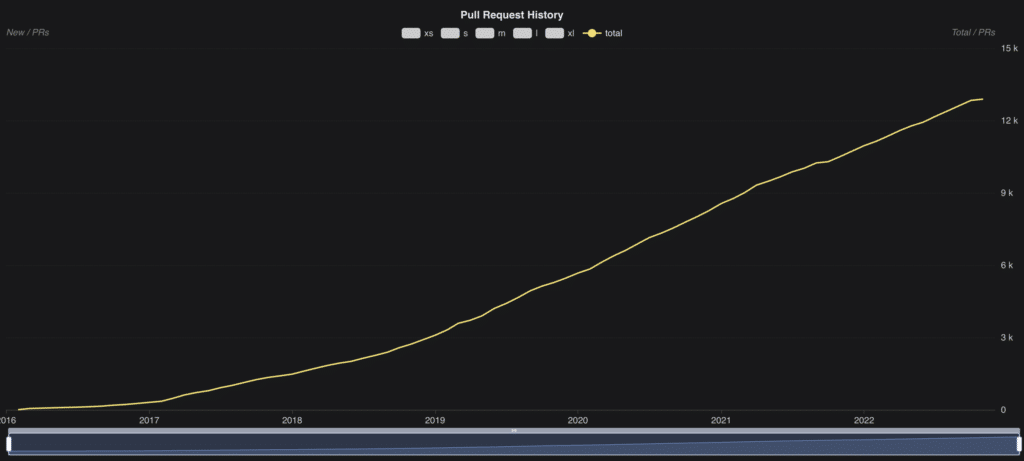
The Arrow developer community has also grown significantly. The project today has over 700 individuals with ~67 committers. The number of pull requests over the years has been monotonically increasing as illustrated in the graph below. This represents the overall pace and growth of this community-driven project with respect to adding new features or fixing existing issues.
As an Apache foundation project, Arrow brings clear governance and transparency to the project so the decisions can be made unanimously. The project also has great diversity with contributions from various organizations. Read more about how you can contribute to Apache Arrow here.
Conclusion
There is no doubt that Apache Arrow will continue to be leveraged by existing sets of tools as well as newer ones in the data space. As we move toward a world where efficient and faster data processing is critical, we will see more and more systems speak “Arrow” to avoid data transport costs, making data objects interoperable between systems. If you are interested in reading more about the origins and history of Apache Arrow and how it fits in today’s data landscape, check out this write-up.

