6 minute read · September 30, 2021
Will Apache Arrow Flight SQL replace ODBC and JDBC for Analytics/BI workloads?
· Data Architect, Dremio
Most popular BI tools rely on ODBC or JDBC to bring data in from where it resides. For example, Microsoft Power BI relies mostly on ODBC, Tableau relies on both, Looker relies on JDBC, and Qlik relies on both depending on the product. This has worked well enough, mostly because both standards have been around for a long time and have inertia behind them. In many ways, however, these standards are tolerated rather than embraced by developers. There’s a reason ODBC has been referred to as Other Developers Buggy Code.
Both standards were created at a time when cloud computing and SaaS didn’t exist and databases were primarily on-premise, monolithic programs. To scale your database, you bought a bigger, more powerful computer. Data size was more often measured in gigabytes rather than terabytes (or more), and parallelism wasn’t much of a consumer topic at all.


Times have obviously changed, and yet developers still struggle with the constraints these APIs place upon them, such as:
- A limited set of data types
- Sequential data access
- Inflexible connection/authentication methods
- Version mismatches
- Reliance on proprietary closed code
Apache Arrow Flight SQL aims to remove these constraints by bringing data access into the modern age. It does this by leveraging:
- Apache Arrow to reduce the SerDe costs (by over 80%) that are endemic within most, if not all, data connectivity solutions used today.
- Apache Arrow Flight’s built-in support for parallelism, meaning that it can take advantage of modern architectures where there are clusters of machines involved in data processing in parallel instead of a single monolithic machine.
- gRPC/HTTP2 as the underpinning for a more modern, performant transfer protocol allowing for streaming of the data, along with backpressure signals to avoid overloading clients.


In the transition from today's state, Arrow Flight SQL will have common ODBC/JDBC clients built on top of it, allowing existing tools to ship with a single Flight ODBC or Flight JDBC driver that works with all Flight enabled servers. This is in contrast to the status quo which is one custom driver per data source, leading to bloat and maintenance nightmares for those maintaining the applications. However, because these are built upon the common framework of Arrow Flight SQL, applications will be free to migrate to the native interface for Arrow Flight SQL when they are ready to make use of the power of Flight directly.
As a trivial example, a hosted BI solution with multiple nodes involved in processing incoming data, would be well suited for Arrow Flight’s support for multiple endpoints of data retrieval. Arrow Flight SQL provides the common method to describe the data source and execute queries using SQL.
One other superpower for Arrow Flight SQL is that there only needs to be a single client for each BI tool, which means only one implementation is required to maintain and test. That single Arrow Flight SQL client can talk to every Arrow Flight SQL enabled server, which means less dependency bloat, less maintenance, and less security risk. Couple this with the fact that Apache Arrow is open-source, means that you are free to work with the community to further improve Arrow Flight SQL and also the fact that you’re able to leverage the work of others, and it becomes the obvious choice to replace our existing legacy standards.
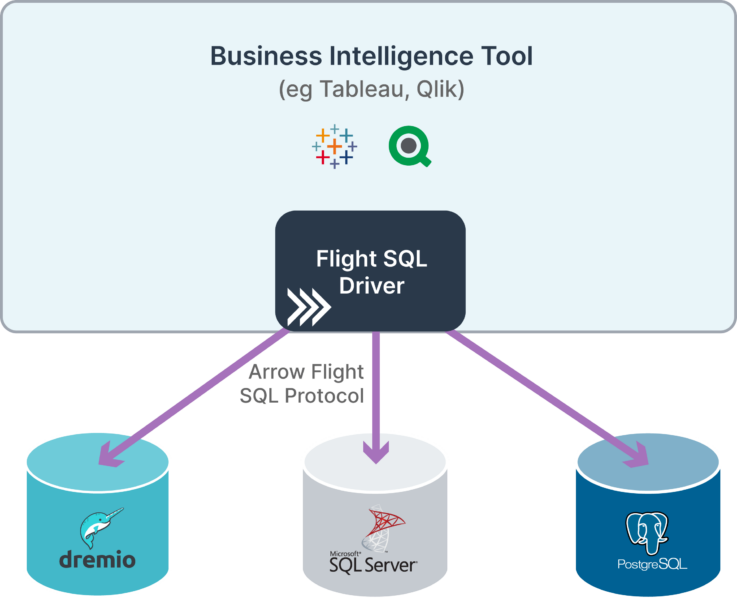
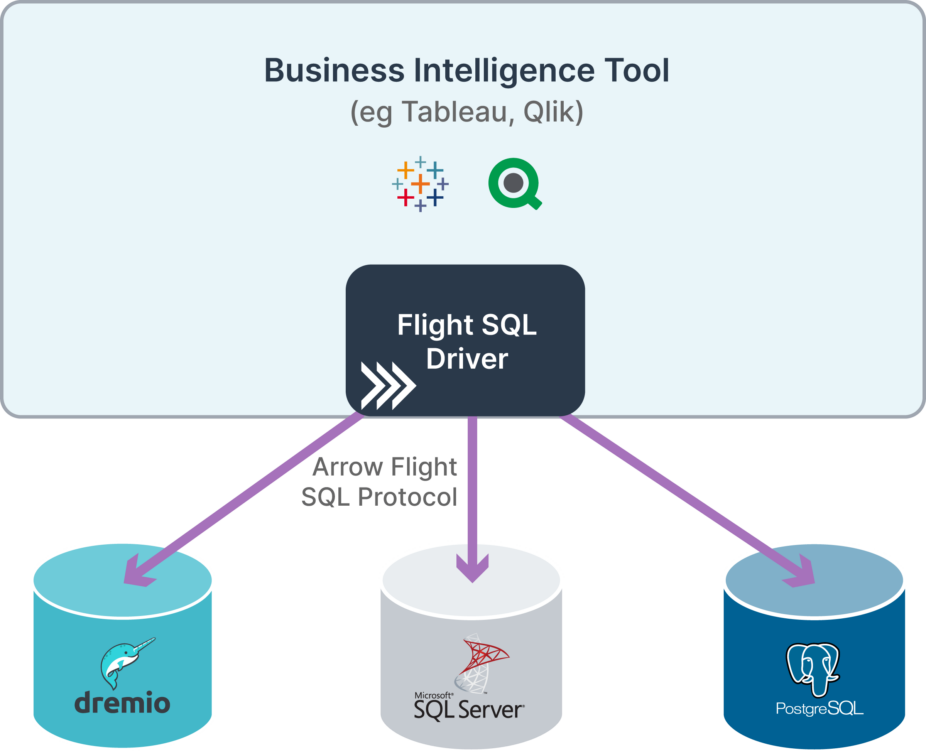
With better performance, better scalability, less bloat, more openness and robustness and less licensing, the question is now: Why haven’t you started to explore Apache Arrow Flight SQL?
Learn More
To learn more about Arrow Flight SQL watch the Arrow Flight and Arrow Flight SQL Accelerating Data Movement video from Subsurface LIVE. You can also follow the status of the Flight SQL pull request on Github. To learn more about Apache Arrow and ways to contribute to the project, checkout the Apache Arrow documentation.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->