37 minute read · December 15, 2017
Dremio 1.3 – Technical Deep Dive
Webinar Transcript
Kelly Stirman:
I’m joined today by Ron Avnur, our VP of Engineering.Ron Avnur:
Hi everybody.Kelly Stirman:
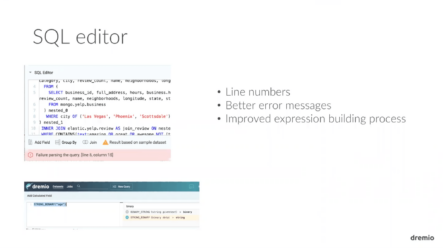
We’re both just going to try and keep this kind of a fun, casual conversation to talk about all the features and what’s in 1.3 and what’s coming in the next release.To summarize what we’re going to talk about, there are … One of the things in Dremio is a SQL editor that, in my opinion, has been not as nice as it could be in the past. And what you see in 1.3 is an all-new SQL editor that adds a few new features, but really the big change here is laying the foundation for us to continue and make the SQL experience better and better. What we really want is a world-class experience, and so this is the first step in that direction. Next is an all-new REST API. This is another example where this is not everything we plan to do, it’s the first few steps. Eventually, we want you to be able to do everything by REST you can do through existing interfaces. We set [inaudible 00:04:57] enhancements to query profiles to help you better understand what’s going on in the query planning. To help you bug situations and figure out, in some cases, how to improve on your reflection strategy.We’ve expanded reflection coverage, so a broader range of queries can take advantage of reflections. And that’s something we’ll always do in every release. We added the ability for you to download data as Parquet from Dremio and also to use Tableau on a Mac with Dremio. You could, before, use it but it wasn’t as streamlined and it wasn’t as nice as an experience as you have on Windows now. Windows and Mac, have parity. Then, a new utility to do some maintenance on Dremio’s metadata store.So, let’s talk about each of these in a little bit more detail. First of all, if you haven’t seen it, this is what the new SQL editor looks like. You can see over to the left that there are line numbers and things are indented automatically in a nice way, things are color coded. If you look at the error in this case below it says, “Failure parsing the query line 8, column 15.” Well if you look at line 8, you can see exactly where it says, “Where city of” and then there’s a sequence of strings, and that should be “Where city in”. So you’re able to much more easily figure out exactly where an error is. I think there’s more we can do here, of course, but this is I think a big improvement on where things were before.
Next is an all-new REST API. This is another example where this is not everything we plan to do, it’s the first few steps. Eventually, we want you to be able to do everything by REST you can do through existing interfaces. We set [inaudible 00:04:57] enhancements to query profiles to help you better understand what’s going on in the query planning. To help you bug situations and figure out, in some cases, how to improve on your reflection strategy.We’ve expanded reflection coverage, so a broader range of queries can take advantage of reflections. And that’s something we’ll always do in every release. We added the ability for you to download data as Parquet from Dremio and also to use Tableau on a Mac with Dremio. You could, before, use it but it wasn’t as streamlined and it wasn’t as nice as an experience as you have on Windows now. Windows and Mac, have parity. Then, a new utility to do some maintenance on Dremio’s metadata store.So, let’s talk about each of these in a little bit more detail. First of all, if you haven’t seen it, this is what the new SQL editor looks like. You can see over to the left that there are line numbers and things are indented automatically in a nice way, things are color coded. If you look at the error in this case below it says, “Failure parsing the query line 8, column 15.” Well if you look at line 8, you can see exactly where it says, “Where city of” and then there’s a sequence of strings, and that should be “Where city in”. So you’re able to much more easily figure out exactly where an error is. I think there’s more we can do here, of course, but this is I think a big improvement on where things were before. The other place that you would see some of the changes is if you go in to do something like build a calculated field, if you double-click on … In that case, if you had done a calculated field on a column called age and you double clicked on age in this dialogue, it would highlight age and then you can go over to the right and search all of the SQL functions that Dremio supports and there’s thousands of them. It’s nice to have that be searchable.Here, in this example, I was searching on binary and I see binary string, string binary, and if you click the plus by a string binary then it takes age and wraps it with that function call. It’s a nicer experience there and again this is another example of something where it’s the first step and we’re gonna continue to make it nicer.Anything you want to add on this?Ron Avnur:
The other place that you would see some of the changes is if you go in to do something like build a calculated field, if you double-click on … In that case, if you had done a calculated field on a column called age and you double clicked on age in this dialogue, it would highlight age and then you can go over to the right and search all of the SQL functions that Dremio supports and there’s thousands of them. It’s nice to have that be searchable.Here, in this example, I was searching on binary and I see binary string, string binary, and if you click the plus by a string binary then it takes age and wraps it with that function call. It’s a nicer experience there and again this is another example of something where it’s the first step and we’re gonna continue to make it nicer.Anything you want to add on this?Ron Avnur:
No, that’s pretty good.Kelly Stirman:
Cool. Next thing is REST API. This first step in the REST API is about adding control for data sources. Here are the basics that you can do. You can … Funny, it says crud but these are not crud operations on the data. They’re crud operations on your datasets I guess or in your sources. You can list all your sources, which would allow you to build a dialogue. Then somebody can go and pick a source if they want. You can update the configuration for a given source, you can delete a source, create a new source. Just the beginning here and in our documentation you can see basically what the model is, the JSON for describing the changes that you want to make to your data sources.There’s things that aren’t in this release are being able to create reflections, being able to issue a SQL query and lots and lots of other things, which is really just the first step, which is letting you control your sources.Ron Avnur:
You can list all your sources, which would allow you to build a dialogue. Then somebody can go and pick a source if they want. You can update the configuration for a given source, you can delete a source, create a new source. Just the beginning here and in our documentation you can see basically what the model is, the JSON for describing the changes that you want to make to your data sources.There’s things that aren’t in this release are being able to create reflections, being able to issue a SQL query and lots and lots of other things, which is really just the first step, which is letting you control your sources.Ron Avnur:
Yeah, this is step one. You need to be able to manage datasets. You need to be able to manage reflections, arbitrary queries, and basically, we want everything you can do in the UI to be able to do via the REST API as well is the way we look at it. The UI today uses a REST API underneath the covers to talk to the system. In building the UI, we learned a lot about what the interactions should be, so we’re using that to inform a much better API for public use.Kelly Stirman:
Cool. As a reminder, of course, you could still … There’s a lot of things you can do using SQL over JDBC or ODBC. REST is a new API that we’re excited about.Okay, next. Enhancements to query profiles. When you run a query in Dremio, we track that as a job in the system. If you go to the jobs tab, you can see history of all the jobs. You can search the jobs, filter them down, and on any given query, we have one of the things that on any one of those jobs, we track the query profile. This is where you can get rich information about how the query was executed in the system. Before 1.3, I would say it was fairly mysterious what was going on behind the scenes in terms of reflections. What we’ve done in this release is really add a bunch of information to help you better understand what is going on [inaudible 00:10:33].This is one quick screen grab that I pulled this morning off of a query I was running in the system where there were actually multiple reflections that had been created relative to a common physical dataset. These were all based on data. It was an Elasticsearch and a couple other sources. You can see here that this query was accelerated and it was accelerated by a reflection that had a specific name. In this case, I hadn’t named it anything so it just says unnamed reflection, but you can name your reflections. That can be useful in a lot of ways.That reflection in the top that was used to accelerate this query is associated with, it’s anchor dataset Sugarloaf, which is the name of the space, I guess because I’m thinking about going skiing, and a virtual dataset called Good Business. You can see, there was another reflection, an aggregation reflection, that matched but was not used to accelerate this query. It matched in that it was also associated with this same anchor dataset, but it was not as appropriate for the given query as the one that was chosen. Then, you can see a third one that was associated with a different dataset, USAA.Good Business and that one also matched but was not chosen.This can help you understand what’s going on in terms of the query planning process as Dremio is finding the best reflection to use for a given query. You also can see how old the reflection is that was selected, which can be pretty useful and important in some cases.I don’t know Ron, is there anything else you want to say about this in general before-Ron Avnur:
Before 1.3, I would say it was fairly mysterious what was going on behind the scenes in terms of reflections. What we’ve done in this release is really add a bunch of information to help you better understand what is going on [inaudible 00:10:33].This is one quick screen grab that I pulled this morning off of a query I was running in the system where there were actually multiple reflections that had been created relative to a common physical dataset. These were all based on data. It was an Elasticsearch and a couple other sources. You can see here that this query was accelerated and it was accelerated by a reflection that had a specific name. In this case, I hadn’t named it anything so it just says unnamed reflection, but you can name your reflections. That can be useful in a lot of ways.That reflection in the top that was used to accelerate this query is associated with, it’s anchor dataset Sugarloaf, which is the name of the space, I guess because I’m thinking about going skiing, and a virtual dataset called Good Business. You can see, there was another reflection, an aggregation reflection, that matched but was not used to accelerate this query. It matched in that it was also associated with this same anchor dataset, but it was not as appropriate for the given query as the one that was chosen. Then, you can see a third one that was associated with a different dataset, USAA.Good Business and that one also matched but was not chosen.This can help you understand what’s going on in terms of the query planning process as Dremio is finding the best reflection to use for a given query. You also can see how old the reflection is that was selected, which can be pretty useful and important in some cases.I don’t know Ron, is there anything else you want to say about this in general before-Ron Avnur:
Yeah, so in general, a large part of what drove adding this feature was feedback from the user community in general. We were getting feedback that when a query was slow, it was difficult to determine very easily did it use a reflection or did it miss it and if it missed it, why? This is why we added this.You talked about the fact that the job’s page shows some important information about every single job and you’ll notice on the right-hand side, you can download the entire query profile, which is this JSON format with a wealth of information.What we’re showing you here is part of our ongoing roadmap iteration on adding more and more of the most useful information in a much more consumable format to better understand what happened with a particular job. What were some of the decisions made by the system? Is there tuning that I should apply to better understand what is going on and get more information in a way that’s more consumable than scanning through a giant JSON object?We have a lot of the [inaudible 00:13:49] information and we’re improving its utility to you with every release.Kelly Stirman:
Yeah, the last point on this slide is that we’ve done a bunch to improve reflection coverage in 1.3.Do you want to say anything about the kind of pattern of data and queries that really applies to?Ron Avnur:
Yeah, in 1.3, you’re going to see some improvements related to window functions. There are some left outer join queries that were not getting accelerated before and so there’s this, for lack of a better phrase, a mixed bag of patterns that we saw in the wild that we made improvements to.One of the things that perhaps is a little bit better to describe as an opportunity for us for substitution in 1.4, is we’re looking a little bit ahead to the 1.4/1.5 time frame, is to look at star schemas and the ability to exclude parts of reflection as perhaps a query that uses a subset of a reflection can also be substituted. You’ll be seeing that and a little bit more on that.This is where helping us identify generalized patterns of kinds of queries that can leverage reflections that you’re seeing. Certainly, help us prioritize this. We’re going to be working on improving reflections for years. I see this as a giant opportunity for everybody and we think it’s important to separate the improvement in substitution and acceleration from the experience to the end user who doesn’t need to be aware of it. That’s why we keep investing in it.Kelly Stirman:
Yeah, this is an area where we love to hear from you on community.dremio.com. We love to answer your questions. There are cases here where the data may be sensitive or the query is going to be sensitive and we’re always happy to dialogue with you over email or on a phone call. If you have patterns you’re seeing that aren’t being accelerated that you want to talk about, we’d love to hear from you.Okay, the next couple are pretty easy. Now, if you are in a dataset there’s always been an option to download JSON or CSV, now you can also download Parquet. The limit on a million records is not new. That’s always been the case.Our goal with Dremio is that you don’t need to download data. That you run queries through Dremio and you’re not exporting or creating copies because that creates new kinds of problems and challenges. In some cases, you need to do this, so we had some requests that Parquet be a format for download and if it’s not clear, it doesn’t matter what the physical format is of the underlying data, the export is whatever you ask for. If you have data in a relational database and you want to download a million records to Parquet, the system will do that for you.We added some necessary capabilities in the UX so that now you can use Tableau on Mac with Dremio and Dremio’s ODBC driver and launching Tableau from Dremio. The way that works, if you haven’t done this, Tableau has a file format called .tde, like egg and another called .tds. The .tde is a Tableau extract. That’s actually a proprietary encoding of data that makes it so Tableau is much more responsive. That’s not what this is.A .tds is a configuration file that defines the ODBC connection from Tableau to a given data source. The way our integration works is when you click this Tableau button, it downloads a little .tds file with all the necessary configuration information you need so that when you click that .tds file from your desktop, it launches Tableau connected to that dataset and prompts you to authenticate Dremio.Prior to 1.3, if you were on a Mac, you couldn’t do this nice click a button and then launch Tableau connected to a dataset. Now, with 1.3 you can do that and you can do that with Dremio’s ODBC driver. This is dependent on Tableau 10.5.Ron Avnur:
I thought it was four.Kelly Stirman:
10.4. It’s in our release notes.Ron Avnur:
Yeah.Kelly Stirman:
Tableau on Mac did not support custom ODBC drivers until the past few months. There was also a Mac/Tableau dependency for this as well.Okay, the next thing in here is the new Dremio admin action, which is called clean. If you didn’t know this, there an administrative tool that lets you do a variety of tasks like reset the admin password, or do a backup of Dremio that is a command line tool. Unfortunately, at this time, that tool does not run on Windows, but it runs on Linux just fine, which is really the only OS we support for production.We added a new feature, a new action called clean, which gives you the ability to compact Dremio’s metadata store, to clean up orphaned objects in the metadata. We maintain job history for a configurable amount of time, but if you wanted to clear that out for some reason, ahead of a scheduled clean up, you can do that with the tool as well. Finally, you can re-index the metadata. Ron, when would somebody need to re-index the metadata?Ron Avnur:
Ron, when would somebody need to re-index the metadata?Ron Avnur:
This came out of working with a couple customers who are working at very big scale. They were connecting to multiple different data sources including some Hadoop. In this particular case, they were connecting via Hive to a large swath of data and so being able to underneath the covers accelerate the cleanup of our metadata store was useful to them.They were working with a 100-node cluster in the hundreds of terabytes of data. I don’t think it had quite hit a petabyte yet. Just thinking about the Hive, the tables, the partitions, and all of the metadata that we collect, there’s quite a bit of data. This was really useful to them.This was useful in a couple cases, so as you start to leverage Dremio a little bit more and grow your cluster, we’re also adding in more tools to better understand what’s going on underneath the covers and manage them in production at scale.Kelly Stirman:
Cool. Okay, so those are some of the highlights. Is there anything else that we didn’t cover, Ron or bug fixes that you think are especially relevant to most people?We’re just going to go back and quickly scan the-Ron Avnur:
Let’s see if there were any questions.Kelly Stirman:
… release notes as well. I looked at the questions. About half of you have done the poll. Again, really appreciate it if you can take a moment and respond to the questions on the poll.There’s one question I can answer now, which is what APIs are coming after the data source REST API? For example, one simple one is, “Hey, I want to issue a SQL query via REST.” That’s not something you can do with 1.3, but that’s something you’ll be able to do in the future.Another is creating virtual datasets. Another is creating and managing reflections. Another is creating and managing users. In my mind, the way I think of about this is if I wanted to script an end-to-end process where I stand up Dremio. I connect to a number of different data sources, then I programmatically look at the catalog and then go build some virtual datasets. That’s something I should be able to automate and do it entirely via the REST API.Those are the kinds of things we’re going to keep building out. It will not all show up in one release. We will, over the next several releases continue to add more and more capabilities via the REST API.If others have questions, please don’t hesitate to ask. There’s a Q&A feature in this tool that lets us track the questions and then answer them here during the call.Ron Avnur:
I’m curious if that actually answered the question that you were asking about so you can ask a follow-up question. I’d also love to hear, you can share it in the form of a question of what particular API you’re looking forward to. Hearing from the community, we all read through the community.dremio forums. Keep those letters coming.I guess we’ll wait a little bit. I just want to make sure that there isn’t an API that we’re missing. If there’s something that’s particularly more interesting, we can always juggle the schedule.Kelly Stirman:
Scroll back up a little bit to the very first question.Ron Avnur:
Yeah, okay.Kelly Stirman:
Ron, were there any bug fixes in 1.3 that you want to talk about?Ron Avnur:
Any bug fixes that I want to talk about …Kelly Stirman:
I know you feel bad about the bugs, but …Ron Avnur:
Yeah, every one makes me cry.You’re putting me on the spot. Let’s see, well, certainly the ones we talked about before around acceleration are always the ones that I think are high-value. If you take enough time to set up reflections, when they can substitute but they don’t, it really is disappointing.I’m just looking through the list of bugs in Jira. See if there’s any particular one that jumps out at me. Let’s see here.Kelly Stirman:
While you’re looking, if there isn’t one then that’s fine. There’s another question that came in via chat, which is the clean utility is only available in Linux, how far behind is something for Windows?Ron Avnur:
Probably a release or two. This is the first ping of interest in that particular utility on Windows because we have heard that demand on Linux, so that’s useful.Kelly Stirman:
The Dremio admin utility does a bunch of different things and it does come up from time to time on the community that folks want to use that with Windows. Heaven forbid you forget your admin password.Ron Avnur:
Yeah.Kelly Stirman:
It’s coming. It’s not in 1.3. It’s something we’re working on. The priority was production appointments, which, of course, is Linux.Ron Avnur:
Yeah.Kelly Stirman:
Okay, let’s jump to what’s coming in the coming soon area of Dremio. First of all, this is something I think is very exciting and very interesting, which is the concept of what we call external reflections. Let’s double click on that for a moment.Today, when you run a query in Dremio, there are two ways a query could be processed. First is, the query could be pushed down into the underlying source, whether that source supports SQL or not. Dremio can take your query and rewrite it in the language of the underlying source and augment the capabilities of that source. For example, if you wanted to do a join between two different indexes in Elasticsearch, which doesn’t support joins, well, you can still do that with Dremio because Dremio’s SQL engine will augment the capabilities the Elasticsearch provides.The second way the query could be run is that Dremio’s query planner evaluates the query and determines that there is a suitable reflection that can be used to execute the query. The determination of whether to use a given reflection versus pushing the query into the underlying source is based on the costs that are determined by the planner.Earlier when we were looking at the new query planner metadata that’s being displayed in the job history, you could see that there are multiple reflections that were considered that would actually match that particular query, but only one was used. Ultimately, the determination of which reflection was based on the costs.Today, those reflections are created by Dremio using our SQL execution engine and persist as Parquet in the file system. In a way, you could think of it as a CTASK process where I’m creating table as … When you define a virtual dataset, then that SQL expression is used and something like a CTASK whose output persists as Parquet on the file system.However, if you think conceptually I have some data that has been materialized that has a certain cost associated with the efficiency of executing a query, then there’s no reason that reflection necessarily would have to be Parquet. What if you could have a reflection that is a table in Oracle or an index in Elasticsearch? Or, any of the underlying data sources that we support. The idea is that the way that the reflection is created could be independent of Dremio.The first place that you might want to use this is if you have a really, really large dataset that you want to build a reflection. We saw this come up with some customers that had Hive tables in excess of a thousand columns and hundreds of billions of rows and the process of creating the reflection on that data was many hours in duration. Dremio’s fundamentally not designed to have multi-hour running processes. It’s a low-latency interactive system. We discovered in working with some of these very large deployments that Dremio’s engine … If a note fails in the middle or resources were starved, any number of things could cause the process to fail and then it would have to start all over again from scratch.The counter design to that is, of course, something like Hive, which is not very efficient but it is very, very good at getting the job done even when things fail in the middle. So, wouldn’t it be nice if in a Hadoop cluster, for example, I could use a Hive process to create the reflections and then take advantage of them in Dremio without having Dremio create the reflection? What we’ve done is coming after 1.3 is add this ability for you to take a dataset that you’ve created and say this is a reflection and describe what the contents of that reflection are. Register it in Dremio’s catalog so that the query planner can consider that external reflection when generating a query plan.Ron, is there anything you want to add to that?Ron Avnur:
Yeah, and apologies if I’m being a little bit redundant. One of the ways to look at it is at the same time as we were working with that customer, there was another one who talked about the fact that they had already created five or six different copies of the database with different sort orders and were instructing some of the users of the data to use this table in this case for certain kinds of analytics and use this other table with a different table name, even though they were all exactly the same data. Reminding everybody when to query which one was getting to be a pain.That was part of the hint that some of that work has actually already been done and so let’s help people leverage it and do the acceleration so that again, users of the system don’t have to know about what’s been accelerated and what’s been set up. They care about the data, the logical view as opposed to the physical view. Again, separating concerns between what is the logical dataset I’m worried about, which is what the analyst is working with, and separate that from doing the physical on disk representation. In this particular case, we have a couple folks who can use an index in Elasticsearch as a substitute especially when certain predicates are applied.Kelly Stirman:
One question here is related to this in particular. How effective are the joins between external reflections and non-external reflections?Ron Avnur:
… reflections. Well, the join itself will still be processed by Dremio. The efficacy will depend on the latency. If you have an external reflection on S3 for example, and another reflection in Dremio in Parquet file and the external reflection happens to be CSV, you can imagine that one of the two relations is a lot slower than the other. Those will be some of the implications, but that will still be possible.Kelly Stirman:
This is an area where when we add this to the product, we’ll have good documentation and some good examples of how and when to use external reflections. I think the main reason is for people that have some external processes already converting CSV to Parquet for example or is already sorting the data in a couple different ways or aggregating the data in a couple of different ways and they already made that investment. Can I just take advantage of what I’ve already done?Another question is, does that mean an RDD can be used as a reflection?Ron Avnur:
We haven’t done that here yet, but potentially, yeah.Kelly Stirman:
Yeah, it really just comes down to is it a source that Dremio supports and if so, you should be able to use it as an external reflection.Let’s proceed and go on to the next coming soon capability. I tried to keep these coming soons to the January to February timeframe. These are not things that are a year out, these are things that are coming in the next one to two releases.The next is continuing to build on what we’re doing in SQL. This is a mock-up of what we’re working on, but we want it to be … Again, we’re trying to make this SQL experience really, truly world-class. As you’re typing SQL, can the system suggest the names of objects based on who you are and based on popularity of what’s been accessed and can it help you get the syntax correct in terms of applying all these different, like I said before, thousands of SQL functions to transform the data?Here’s an example of a time stamp add function, the syntax, an example, and the various arguments that are valid for that particular part of the expression. I just noticed this right now, actually, that if you look, this function takes three arguments. The first is time unit, and if I look below, there’s a little triangle that’s pointing at the first one, which is where I am in building the expression. I have some context-sensitive help pointing me to year, quarter, month, day are valid arguments for the first argument in this expression.Ron Avnur:
While you’re on that topic, you asked a question earlier about some of the SQL stuff that you talked about at the beginning, asked me if there was anything I wanted to add. As you were talking just now, it reminded me of another little improvement that is near and dear to my heart. We wind up dealing with multi-lines, sometimes eight to ten lines long, if not longer than that, pretty long queries. The system today tells you if there’s an error in your query, it tells you the line number and a cursor position. I wind up having to copy and paste that an open it somewhere else in order to figure out exactly where the error is.One of the things that you’ll also see pretty soon is the highlighting of that error in context as opposed to just getting a column and row position. I know that’s a little thing, but it was-Kelly Stirman:
Every little thing helps.Ron Avnur:
Well, it’s just annoying when you get an error and you have to start searching for exactly the position. Certainly, something that you see in other IDEs that we just needed to catch up on.Kelly Stirman:
Yeah. Okay, next is coordinator high availability. Dremio, there are two types of nodes, exterior and coordinator nodes. If you’re running on your laptop, you have Dremio configured so it operates as both, but if you’re in a cluster, you’re probably going to have a few coordinator nodes, which is what you connect to to issue your queries. Then, typically many more execution nodes where those nodes are close to the data and they’re doing all the heavy lifting.Today, those coordinator nodes … There is metadata about the system that is stored with one coordinator node. If that coordinator node fails, the other coordinator nodes that you have cannot access the metadata and so the system becomes unavailable.The idea with this feature is that the failover from the master coordinator node to another master coordinator node is automated. This is dependent in this first iteration on Zookeeper and that you are running Zookeeper yourself. For a lot of folks that’s not an issue, you already have Zookeeper running in a Hadoop cluster and we’re going to take advantage of that Zookeeper deployment. If you don’t have one, then being able to take advantage of this capability means standing up in Zookeeper quorum and managing that yourself.We will guarantee that only a single master coordinator at a time is reading and writing from the metadata store. This is really about orchestrating the handoff between those multiple processes when in the event of a failure.Anything you want to add to that?Ron Avnur:
Yeah, so the fencing part is absolutely important. You want to avoid some false positives and accidentally having two masters writing to the same metadata store. That would be bad. The other is, yeah, it’s really important as people scale out their system, they’re scaling out the executors and there’s also scaling out the coordinators or the nodes that serve up the queries. It is important to note, ’cause I don’t know if everybody is aware of it, but, yes, that all the coordinators as they handle requests are all ultimately caching in memory the responses they get from that one metadata store that is in the master coordinator. That’s why having that failover capability that high availability for that master is extremely important.This is important to us and we prioritized it as there are a growing number of customers that are starting to put Dremio in production in an environment where there are hundreds if not thousands of different users using the system as the central place where they’re querying their important data sources. The owners of that system do not want to have to deal with downtime because of the cost to them of having to answer to all of those internal users.That’s a little bit of the rationale, probably not terribly surprising and hopefully a little bit of an explanation of what’s going on in a life of a query as it gets handled by one of the arbitrary coordinators.Kelly Stirman:
Okay, just a couple more things here. LDAP group membership via SQL. Wouldn’t it be nice to programmatically determine the output of a SQL expression based on someone’s LDAP group membership? One of the reasons for this is security. For example, based on your LDAP role, return the value, maybe mask the value in some way, or not return the value at all or return some message like, “Insufficient permissions.”Its member is a function that returns a Boolean. You pass in the name of the LDAP group and this is evaluated once per query. Dremio will cache the LDAP membership for the user issuing the query and then consider all of those in evaluating in this example, this case statement.In this example, if someone is a member of the executive group, then they see the full social security number. If they’re a member of the employee group, then they only see the last four digits and the preceding digits are masked with an X. Otherwise, they get a message that says, “Insufficient permissions.” That’s a really powerful and useful feature that I’m sure you guys will have fun exciting ways to use that for different things other than this simple example that I put together here. Next, we’re going to have beta-level connectors for Azure’s Blob store, Azure Data Lake storage, and Google Blob storage. Today, you can access data in S3. You can also persist your reflections in S3, which is really great. You, on the other hand, cannot do the same on Google Cloud.With this capability, which, again, will be beta in the January or February timeframe, you’ll be able to not only read data from the Google and Azure equivalence of S3, but you’ll also be able to persist your reflections in those file systems as well. Sorry, those object sources as well.That is it for the things that are coming soon. Actually, I think that was a pretty good list. Big, exciting things.There’s a couple of questions left I want to make sure we get to. Following up on the Dremio admin utility, there was a question about in general how far behind are the Windows GA releases? I want to be clear about this, when we ship Dremio, it’s the same for all of the operating systems. For Mac OS, for Windows, and for Linux in all its flavors, when we shipped 1.3 on Monday, it was the same for all of them.This is a standalone tool that is not the Dremio main process. It is a command line-based tool that lets you perform some admin operations. Maybe, one day those capabilities will just be part of Dremio, but the fact that that particular tool is not available on these other operating systems shouldn’t tell you that the core Dremio process is different across the operating systems. It’s the same for all three.The other question that was asked is does Dremio have a SQL connection that mimics Postgres so I can connect Dremio to any tool that already has a Postgres-like interface? One example is MetaBase. Thank you for this great software.You’re welcome. Glad you’re enjoying it. Actually, I was just getting ready to publish a blog on connecting Dremio to Greenplum, which uses the Postgres Wire Protocol. There’s no guarantee that … I don’t know MetaBase, but you should try it. You should basically create a new connection and choose the Postgres connection type and then enter in the necessary information to connect that source, even if it isn’t actually Postgres. Give it a shot. Let us know on community whether it worked or not and if it doesn’t work, we’ll see if there’s anything that you can do to change the configuration to make it work.Now, the next question I’m going to let Ron answer, which is do we support Elasticsearch 6.0?Ron Avnur:
Next, we’re going to have beta-level connectors for Azure’s Blob store, Azure Data Lake storage, and Google Blob storage. Today, you can access data in S3. You can also persist your reflections in S3, which is really great. You, on the other hand, cannot do the same on Google Cloud.With this capability, which, again, will be beta in the January or February timeframe, you’ll be able to not only read data from the Google and Azure equivalence of S3, but you’ll also be able to persist your reflections in those file systems as well. Sorry, those object sources as well.That is it for the things that are coming soon. Actually, I think that was a pretty good list. Big, exciting things.There’s a couple of questions left I want to make sure we get to. Following up on the Dremio admin utility, there was a question about in general how far behind are the Windows GA releases? I want to be clear about this, when we ship Dremio, it’s the same for all of the operating systems. For Mac OS, for Windows, and for Linux in all its flavors, when we shipped 1.3 on Monday, it was the same for all of them.This is a standalone tool that is not the Dremio main process. It is a command line-based tool that lets you perform some admin operations. Maybe, one day those capabilities will just be part of Dremio, but the fact that that particular tool is not available on these other operating systems shouldn’t tell you that the core Dremio process is different across the operating systems. It’s the same for all three.The other question that was asked is does Dremio have a SQL connection that mimics Postgres so I can connect Dremio to any tool that already has a Postgres-like interface? One example is MetaBase. Thank you for this great software.You’re welcome. Glad you’re enjoying it. Actually, I was just getting ready to publish a blog on connecting Dremio to Greenplum, which uses the Postgres Wire Protocol. There’s no guarantee that … I don’t know MetaBase, but you should try it. You should basically create a new connection and choose the Postgres connection type and then enter in the necessary information to connect that source, even if it isn’t actually Postgres. Give it a shot. Let us know on community whether it worked or not and if it doesn’t work, we’ll see if there’s anything that you can do to change the configuration to make it work.Now, the next question I’m going to let Ron answer, which is do we support Elasticsearch 6.0?Ron Avnur:
Good question. We’ve had this one come in a couple of times. We are still in the QA and fixing phase for Elasticsearch 6.0, so I can actually tell you authoritatively that 1.3 will not fully work with ES 6.0 unfortunately. There are a couple of changes that have come out that will require us to make a couple of fixes.That’s ultimately the challenge for us. MongoDB 3.6 came out yesterday or the day before-Kelly Stirman:
This week.Ron Avnur:
… this week.Kelly Stirman:
I guess the follow-up question is, does that mean they have to wait for one 1.4 or 1.5 or is that something you might address in our point release?Ron Avnur:
We may issue a patch if it turns out that the fixes to get ES 6.0 working are light enough and the blast radius is small enough. For example, you may notice that 1.3.1 is available shortly after 1.3.0 because we made a … One of the small fixes that went into that was addressing content type requirements, that Elasticsearch 6.0 is a little bit more strict on. It was part of starting the work of Elasticsearch 6.0.Yeah, we try to keep up. There are a multitude of different sources that we need to maintain in the matrix. One of the things we need to do, we need to make clear for everybody is, which versions of each of these sources are supported, which ones are coming soon. If so, how soon. I don’t have a great timetable yet for Elasticsearch 6.0, but we’ll try to get it by January or so at the very latest. Again, it depends on looking at a couple QA runs before I give a very firm date.Keep letting us know on the community. That helps us prioritize these things. Yes, if anyone’s going to ask a question about Mongo, we’re already aware of Mongo 3.6 and it is not supported yet.Kelly Stirman:
That’s everything for just now. If anyone hasn’t completed the poll, it just takes a moment. Really, really appreciate the feedback. It helps us enormously. If anyone has any other questions, now’s a good time to ask. Otherwise, we will wrap things up, give you back a few minute of your day. Thanks for joining us.If this was a useful thing to do, love to hear that. It’s the first time we’ve done this for a release. If it seems like a good thing, let us know and we will keep doing them for future significant releases.Appreciate it. Hope you guys have a great day. Thanks for joining us. See you out there. Bye-bye.
Sign up for AI Ready Data content




