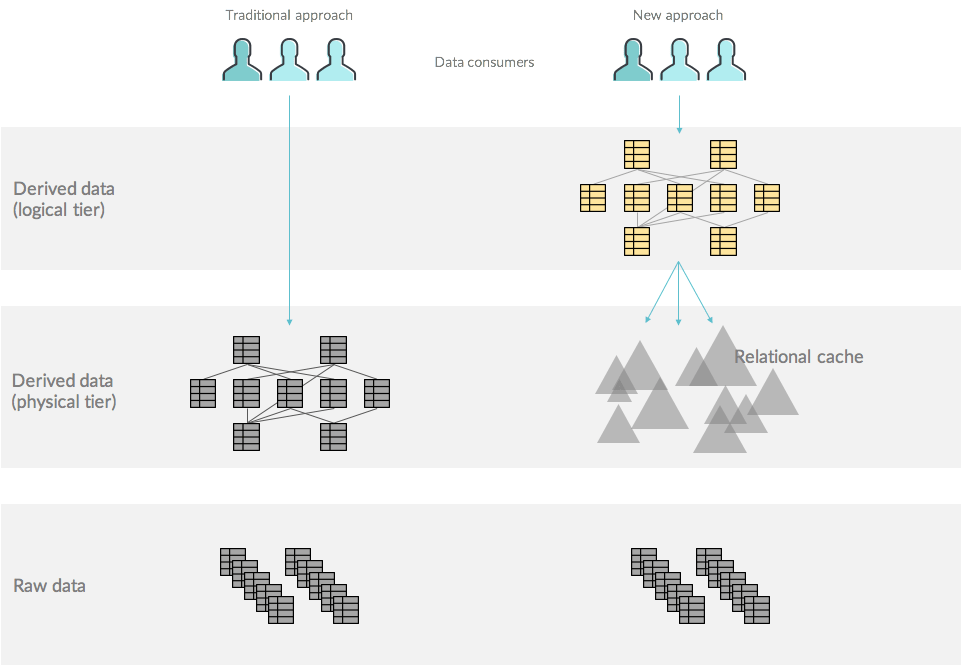
Given the diverse needs of different data consumers in an organization, it is impossible for organizations to settle on a single, golden representation of their data in a data warehouse. Even when a centralized data warehouse exists, there is a need for different representations of that data for different use cases and users. As a result, data is often extracted and copied from the centralized data warehouse into data marts, BI servers, cubes, aggregation tables, spreadsheets and other representations of data. The rise of the data lake has made it easier to load data into a centralized repository, but has only exacerbated these challenges by relaxing data modeling requirements and facilitating even more data copies through technologies such as data prep tools and frameworks such as Spark and MapReduce.
Dremio addresses this challenge by introducing a logical data layer, enabling users to create and share virtual datasets without incurring the costs and risks associated with physical data copies. Virtual datasets are derived from physical datasets or other virtual datasets, and are defined via a SQL SELECT statement. Ultimately, by “expanding” all the virtual datasets recursively, any virtual dataset can be represented internally as a query plan (i.e., relational algebra) on one or more physical datasets (e.g., Parquet files, Oracle tables, directories of CSV files on S3, Elasticsearch indices/types, MongoDB collections, etc).
Behind the scenes, invisible to end users, a relational cache comprising data materializations, also known as Data Reflections™, enables Dremio to accelerate queries from users and tools. While Dremio’s optimizer can always “push down” queries to the underlying sources, Data Reflections provide optimized data structures that are more efficient for analytical queries. The following illustration outlines the separation of the logical and physical tiers. The triangles in the relational cache represent Data Reflections.
In this approach, queries from users may reference virtual datasets (represented by the yellow tables in the logical tier). The Dremio optimizer is responsible for rewriting the query plans, when possible, to leverage Data Reflections to reduce the overall cost of executing the query.
A Data Reflection is essentially a specific materialization of data and the query plan defining that materialization. For example, the query plan could be the equivalent of the SQL query “select customer, sum(amount) from purchases”. When Dremio receives a query from a user, the optimizer considers the query plans of the data reflections in the relational cache to determine whether it is possible to substitute part of the user’s query plan with a Data Reflection in order to reduce the query cost (i.e., reduce execution time) while, of course, maintaining the same results. This capability allows Dremio customers to observe performance improvements of more than 1000x on many workloads.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Turbocharging reflections via learning
Dremio 2.0 includes a new learning engine that enables the system to become smarter as it sees user queries and observes the data flowing through the system. For example, rather than expecting an administrator to provide details on the relationship between datasets (e.g., fact-dimension), the engine can automatically learn these relationships and leverage them for broader reflection matching or enhanced transformation recommendations. In the following section we drill into one example of how Dremio can now learn from the data to improve reflection matching and potentially reduce the number of reflections to achieve the desired query performance by orders of magnitude.
Starflake reflections
A starflake reflection is a reflection that joins multiple physical datasets in which some or all of the joins are “record-preserving” joins.
Record-preserving joins
To understand record-preserving joins, let’s look at a simple example with four datasets that can be joined together.
In this example, the reviews dataset contains business reviews, each linked to a user (in the users dataset) and a business (in the businesses dataset). The businesses dataset contains the businesses, each linked to the state (in the states dataset) in which the business resides. Notice that for every single review, there is exactly one matching business and one matching user. In addition, for every business, there is exactly one matching state. When joined, the resulting four-way join therefore contains exactly one record for each of the original records in the reviews dataset:
We call this a record-preserving join because, conceptually, each of the original review records can be identified in the resulting dataset. In other words, the join is effectively just adding columns to the reviews dataset.
Note that record-preserving joins are very common in data warehousing (where there is often a fact table and multiple dimension tables). In the preceding example, the reviews dataset is a fact table, while the other datasets are dimension tables. If the dimension tables are denormalized, the schema is called a star schema. If the dimension tables are normalized, as in the preceding example, the schema is called a snowflake schema. If some dimension tables are denormalized and some are normalized, the schema is called a starflake schema.
Note that we use the term starflake in “starflake reflections” loosely. In fact, we consider any reflection that consists of at least one record-preserving join to be a starflake reflection.
Identifying starflake reflections
Any time Dremio executes a join, it records whether that join was a record-preserving join. An outer join is a record-preserving join if the number of records in the resulting dataset is equal to the number of records in one of the original datasets. An inner join, on the other hand, is a record-preserving join if every record in one of the original datasets was matched in the join, and the number of records in the resulting dataset is equal to the number of records in that same original dataset. Note that a join can be record-preserving in one direction or both (or not at all).
If a reflection creation job consists of one or more record-preserving joins, the system considers the reflection to be a “starflake reflection”. There is no need for a user to explicitly designate fact and dimension tables, or indicate that a join is record-preserving.
Note that a starflake reflection may include various operators in addition to joins. For example, an “aggregation reflection” could be defined as:
SELECT user_id, user_name, state_name, COUNT(*)
FROM reviews, users, businesses, states
WHERE reviews.user_id = users.user_id AND
reviews.business_id = businesses.business_id AND
businesses.state_id = states.state_id
GROUP BY user_id, user_name, state_name
Utilizing starflake reflections
Starflake reflections can be utilized by the Dremio optimizer to accelerate queries that include the dataset in the starflake reflection whose records were “preserved” by the joins (e.g., the fact table in a star/snowflake/starflake schema). For example, the preceding example reflection could help accelerate the following user query:
SELECT user_id, user_name, COUNT(*)
FROM reviews, users
WHERE reviews.user_id = users.user_id
GROUP BY user_id, user_name
In this example, the query joins a subset of the tables involved in the dataset with the starflake reflection (users and reviews, rather than users, reviews, and businesses). Dremio’s optimizer can determine the starflake reflection can be substituted in this query plan, and can use this reflection to accelerate the query. This is unique and powerful capability as there are potentially very large numbers of variations of queries that can be accelerated from a single starflake reflection.
Starflake reflection matching algorithm
Dremio utilizes a number of algorithms to identify whether or not it can rewrite a query plan to utilize an existing starflake reflection. One of these algorithms is a multi-phase algorithm that first determines whether to consider a reflection, and then determines whether it’s an actual match. The algorithm includes the following steps:
Receive the query from the user (e.g., via a BI tool)
Compile the user query to a query plan
Expand all virtual datasets so that the user query plan contains only physical datasets
For each reflection in the relational cache (i.e., the reflection store):
If the reflection plan does not have at least one physical dataset in common with the user query plan, drop the reflection from consideration and move on to the next reflection (step 4)
Prune physical datasets that are connected through a record-preserving join from the reflection plan until all the remaining physical datasets in the reflection plan are among those referenced in the user query plan.
Determine whether the user query plan can be rewritten to utilize the pruned reflection, and whether that would reduce the cost of the query
The pruning algorithm in 4b repeatedly considers leaf datasets in the graph (i.e., the reflection plan), removing those that are not included in the user query plan and are connected through a record-preserving join. For the previous example, the iterations of the pruning algorithm would look like this:
This is easy to understand when you consider the meaning of a record-preserving join, because the pruning algorithm is effectively just dropping some of the columns in the extended table:
How join types affect starflake reflections
In some cases it’s important to choose a specific type of join in order to ensure that a join is record-preserving. For example, let’s assume our states dataset in the previous example only had a single record - CA but not NV. In that case, an inner join between businesses and states would result in one of the records in the reviews dataset being missing from the reflection. The consequence is the matching algorithm would not be able to prune the states (or businesses) datasets from this starflake reflection (as an aside, it’s still considered a starflake reflection, because the users dataset is prunable).
In this example, a simple way to address the issue is to replace the inner join with a left outer join. By doing that, the record for business_id=3 in the businesses dataset would be preserved, and along with it the record for review_id=4 in the reviews dataset.
Dremio’s optimizer will soon be able to perform inner joins on starflake reflections that are based on outer joins. A reflection with an outer join can be utilized by the optimizer to accelerate a query with an inner join by applying a filter on top of the outer join to drop records in which the join key on one side is null. This is important because BI tools often default to constructing inner joins when users work with their visual join interfaces.
Why starflake reflections matter
Prior to the invention of starflake reflections, the Dremio optimizer had no way of ignoring some of the datasets in a join reflection. In order to accelerate a query that joins the datasets A, B, C and D, there would have to be a specific reflection that joins those four datasets. However, that reflection would not be useful for accelerating queries on a subset of those four datasets.
Imagine an analytical use case involving one fact table and 20 dimension tables. In order to accelerate queries on that fact table and an arbitrary combination of dimensions, the system would have to maintain over one million different reflections! (220 = 1,048,576) With starflake reflections, only a single reflection is required, leading to a significant reduction in resources and complexity.
Other uses of runtime statistics
There are many ways beyond starflake reflection matching in which collecting runtime statistics will help Dremio become smarter. In particular, they can make the system more effective at matching reflections, autonomously creating new reflections, optimizing queries and recommending data transformations. Here are a few examples we are working on for future releases:
Autonomously creating new reflections. When determining which reflections to create, it helps to understand what the common workloads are. For example:
Are some fields highly correlated? That is, when grouping on a and b, is the total cardinality of the combination closer to the multiple or maximum cardinality of the two fields. If multiple fields are highly correlated, there’s little additional cost to including all of them rather than just one when creating an aggregation reflection.
Optimizing queries. For example:
Join statistics can help choose the optimal join algorithm. When two datasets are joined for the first time, the system may choose a suboptimal algorithm. But the next time that join executes, the system would make a better choice.
If all the values in a specific field are unique, a COUNT DISTINCT operation on that field is equivalent to the much less expensive COUNT operation.
Recommending data transformations. For example:
Record-preserving joins are, in a way, just like vlookups in Excel. If the system has previously observed a dataset being “extended” through record-preserving joins to other datasets, it could recommend those other datasets as possible lookups in the graphical user interface. In fact, it could recommend not only two-way joins, but also n-way joins involving multiple tables.
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.