One of the challenges that comes with operating a high performance lakehouse query engine is metadata management. A query planner needs certain information about tables when planning a query, such as schema, statistics, location, etc. However, unlike a traditional data warehouse that has full ownership of all aspects of the data, modern data lakehouses do not “own” the data. For table formats such as Iceberg, the data as well as the metadata for a table is typically stored in object storage such as S3 and is accessed through a centralized Iceberg Catalog that can be used by a variety of different tools.
One of the drawbacks with this is that getting table metadata can be a relatively slow process involving expensive network roundtrips to a remote catalog and possibly remote object storage. Now when you consider that it is not uncommon for a query on the lakehouse to scan dozens and even hundreds of tables, coupled with the fact that fetching the metadata for a single table can potentially take over 100ms, query performance can degrade very fast.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
The Caching Solution
So how would one solve this problem? If you said ‘with caching’, that’s exactly right. Most lakehouse query engines will use some sort of caching to take the slow network roundtrips out of the equation. And this is how Dremio has done it as well.
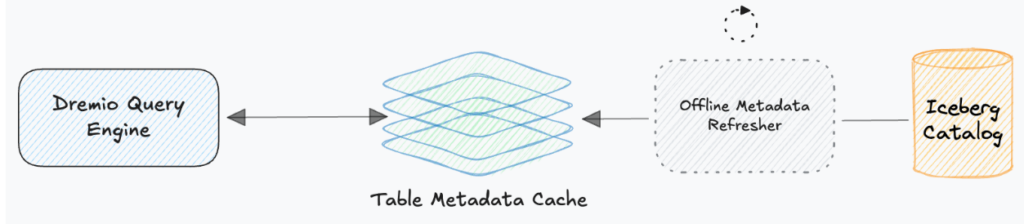
Dremio typically operates under an eventually consistent model where table metadata is periodically ‘refreshed’ in an offline process. The table metadata is fetched from the remote catalog and is then cached in fast storage. The advantage is obvious - lightning fast table metadata access that has negligible impact on query performance. The drawback - you might not see the latest updates to a table for up to an hour, maybe longer.
The Problem With Caching
For a lot of end users this model works great, but not all. An organization might have tables that are updated with high frequency and do not want to have to wait an hour to be able to query the new data.
So is there a way that we can facilitate this without absolutely murdering query performance? One potential solution is to simply increase the frequency that tables are refreshed. Instead of doing it every hour or couple of hours, we could instead refresh every minute. It’s still an eventually consistent model, but now a user only has to tolerate a minute of ‘lag’.
This approach has problems though. What if an organization has thousands of tables that are being refreshed every minute? This could consume a lot of resources on the query engine. Additionally, what if only some of the tables are updated with high frequency while others are not? It doesn’t make sense to refresh table metadata every minute for a table that maybe is only updated once a day.
That begs the question, why can’t every table have its own configurable refresh schedule? The problem with this is that it could be very difficult to determine the appropriate refresh schedules for each individual table. And we still run into similar problems when tables might have varying update frequencies.
So is there a reasonable solution to this problem? Can we guarantee that a user can query the latest version of their Iceberg tables while also keeping good query performance? And can we also do it in such a way that the user doesn’t even need to think about it?
Dremio’s Solution: Seamless Metadata Refresh
Dremio tries to solve this problem with seamless metadata refresh which is Dremio’s way of refreshing table metadata ‘just-in-time’ so that a query sees the latest version of a table while making a best effort to keep query performance reasonable.
How Does It Work?
When Dremio plans a query, one of the first things that it does is to validate the query tree and ensure that types match. As part of this process, it needs the metadata for each table in order to get the schema. As mentioned previously, it will typically fetch this metadata for each table one-at-a-time from an internal cache. When a table identifier is encountered, we request the metadata from the cache and then proceed with walking the query tree.
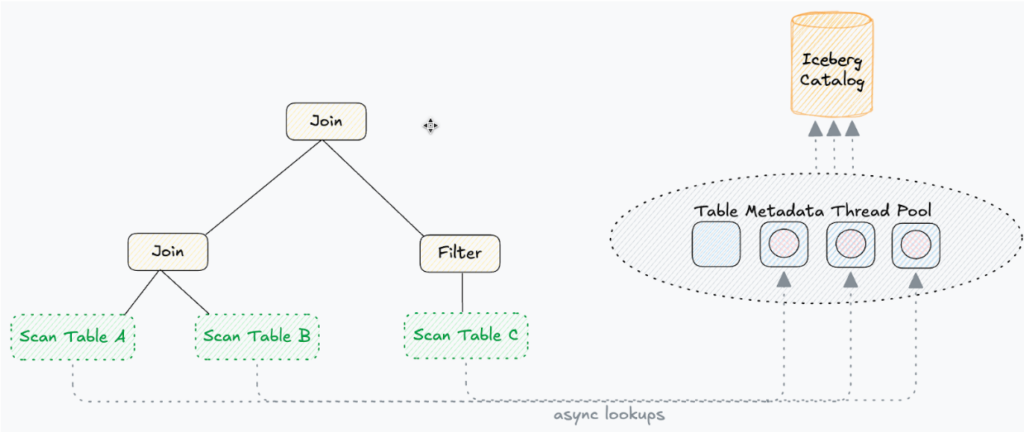
Now, with seamless metadata refresh, Dremio will get the metadata from the Iceberg catalog. But as we mentioned, this can be very detrimental to query performance. So to optimize, Dremio takes advantage of an important detail: fetching the metadata from the Iceberg catalog is an IO bound task - it’s usually just a network call to a remote catalog endpoint. So we maintain a dedicated thread pool just for executing these catalog lookups.
In Dremio, the number of query planning threads matches closely with the number of cpu cores on the machine. We are very careful when it comes to thread management since it has a direct impact on planning performance. However, because these catalog calls are IO bound, we can afford to maintain an extra thread pool since, in theory, they shouldn’t consume much CPU cycles. Although we still stay relatively conservative with the thread pool sizing - using 4x the number of cores.
So now for each table identifier we encounter, we submit an async task to the new metadata thread pool and we can have multiple catalog lookups executing concurrently. It is no longer a serial process.
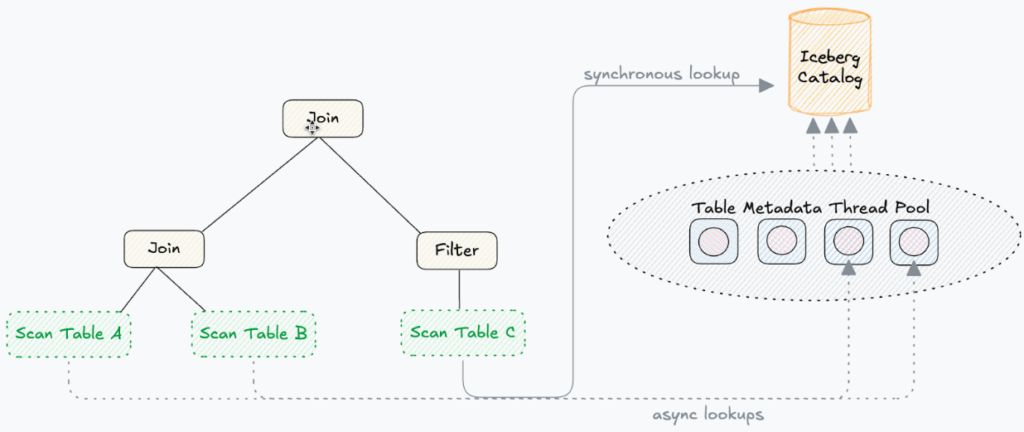
Since I just mentioned that we keep our thread pool bounded, that begs the question of what happens if the pool is saturated with metadata lookups and we have to do another one. Does query planning have to screech to a halt and wait for another slot to open up? Not at all. In this case, we simply fall back to executing the catalog lookup on the planning thread. This ensures that planning is never blocked and is always making progress.
So now we can do these catalog lookups concurrently which really helps to reduce the overall planning time. If we assume that the metadata thread pool has enough capacity to handle all of the catalog lookups, in theory we should only need to pay the cost of a single catalog lookup. This is fantastic! Of course, in practice, this assumption isn’t always true like we mentioned. However, the improvements are still significant.
An Interesting Optimization
There is also another interesting optimization we do to improve this further. Dremio takes advantage of the fact that most updates to a table will not have a material impact on the query plan other than a different table version pointer. What are the changes to a table that can change a query plan? An obvious one is a schema change on the table. Another one could be a change to the partitioning scheme. But these types of changes are going to be relatively infrequent compared to normal inserts/updates/deletes. And if you think about it, adding some rows to a table should not really change the type of query plan that is produced for a particular query most of the time.
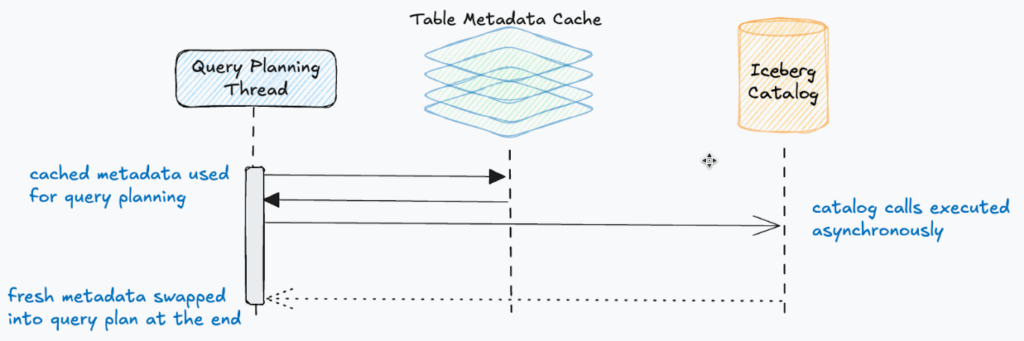
And so from a query planning perspective, we can still make use of cached table metadata to plan a query. Rather than block the query to wait for all of our catalog lookups to complete, we plan the query with table metadata from our cache while the catalog lookups are being executed.
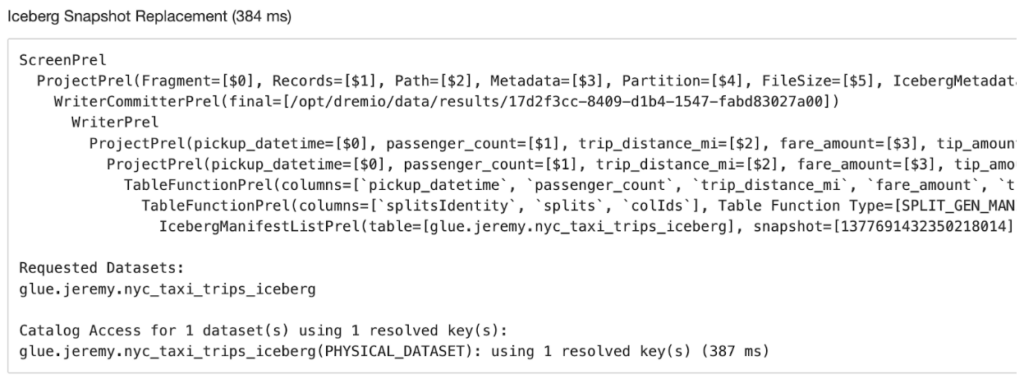
So how does the ‘fresh’ metadata get incorporated? In order for the execution kernel to know which data files to scan for an Iceberg table, it needs a reference to the metadata file which points to the active snapshot (manifest files, data files). The query plan contains this reference. So after planning has completed, we simply collect all of the table metadata from our async catalog calls and we just replace the references with the latest root pointers. Depending on the query, this might mean planning never has to block on these catalog lookups to complete.
And this is very transparent when looking at a query profile. You can see the new query plan along with the new snapshots being read by the manifest list reader.
Of course, we can’t blindly do this for the reasons we just mentioned above. If there has been a schema change on the table for example, this could result in an invalid query plan. So we do some validation on the new metadata we get back from the catalog, and if we determine we can’t do a simple swap, then we will re-plan the query.
The extra cost of planning a query a second time is not ideal, however, these cases are relatively infrequent. So we optimize for the majority of queries at the expense of additional query planning latency for a small set of queries.
Future Improvements
Dremio’s model for seamless metadata refresh is a pull-based one where we poll the catalog at query time. However, there have been discussions within the Iceberg community about including catalog notifications within its specification. If this eventually gets adopted, it would enable an event based model. What this would mean for Dremio is that we could continue using our traditional cache based approach, but we could automatically invalidate the cache when a new snapshot has been published.
Conclusion
The traditional approach of caching table metadata and periodically refreshing has various drawbacks and limitations. With seamless metadata refresh, Dremio now provides users with an effortless experience to query the most up-to-date versions of their Iceberg tables without wrecking the performance of their queries. So now a user querying a shared table in Dremio Enterprise Catalog powered by Apache Polaris for example can see updates from an external Spark job immediately with no delay, and they never even have to think about it.
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Column nullability serves as a safeguard for reliable data systems. Apache Iceberg's capabilities in enforcing and evolving nullability rules are crucial for ensuring data quality. Understanding the null, along with the specifics of engine support, is essential for constructing dependable data systems.
Apr 28, 2025·Engineering Blog
Dremio’s Apache Iceberg Clustering: Technical Blog
Clustering is a data layout strategy that organizes rows based on the values of one or more columns, without physically splitting the dataset into separate partitions. Instead of creating distinct directory structures, like traditional partitioning does, clustering sorts and groups related rows together within the existing storage layout.
May 1, 2025·Engineering Blog
Introducing Dremio Auth Manager for Apache Iceberg
Dremio Auth Manager is intended as an alternative to Iceberg’s built-in OAuth2 manager, offering greater functionality and flexibility while complying with the OAuth2 standards. Dremio Auth Manager streamlines authentication by handling token acquisition and renewal transparently, eliminating the need for users to deal with tokens directly, and avoiding failures due to token expiration.