Caching reduces latency and costs by storing frequently accessed data in local memory.
Dremio uses various caching layers: Query Plan Cache accelerates query execution by reusing plans.
Results Cache saves time by reusing previous query results without re-planning.
Columnar Cloud Cache (C3) minimizes I/O costs by storing data close to compute nodes, speeding retrieval.
Overall, Dremio's caching mechanisms optimize analytics workflows and improve performance.
Caching dramatically reduces latency and computational costs by storing frequently accessed data closer to where it's needed. Instead of repeated expensive operations - such as fetching from object storage, planning complex queries, or executing SQL - the data you need is provided in fast, local memory.
To deliver on this, Dremio implements different layers of caching throughout the analytics workflow. There’s a query plan cache for speeding up query compilation, a results cache for reusing answers to identical queries, and the columnar cloud cache, which stores frequently accessed data right on the compute nodes. Read on to learn more about each of these mechanisms and how they improve performance speeds and reduce costs.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Query Plan Cache
When running a SELECT query, the query must be planned before it is executed. This planning is split into two stages:
Logical: the order of operations for the query
Physical: the steps or actions needed to execute the query
The query plan cache works by storing the physical component of any executed plan for future reuse. When the same query is run again, rather than creating a new plan this cached plan is used instead. This improves performance of repeated queries by reducing the query process down to just execution. This is particularly useful for BI workloads, where queries are run multiple times in order to populate dashboards for different users.
Results Cache
The most straightforward type of caching - reusing results. You save time and compute by neither generating nor running a query plan. The results cache will use answers to previous queries, as long as the corresponding query plan (and user) are the same. However, if the schema or datasets change in any way, the query plans will no longer match and the cached result will be invalid.
The results cache will automatically cache and reuse results with no configuration needed. This cache is also client-agnostic, meaning however you execute your query - in Dremio or through clients such as JDBC or Arrow Flight - the results cache will always be used to accelerate your queries.
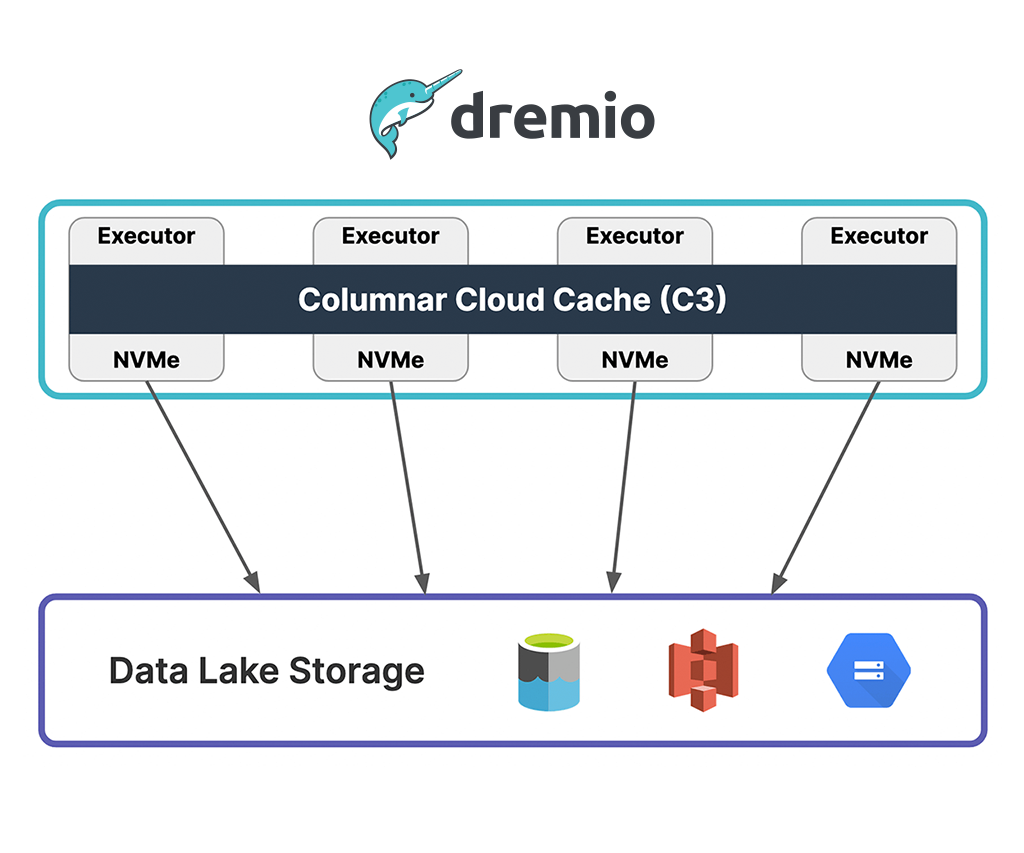
Columnar Cloud Cache
The columnar cloud cache (C3) is a distributed cache designed to bring your data closer to your compute. C3 works by storing frequently accessed data in-memory on the Dremio cluster nodes’ built-in NVMe/SSD storage.
Figure 1.0: Dremio's Columnar Cloud Cache.
With C3, data retrieval is much quicker than fetching from remote object storage, thanks to both being in-memory and not requiring network data transfers. By selectively caching data, either subsets or entire tables, C3 reduces S3/ADLS/GCS I/O costs by over 90%.
Conclusion
Cache is money. Leveraging highly-performant caching mechanisms throughout the analytics workflow dramatically reduces latency and computational costs. Whether repeatedly analysing the same datasets or running the same queries, Dremio's range of caching features will optimise your workflows.
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Sep 22, 2023·Dremio Blog: Open Data Insights
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.