9 minute read · August 15, 2025
Dremio Reflections – The Journey to Autonomous Query Acceleration
· Technical Evangelist

Reflections are a query acceleration functionality unique to Dremio, that work by minimising data processing times and reducing computational workloads. Debuting in the early days of Dremio, Reflections accelerate data lake queries by creating optimised Apache Iceberg data structures from file-based datasets, delivering orders-of-magnitude performance improvements.
However, the game-changing aspect of this technology was not the query acceleration but instead the way that these optimised data structures were used. Rather than being referenced in a query, Dremio would automatically substitute them for the original dataset if it benefited query performance. With the original version of Reflections, this automatic substitution was the only intelligent feature. It fell to Dremio users, typically data engineers, to manually design, build, and refresh the Reflections that the Dremio query engine would evaluate for use.
Wouldn’t it be fantastic if the automated, optimised usage of Reflections also extended to their design and creation? What if Dremio could intelligently suggest and create Reflections based on query patterns, workload analysis, and performance bottlenecks? And keep Reflections fresh through incremental updates, where possible, and provide data freshness guarantees for every query? Well, now it does.
Read on to learn the development journey of Reflections, detailing where they started and the feature stepping-stones that brought Dremio Reflections to the fully autonomous implementation available today.
What are Reflections?
Built on the principles of materialised views, Reflections are optimised representations of source data intended to speed up querying. They can be based on either a table or a view, which forms the anchor for the Reflection. Dremio ensures consistent data governance by having Reflections follow the same access and security rules as the anchor dataset.
Reflections come in two types:
- Raw: a reorganised or reduced dataset intended to replace unoptimised or slow data sources.
- Aggregation: pre-computed aggregated data summaries used in BI-style queries.
Dremio users do not have to update any SQL code to leverage Reflections nor do they need to change how they write SQL statements. Instead, Dremio’s query planner will automatically use one or more Reflections during query execution to achieve improved query performance.
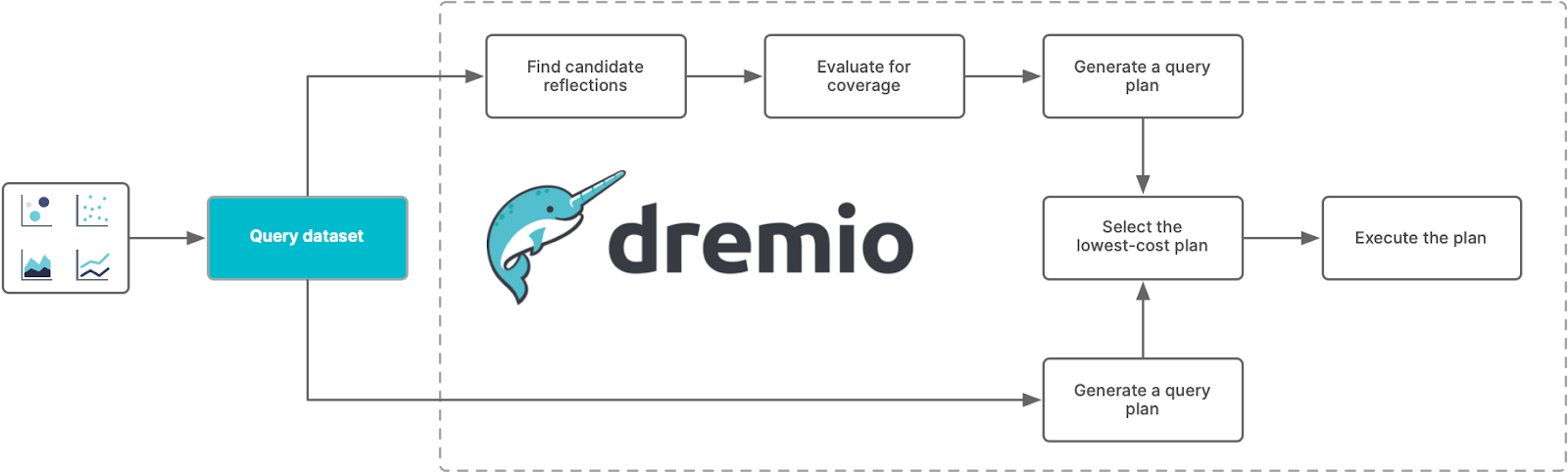
Data engineers who are responsible for performance management are entrusted with the creation of Reflections that enhance the performance of frequently executed queries. But as it stood with the first iteration of Reflections, there was little to assist them in identifying what Reflections to create or evaluating how effectively performance is being improved.
Improving Reflection Management
In practice, the creation of Reflections is a two-step manual process:
- Identify common query patterns or poorly performing queries,
- Design and create one or more Reflections to improve those queries.
Reflection Recommendations was created to take care of that second process. No longer were data engineers having to write Reflections, instead they showed Dremio the problem and the answer was generated for them.
Initially, users provided a set of jobs and Dremio would recommend Reflections to boost their performance and any others that followed the same pattern. However, this still left the first process of identifying these patterns, which could be challenging on large deployments running up to hundreds of thousands of queries. To solve this issue, Dremio enabled the Reflection recommendation engine to look at all jobs within a 7-day time window.
Users are recommended 10 Reflections that will make the most impact on query performance. This list is updated daily, based on the number of prior jobs that could be accelerated with the recommendation and the expected average improvement in performance. With Reflection Recommendations the creation of Reflections has been simplified down to the clicking of a button, "Create Reflection".
To make evaluating Reflections easier, Dremio introduced a Reflection Score. Each existing or recommended Reflection is assigned a score on a logarithmic scale from 1 to 100, with 100 being the highest. The score is an estimate of the usefulness of a Reflection, and considers factors such as the number of accelerated jobs, the improved query speed, and the time saved.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Enhancing Reflection Efficiency
Recall that Reflections are materialised views and, like any other physical table, need to be maintained and the data refreshed. The size of your Reflection and the frequency of these refreshes can potentially demand large resource and time costs. To address these concerns Dremio developed a new Reflection refresh system that was built around the Apache Iceberg table format. This system delivers significant improvements in refresh performance by detecting incremental changes to anchor datasets.
Originally, Reflections could be refreshed either manually or on a schedule as part of a data pipeline. While viable options, they are both an administrative burden on data engineers and prone to data desync as these processes are not driven by data changes. With Live Reflections any Reflection based on an Iceberg table is refreshed automatically when their anchor dataset is updated. Additionally, any scheduled or manual request to refresh a Reflection when the anchor dataset has not changed will be identified as redundant and not executed.
Incremental Refreshes transform Reflection maintenance by utilising Apache Iceberg's metadata layer to detect changes between Iceberg snapshots. Rather than reprocessing entire datasets, Dremio can now perform granular updates, processing only new, modified, or deleted records, resulting in faster refreshes and reduced compute costs.
Fully Autonomous Reflections
So, where are we in our progress towards fully automated Reflections? With the features discussed so far, Dremio can independently:
- Identify and adapt to query patterns across your organisation,
- Recommend optimal Reflections that will have the most performance impact,
- Ensure efficient data freshness by staying in sync with anchor Iceberg tables,
- Substitute Reflections into any applicable query to boost performance.
What is missing is the ability for Dremio to bridge the gap between insight and action, without human intervention. The final pieces of logic to achieve this were delivered this year in Dremio v26.0. Dremio can now perform cost-benefit analysis by comparing the lowest-scoring existing Reflections with the highest-scoring recommendations and determine if changes are worth making. It also has the ability to enact those changes by creating or dropping Reflections without user approval.
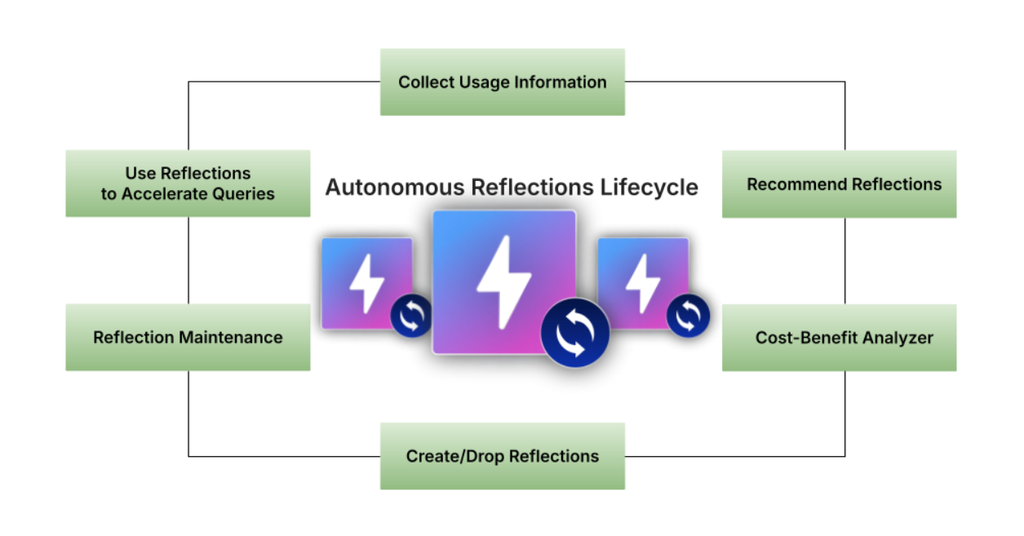
To maintain transparency and confidence in this automated process, Dremio also introduced observability features such as a history log detailing Reflection changes and the reasoning, and a monitoring tool that provides information on savings over time. Guardrails were implemented to ensure that autonomously created Reflections would not consume excessive resources. One such guardrail is a feedback loop preventing the repeated recreation of failed, dropped, or manually deleted Reflections for a certain time period.
Summary
Dremio's Reflections feature has undergone a remarkable transformation, evolving from a simple query acceleration tool to a sophisticated, self-managing optimisation system that brings cutting-edge performance to data lake architectures.
This evolution demonstrates Dremio's commitment to continuous innovation in query performance. From manual optimisation to autonomous, self-tuning systems, Reflections have transformed how organisations approach data lake performance, making optimal query execution not just possible, but automatic.
The journey from basic materialisation to intelligent, self-managing optimisation showcases how modern data platforms can combine open standards like Apache Iceberg with innovative features to deliver enterprise-grade performance.
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights, Product Insights from the Dremio Blog,
Learn More ->