This article has been revised and updated from its original version published in 2022 to reflect the latest developments in all three table formats as of 2025.
The three major open table formats for data lakehouses (Apache Iceberg, Apache Hudi, and Delta Lake) each take fundamentally different architectural approaches to solving the same core problem: bringing transactional capabilities and data warehouse-like features to data lakes. Understanding these architectural differences is critical for choosing the right format for your organization.
Choosing a table format is one of the most consequential decisions in building a modern data platform. The format you choose determines which query engines can access your data, how efficiently your queries execute, how easily you can evolve your data model over time, and how much operational overhead your data team absorbs. Unlike a database engine, which you can replace relatively easily, the table format underpins every data file on your lake, migrating between formats is possible but expensive at petabyte scale.
The table format landscape has evolved significantly since 2022. Apache Iceberg has emerged as the industry standard, adopted by every major cloud provider, query engine, and data platform. Delta Lake has responded with the UniForm compatibility layer. Apache Hudi has deepened its specialization in record-level operations. Despite these changes, the core architectural differences that drove the original format choices remain relevant.
Dremio has been at the forefront of the Apache Iceberg ecosystem, building its entire unified lakehouse platform on Iceberg. Dremio's query engine, Reflections, and table management commands (OPTIMIZE TABLE, VACUUM TABLE) are specifically optimized for Iceberg's metadata architecture. This deep integration enables sub-second dashboard queries, self-service analytics, and AI-ready data, all running directly on Iceberg tables stored on your cloud object storage.
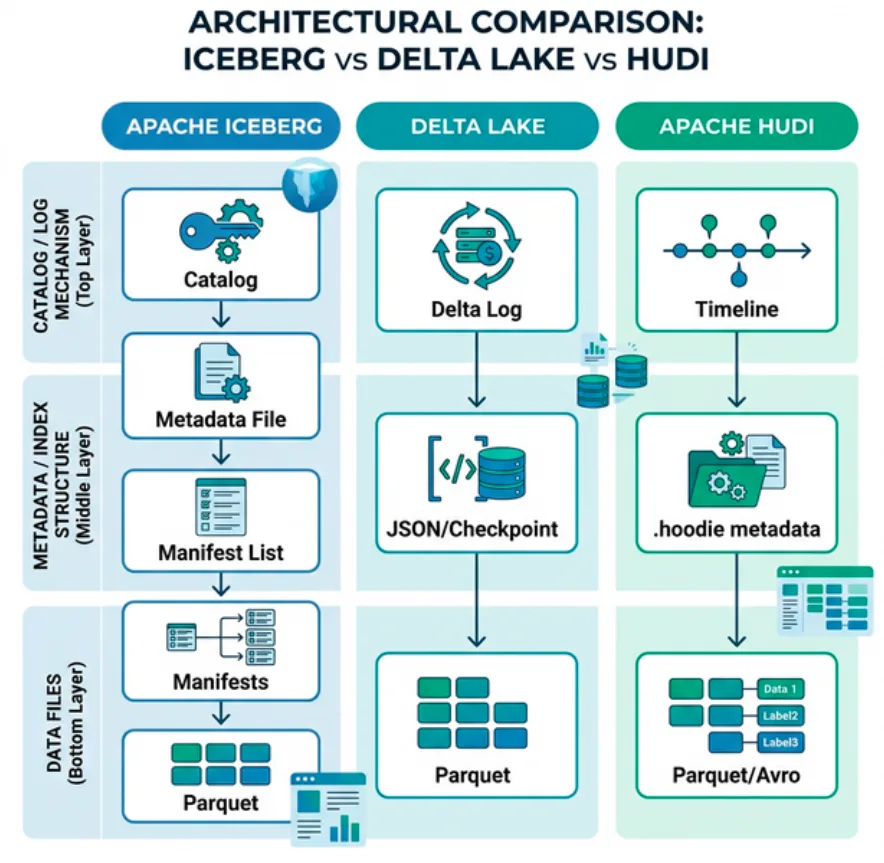
Apache Iceberg is defined by an open specification, a detailed document describing exactly how metadata, manifests, data files, and catalogs interact. Any engine that implements the specification can read and write Iceberg tables correctly, without depending on a specific runtime library. For official documentation, refer to the Iceberg specification.
Format versions: V1 (read-only), V2 (row-level operations via COW/MOR), V3 (deletion vectors)
Delta Lake: Spark-Native, Log-Based
Delta Lake uses a JSON-based transaction log (_delta_log/) that records every operation as a sequentially numbered JSON or Parquet file. The transaction log is the single source of truth for the table's state.
Key architectural elements:
Transaction log: Sequential JSON/Parquet files in _delta_log/ directory
Checkpoint files: Periodic Parquet snapshots of the log for faster reads
Data skipping: Column statistics stored in the transaction log (not in manifests)
Liquid Clustering: Replaces traditional partitioning with incremental clustering
Unity Catalog: Databricks' proprietary catalog (open-sourced as OSS Unity)
Apache Hudi: Record-Level, Upsert-Optimized
Apache Hudi was originally built for high-volume upsert workloads (Change Data Capture, CDC). It organizes data around record keys and provides record-level indexing.
Key architectural elements:
Timeline: Immutable timeline of actions (commits, compactions, cleaning)
Table types: Copy-on-Write (COW) tables and Merge-on-Read (MOR) tables
Record-level index: Maps record keys to file groups for fast lookups
File groups: Base files plus delta logs, compacted periodically
Iceberg has the broadest engine support because its open specification allows any engine to implement compatible readers and writers independently.
Community and Governance
Aspect
Apache Iceberg
Delta Lake
Apache Hudi
Governance
Apache Software Foundation
Linux Foundation (Databricks stewardship)
Apache Software Foundation
Contributors
800+ from 100+ companies
300+ (Databricks-dominated)
200+ (limited diversity)
Corporate dependency
None (multi-vendor)
Moderate (Databricks-originated)
Moderate (originally Uber)
Specification
Independent, versioned
Evolving protocol
Implementation-defined
Why Dremio Chose Apache Iceberg
Dremio built its lakehouse platform exclusively on Apache Iceberg for several strategic reasons:
Engine independence: Iceberg's open specification means customers aren't locked into a single query engine. Data written by Spark can be queried by Dremio, Trino, Flink, or any other compatible engine
Engine independence and vendor neutrality are priorities
Choose Delta Lake When
Your organization is fully committed to the Databricks ecosystem
Auto-Optimize and Liquid Clustering simplify your operations
You need tight integration with Databricks Unity Catalog
Choose Hudi When
Your primary workload is high-volume CDC/upserts from operational databases
You need record-level indexing for fast point lookups
Near-real-time data availability is the top priority
Format Interoperability and UniForm
As the table format landscape matures, interoperability between formats is becoming increasingly important. Several approaches exist:
Delta Lake UniForm
Databricks introduced UniForm, which generates Iceberg metadata alongside Delta metadata. This allows Iceberg-compatible engines (like Dremio) to read Delta tables through an Iceberg compatibility layer. However, the Iceberg metadata is read-only, writes must go through the Delta protocol.
Apache XTable (formerly OneTable)
Apache XTable provides cross-format translation for Iceberg, Delta Lake, and Hudi. It synchronizes metadata between formats, enabling organizations to maintain a single physical copy of data accessible through multiple format protocols.
Dremio's Approach
Dremio handles format interoperability by providing native connectors for both Iceberg and Delta Lake sources. You can query both formats through Dremio's unified SQL interface, join across formats, and use CTAS to migrate data from Delta to Iceberg:
-- Query a Delta table through Dremio
SELECT * FROM delta_source.db.customers;
-- Convert Delta to Iceberg via CTAS
CREATE TABLE iceberg_catalog.db.customers AS
SELECT * FROM delta_source.db.customers;
Real-World Decision Framework
Beyond feature checklists, consider these practical factors:
Total Cost of Ownership
Factor
Iceberg + Dremio
Delta + Databricks
Hudi + Spark
Storage costs
Low (standard S3)
Low (standard S3)
Low (standard S3)
Compute costs
Low (Dremio optimization: C3, Reflections)
Moderate (Databricks Units)
High (self-managed Spark)
Table maintenance
Low (OPTIMIZE, VACUUM)
Low (Auto-Optimize)
Moderate (manual compaction)
Vendor lock-in risk
Low (open spec, multi-engine)
Moderate (Databricks-optimized)
Low (Apache, but limited engines)
Migration Path
When converting between formats, keep these guidance points in mind:
If your team primarily uses Spark, all three formats are accessible. If you use Trino, Flink, DuckDB, or other engines, Iceberg provides the broadest compatibility. If you're building on Dremio, Iceberg is the native and optimized choice.
The Industry Trajectory
The data lakehouse ecosystem is clearly converging on Apache Iceberg:
Snowflake: Added native Iceberg Tables support (Polaris catalog)
AWS: Iceberg is the default table format for Athena, Glue, and EMR
Google Cloud: BigLake supports Iceberg natively
Cloudera: Adopted Iceberg as its open lakehouse standard
Tabular: Acquired by Databricks (Iceberg's commercial company)
This broad industry adoption confirms that Iceberg's architecture (specification-driven, engine-independent, and cloud-native) has won the table format debate for most enterprise use cases.
Frequently Asked Questions
Can the same data be accessed through multiple formats simultaneously?
Yes, using Apache XTable or Delta Lake UniForm. However, writes should go through one format to avoid conflicts. Read interoperability is easier to achieve than write interoperability.
Is Apache Iceberg always the best choice?
Not always. If your entire stack is Databricks and you have no multi-engine requirements, Delta Lake with Databricks optimization may be simpler. If your primary workload is high-frequency CDC with record-level lookups, Hudi's record-level index is uniquely valuable. For most other scenarios, Iceberg provides the best combination of openness, performance, and ecosystem support.
Iceberg's hidden partitioning and partition evolution are architectural advantages. Delta Lake requires Liquid Clustering for similar flexibility. Hudi requires explicit partition columns with no evolution support.
Which table format should I choose for a new project in 2026?
For new projects, Apache Iceberg is the recommended choice due to its broadest multi-engine compatibility, strongest community governance under the Apache Software Foundation, and most advanced features for partition evolution and hidden partitioning. If your organization is already heavily invested in Databricks, Delta Lake is a natural choice but consider enabling UniForm for Iceberg compatibility to keep your options open for future multi-engine access.
Article updated on May 12, 2022 to reflect additional tooling support and updates from the newly released Hudi 0.11.0.
Article updated on June 7, 2022 to reflect new flink support bug fix for Delta Lake OSS along with updating calculation of contributions to better reflect committers employer at the time of commits for top contributors.
Article updated on June 28, 2022 to reflect new Delta Lake open source announcement and other updates.
Article was updated on April 13, 2023 first route of revisions including some updates of summary of github stats in main summary chart and some newer pie charts of % contributions. I made some updates to engine support, will make deeper update later on.
Update to engine support August 7th, 2023 main changes seen in Apache Beam and Redshift in the engines being tracked.
What Is a Table Format?
Table formats allow us to interact with data lakes as easily as we interact with databases, using our favorite tools and languages. A table format allows us to abstract different data files as a singular dataset, a table.
Data in a data lake can often be stretched across several files. We can engineer and analyze this data using R, Python, Scala and Java using tools like Spark and Flink. Being able to define groups of these files as a single dataset, such as a table, makes analyzing them much easier (versus manually grouping files, or analyzing one file at a time). On top of that, SQL depends on the idea of a table and SQL is probably the most accessible language for conducting analytics.
Hive: A First-Generation Table Format
The original table format was Apache Hive. In Hive, a table is defined as all the files in one or more particular directories. While this enabled SQL expressions and other analytics to be run on a data lake, It couldn’t effectively scale to the volumes and complexity of analytics needed to meet today’s needs. Other table formats were developed to provide the scalability required.
The Next Generation
Introducing: Apache Iceberg, Apache Hudi, and Databricks Delta Lake. All three take a similar approach of leveraging metadata to handle the heavy lifting. Metadata structures are used to define:
What is the table?
What is the table’s schema?
How is the table partitioned?
What data files make up the table?
While starting from a similar premise, each format has many differences, which may make one table format more compelling than another when it comes to enabling analytics on your data lake.
ACID Transactions
Partition Evolution
Schema Evolution (later chart with more detail)
Time-Travel
Project Governance
Apache Project with a diverse PMC (top-level project)
Apache Project with a diverse PMC (top-level project)
Linux Foundation Project with an all-Databricks TSC
This article will primarily focus on comparing open-source table formats that enable you to run analytics using open architecture on your data lake using different engines and tools so we will be focusing on the open-source version of Delta Lake. Open architectures help minimize costs, avoid vendor lock-in, and ensure the latest and best-in-breed tools can always be available on your data.
Keep in mind Databricks has its own proprietary fork of Delta Lake, which has features only available on the Databricks platform. This is also true of Spark - Databricks-managed Spark clusters run a proprietary fork of Spark with features only available to Databricks customers. These proprietary forks aren’t open to enable other engines and tools to take full advantage of them, so they are not this article's focus.
ACID Transactions
One of the benefits of moving away from Hive’s directory-based approach is that it opens a new possibility of having ACID (Atomicity, Consistency, Isolation, Durability) guarantees on more types of transactions, such as inserts, deletes, and updates. In addition to ACID functionality, next-generation table formats enable these operations to run concurrently.
Apache Iceberg
Apache Iceberg’s approach is to define the table through three categories of metadata. These categories are:
“metadata files” that define the table
“manifest lists” that define a snapshot of the table
“manifests” that define groups of data files that may be part of one or more snapshots
Query optimization and all of Iceberg’s features are enabled by the data in these three layers of metadata.
Through the metadata tree (i.e., metadata files, manifest lists, and manifests), Iceberg provides snapshot isolation and ACID support. When a query is run, Iceberg will use the latest snapshot unless otherwise stated. Writes to any given table create a new snapshot, which does not affect concurrent queries. Concurrent writes are handled through optimistic concurrency (whoever writes the new snapshot first, does so, and other writes are reattempted).
Beyond the typical creates, inserts, and merges, row-level updates and deletes are also possible with Apache Iceberg. All of these transactions are possible using SQL commands.
Apache Hudi
Apache Hudi’s approach is to group all transactions into different types of actions that occur along a timeline. Hudi uses a directory-based approach with files that are timestamped and log files that track changes to the records in that data file. Hudi allows you the option to enable a metadata table for query optimization (The metadata table is now on by default starting in version 0.11.0). This table will track a list of files that can be used for query planning instead of file operations, avoiding a potential bottleneck for large datasets.
Delta Lake’s approach is to track metadata in two types of files:
Delta Logs sequentially track changes to the table.
Checkpoints summarize all changes to the table up to that point minus transactions that cancel each other out.
Delta Lake also supports ACID transactions and includes SQL support for creates, inserts, merges, updates, and deletes.
Partition Evolution
Partitions allow for more efficient queries that don’t scan the full depth of a table every time. Partitions are an important concept when you are organizing the data to be queried effectively. Often, the partitioning scheme of a table will need to change over time. With Hive, changing partitioning schemes is a very heavy operation. If data was partitioned by year and we wanted to change it to be partitioned by month, it would require a rewrite of the entire table. More efficient partitioning is needed for managing data at scale.
Partition evolution allows us to update the partition scheme of a table without having to rewrite all the previous data.
Apache Iceberg
Apache Iceberg is currently the only table format with partition evolution support. Partitions are tracked based on the partition column and the transform on the column (like transforming a timestamp into a day or year).
This is different from typical approaches, which rely on the values of a particular column and often require making new columns just for partitioning. With the traditional way, pre-Iceberg, data consumers would need to know to filter by the partition column to get the benefits of the partition (a query that includes a filter on a timestamp column but not on the partition column derived from that timestamp would result in a full table scan). This is a huge barrier to enabling broad usage of any underlying system. Iceberg enables great functionality for getting maximum value from partitions and delivering performance even for non-expert users.
Delta Lake
Delta Lake does not support partition evolution. It can achieve something similar to hidden partitioning with its generated columns feature which is currently in public preview for Databricks Delta Lake, still awaiting full support for OSS Delta Lake.
Time travel allows us to query a table at its previous states. A common use case is to test updated machine learning algorithms on the same data used in previous model tests. Comparing models against the same data is required to properly understand the changes to a model.
In general, all formats enable time travel through “snapshots.” Each snapshot contains the files associated with it. Periodically, you’ll want to clean up older, unneeded snapshots to prevent unnecessary storage costs. Each table format has different tools for maintaining snapshots, and once a snapshot is removed you can no longer time-travel to that snapshot.
Apache Iceberg
Every time an update is made to an Iceberg table, a snapshot is created. You can specify a snapshot-id or timestamp and query the data as it was with Apache Iceberg. To maintain Apache Iceberg tables you’ll want to periodically expire snapshots using the expireSnapshots procedure to reduce the number of files stored (for instance, you may want to expire all snapshots older than the current year.). Once a snapshot is expired you can’t time-travel back to it.
Apache Governed Project
Open Source License
Apache
Apache
Apache
First Open Source Commit
12/13/2017
12/16/2016
4/12/2019
Many projects are created out of a need at a particular company. Apache Iceberg came out of Netflix, Hudi out of Uber, and Delta Lake out of Databricks.
There are many different types of open-source licensing, including the popular Apache license. Before becoming an Apache Project, reporting, governance, technical, branding, and community standards must be met. The Apache Project status assures that there is a fair governing body behind a project and that the commercial influences of any particular company aren’t steering it.
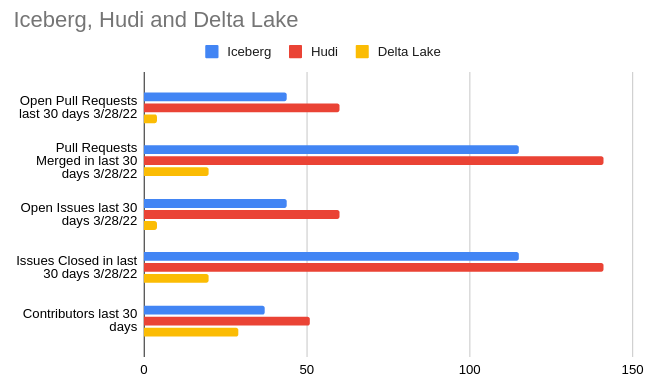
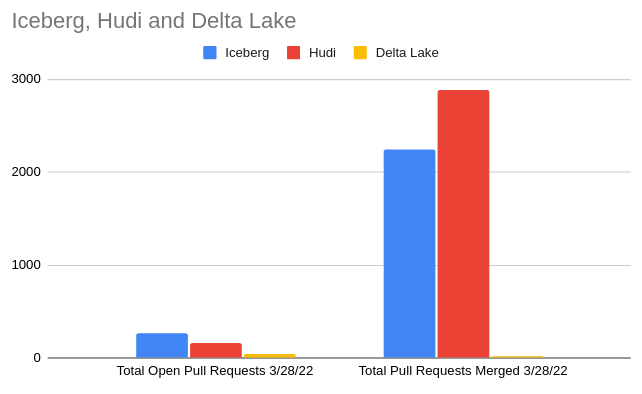
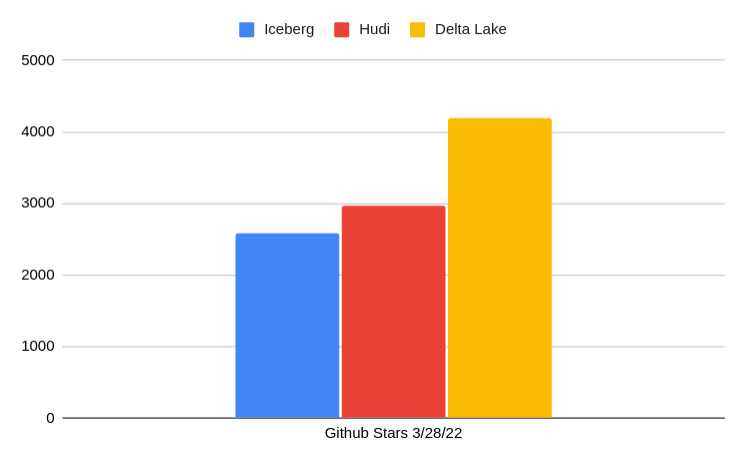
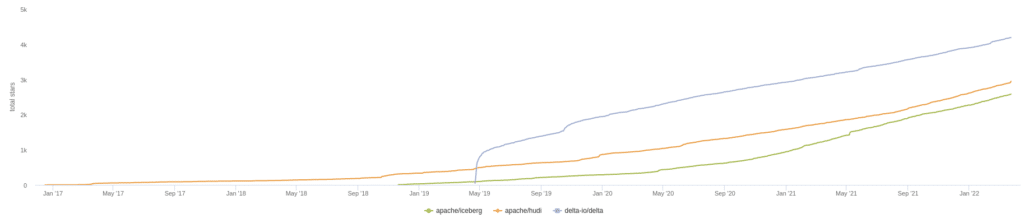
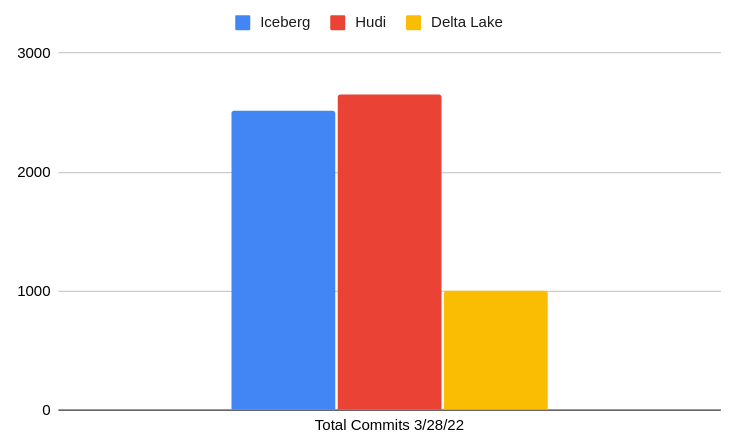
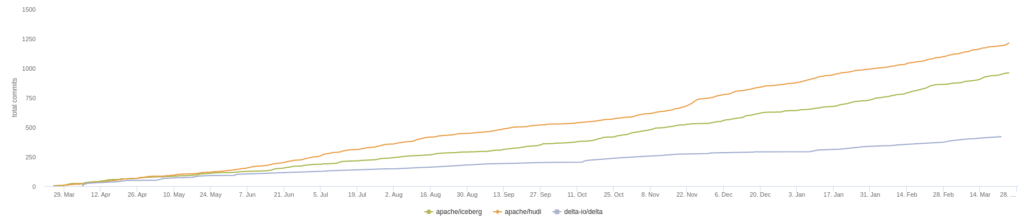
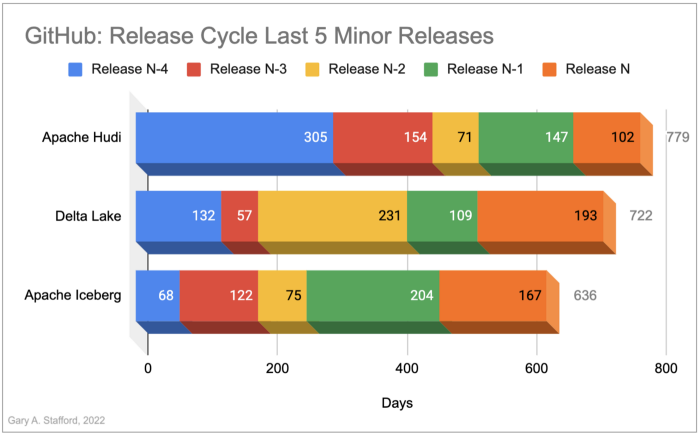
In the chart above we see the summary of current GitHub stats over a 30-day period, which illustrates the current moment of contributions to a particular project. When choosing an open-source project to build your data architecture around you want strong contribution momentum to ensure the project's long-term support. Let’s look at several other metrics relating to the activity in each project’s GitHub repository and discuss why they matter.
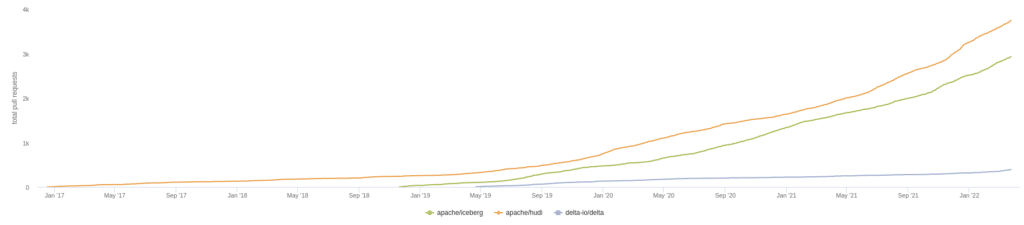
Overall Comparison of the Three RepositoriesCurrent Number of Pull RequestsHistorical Trend of Repository Pull RequestsCurrent Number of Github StarsHistorical Trend of Github StarsCurrent Repository CommitsHistorical Trend of Repository Commits
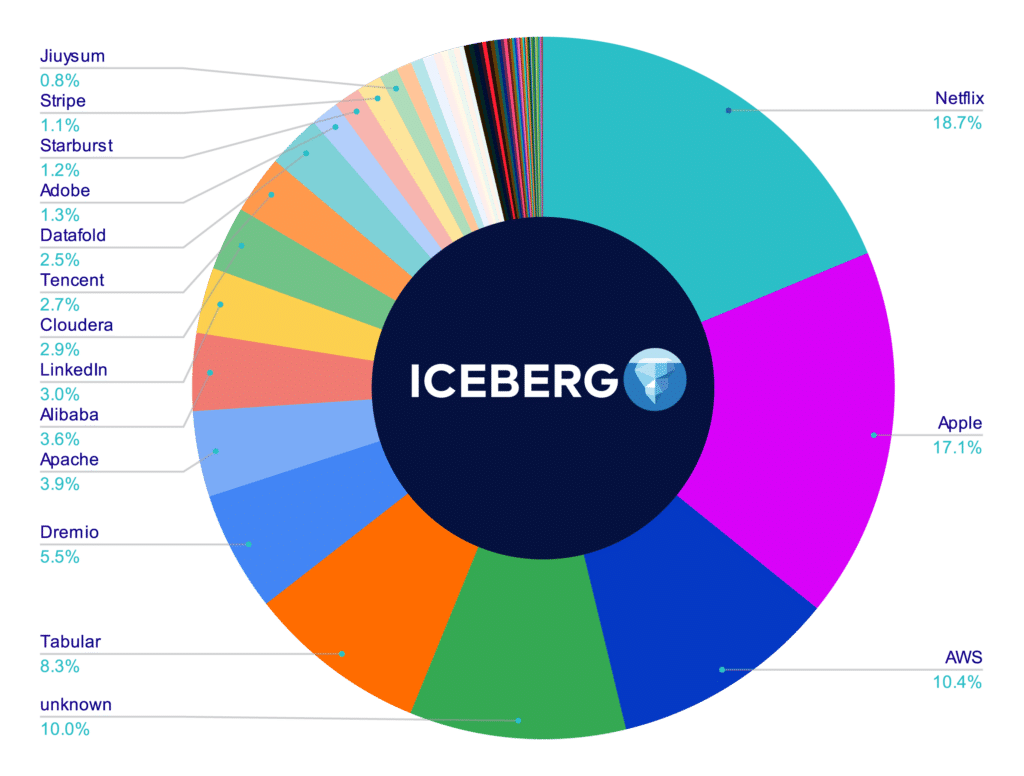
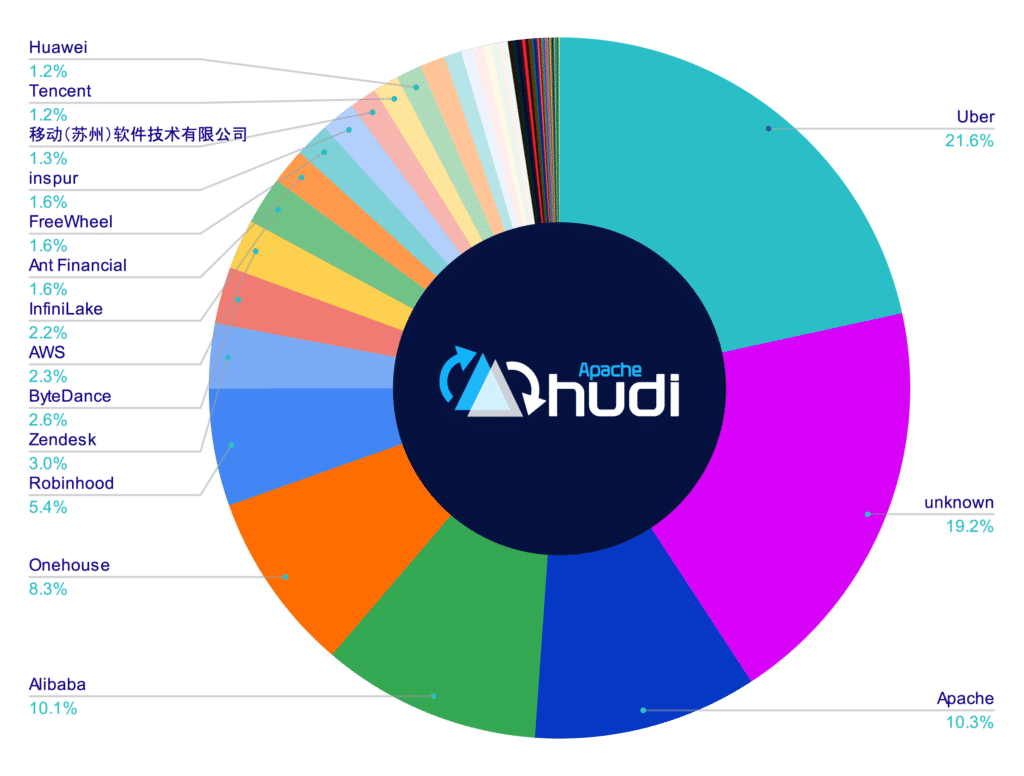
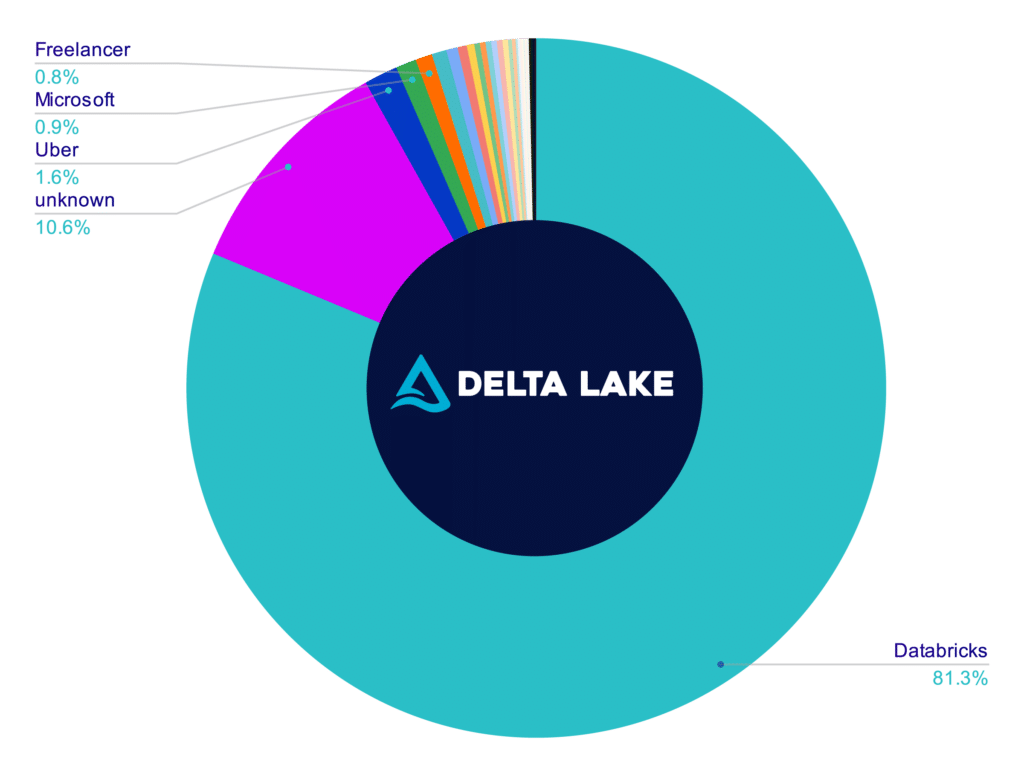
Attributable Repository Contributors
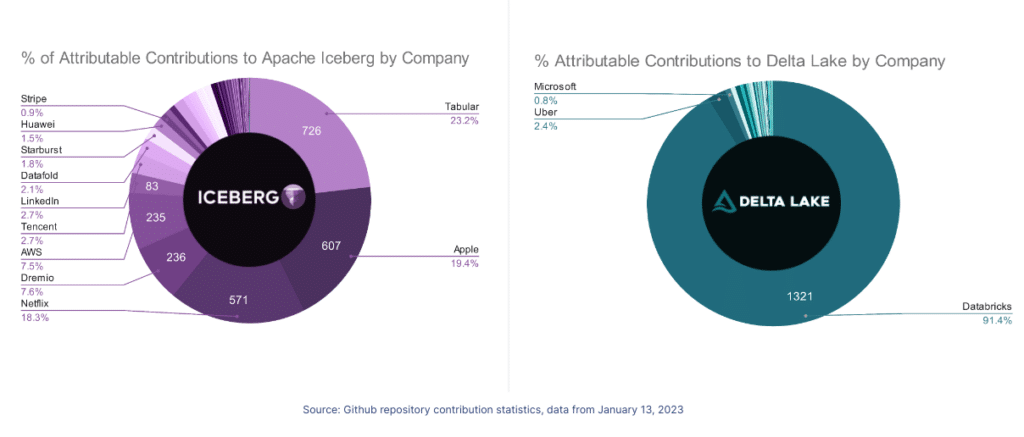
[UPDATE] On January 13th, 2023 the number on the apache/iceberg and delta-io/delta repositories were calculated again using the same methodology as the above. The charts below represent the results; in this run, all contributors whose company could not be researched were removed so this only accounts for contributors whose contributions could be attributed to a particular company versus the charts above, which included "unknown" contributors". If you want to recalculate these values, you can find my scripts and methodology in this repository.
When you’re looking at an open source project, two things matter quite a bit:
Number of community contributions
Whether the project is community governed
Community contributions matter because they can signal whether the project will be sustainable for the long haul. Community governed matters because when one particular party has too much control of the governance it can result in unintentional prioritization of issues and pull requests towards that party’s particular interests.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Sep 22, 2023·Dremio Blog: Open Data Insights
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.