Data engineers working with lakehouses are no stranger to the complexity of managing vast amounts of structured and unstructured data across distributed systems. While lakehouses offer the best of both worlds—combining the flexibility of data lakes with the performance benefits of data warehouses—optimizing query performance remains a persistent challenge. With growing data volumes and the need for real-time insights, slow queries and high computational costs can quickly become roadblocks.
Materialized views can provide a solution, offering precomputed results for faster data retrieval. But the real challenge is knowing which materialized views to create and when to refresh them. Manually determining this can be a time-consuming and error-prone process, especially as data patterns evolve.
Imagine a system that intelligently suggests and creates materialized views based on query patterns, workload analysis, and performance bottlenecks. A system that adapts as your query needs evolve, automatically leveraging materialized views without explicit references. Better yet, it keeps these views fresh through incremental updates where possible, while providing data freshness guarantees for every query.
We are happy to announce that such a system now exists and it is called Dremio Autonomous Reflections. In this blog, we’ll explore the development journey behind Autonomous Reflections and dive into its lifecycle, taking a closer look at the data Dremio collects and how it’s used to autonomously recommend, score, create, and drop reflections. We’ll wrap up by highlighting the benefits Dremio’s internal data lakehouse has achieved through this feature.
Our Journey to Autonomous Reflections
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Planning
From the very beginning we recognized that Autonomous Reflections would be a complex feature requiring multiple quarters of engineering effort by multiple team members. We had to decide how to break this down into smaller MVPs and what order to deliver things in. We considered:
dependencies between components (e.g. cost benefit analyzer for recommended reflections would be useless without some recommended reflections to use it on)
what would make a good independent feature and bring immediate customer value
what part of the system would could require the most tuning and customer feedback
uncertain/tricky parts that could affect the timeline
First Steps - Job Based Recommendations
In version 24.2, we introduced the first iteration of aggregate reflection recommendations, based on a user-provided set of jobs. This approach was selected because it addressed a critical, complex aspect of the system and had the potential to benefit the most from customer feedback. By launching it independently, we focused on perfecting the most challenging component before expanding further.
While the feedback was generally positive, customers noted that the recommendations didn’t cover many cases where reflections would have been valuable. As a result, we revisited the recommendation algorithm and redesigned it from the ground up.
In version 24.3, we released an updated version of the recommendation algorithm, employing a new bottom-up approach. This update delivered improved performance, increased the range of applicable recommendations, and made it easier to apply a single reflection across multiple jobs. In version 25.0, we took it a step further, enhancing the system to include default raw reflection recommendations for views that customers had already configured.
Usage Based Recommendations
After successfully implementing reflection recommendations for a limited set of queries, where users manually specified job IDs, we began exploring the possibility of expanding this functionality to cover all queries over a given time period—an inherently more complex task. We referred to this as usage-based recommendations, as it would analyze system-wide query usage rather than just a predefined set of jobs.
This expansion introduced new challenges. First, we needed to collect usage data without impacting system performance. To achieve this, we gathered data asynchronously after queries completed. To manage storage, we aggregated the data at the daily level, enabling analysis over a sliding 7-day window.
Another challenge arose from the sheer volume of potential recommendations. Analyzing all queries run in the last 7 days meant that we got way more recommendations, making it impractical to create them all, as some would provide limited benefits. We needed a way to prioritize the most valuable recommendations and estimate their impact, as usage alone is not a good enough indicator. For example, we had to balance reflections that improved performance by 1.1x for 100 queries against those offering a 100x speedup for 90 queries.
Estimating the impact of non-existent reflections proved tricky. To address this, we sampled jobs linked to each recommended reflection, replanned the queries, and compared execution plans with and without the proposed reflection. This approach allowed us to estimate the potential benefits and identify cases where a recommended reflection might not be applicable—such as when a more optimal reflection had already been created within the 7-day window.
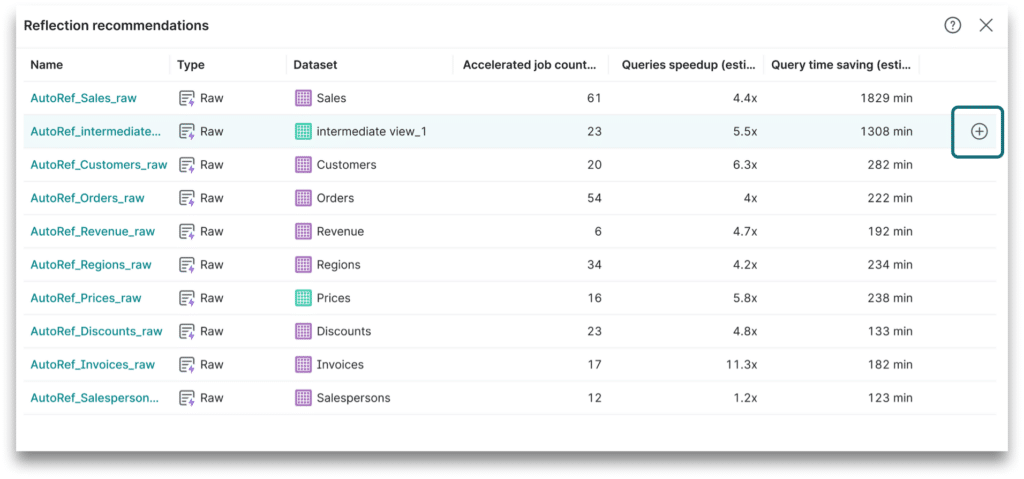
In version 25.1, we released the first version of usage-based recommendations for Default Raw Reflections. Using the Cost-Based Analyzer scoring algorithm, we selected the best recommendations. This marked the completion of the core Autonomous Reflection Lifecycle, enabling us to analyze user usage patterns, generate and score reflection recommendations, and present them to users with expected savings. Users could then create the reflections with a single click.
At this stage, users were still responsible for managing reflection removal when query patterns changed and existing reflections became obsolete. To simplify this task, we enhanced the Cost-Based Analyzer in version v25.2 to evaluate existing reflections. This update enabled us to display a reflection score for both recommended and manually created reflections, making it easier for users to identify the most valuable reflections and spot candidates for deletion.
Autonomous Reflections
At this stage, we had most of the core components in place. Our system could recommend and score reflections, and we had a method for evaluating existing reflections as well. What remained was comparing the highest-scoring recommendations with the lowest-scoring existing reflections, and deciding if any changes were needed.
In version 26.0, we introduced autonomous logic to automatically create and delete reflections based on gathered data and changing user workloads. We implemented multiple guardrails to ensure that the reflections we created would be valuable without consuming excessive resources.
With the major workflow in place, we delivered many usability features to make the user experience better, such as:
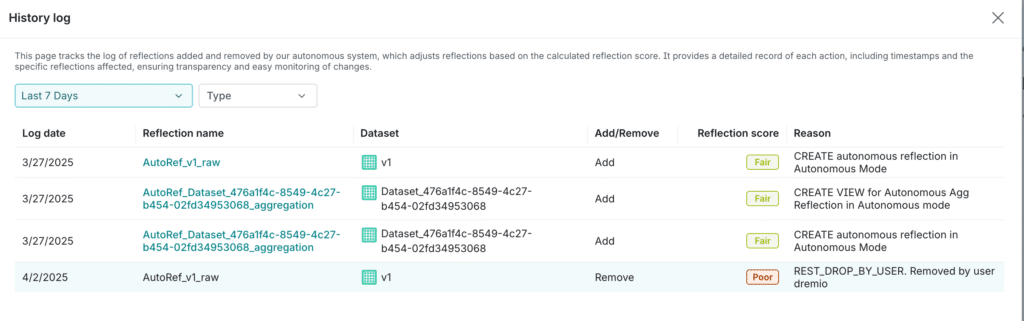
Autonomous Reflections History Log that would display what reflections we created, what reflections we dropped and why
Autonomous Reflections Monitoring that would provide information on savings of autonomous reflections over time
Added underperforming Autonomous Reflections feedback loop. We learn from past experiences to avoid repeating the same mistakes. We prevent Autonomous Reflections that have failed, been auto-dropped multiple times, or manually deleted by users from being recreated for a certain time period.
Added view management for Aggregate Autonomous Reflections. This feature hides the views required for Aggregate Reflections to function. We aimed to keep these views invisible to end users, preventing the views from being used for other purposes, as those views could be dropped at any time if the associated Autonomous Reflection is no longer beneficial.
Autonomous Reflections dedicated refresh engine to make sure interactive user workloads are not affected by Autonomous Reflections refresh jobs and recommendations to scale the refresh engine if needed
Automatically scale up or down the number of Autonomous Reflections allowed within certain limits based on refresh engine queue sizes and error rates.
Integration with Live Reflection Refresh feature, triggering Live Refresh for Autonomous Reflections as soon as the data changes, and making sure only up to date Autonomous Reflections are used in the user query
Autonomous Reflection Deep Dive
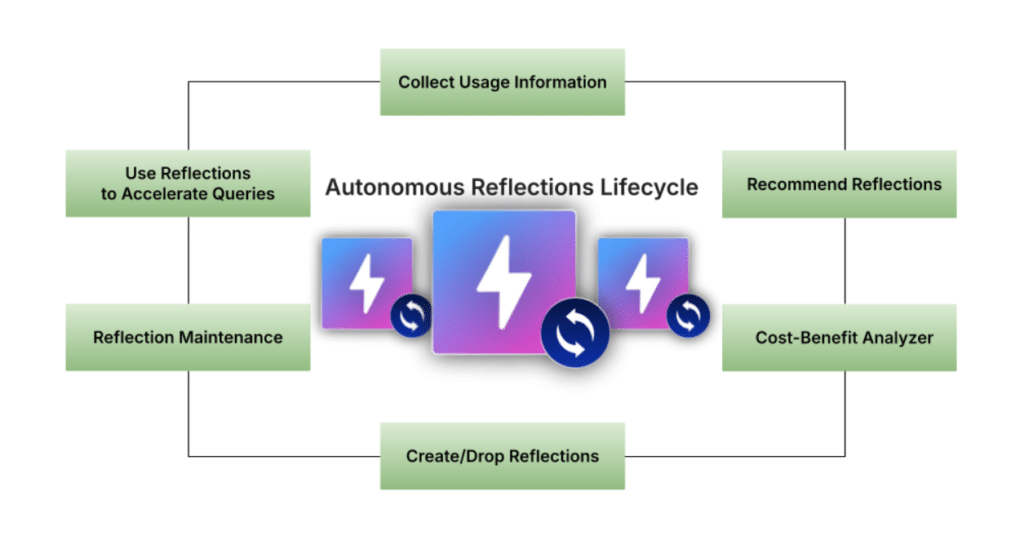
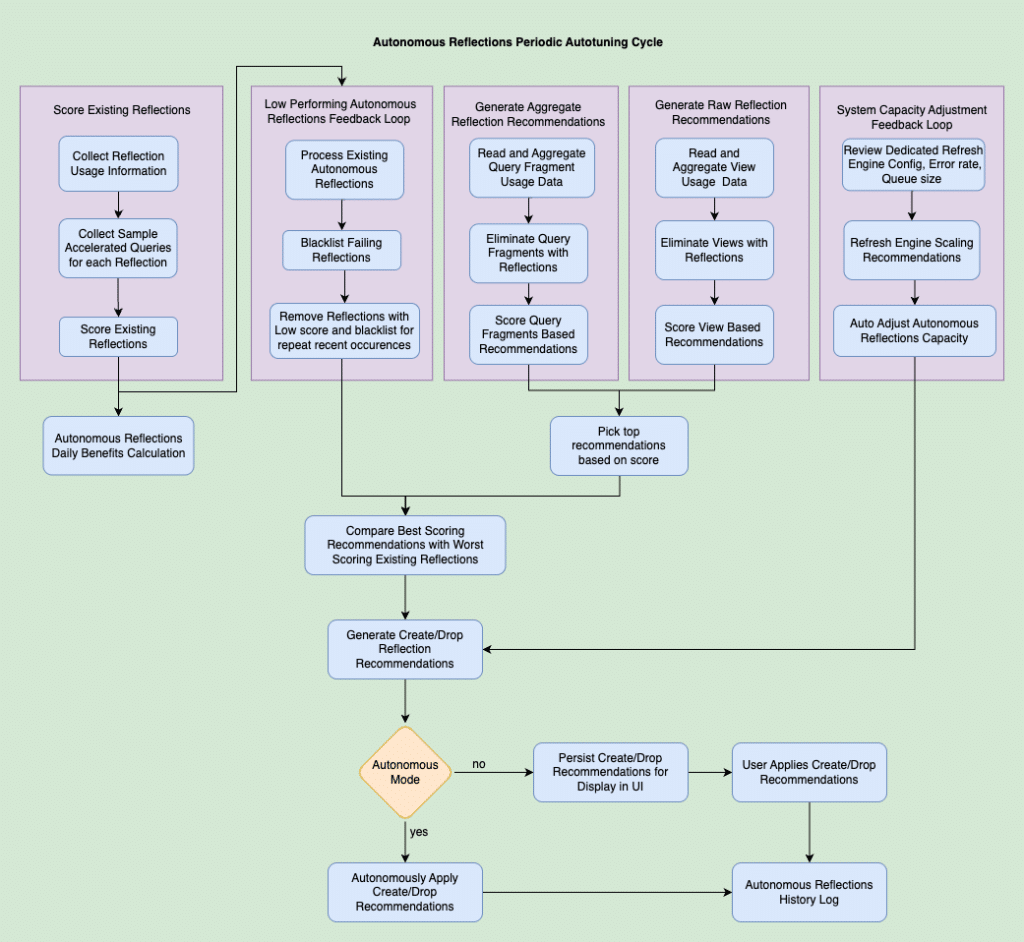
This diagram represents the complete life cycle of an Autonomous Reflection. It served as our north star throughout development. While the implementation details evolved as we matured the feature, the core workflow remained constant. It helped us identify our existing capabilities (query acceleration through reflections and parts of reflection maintenance) and what needed to be built.
Collect Usage Information
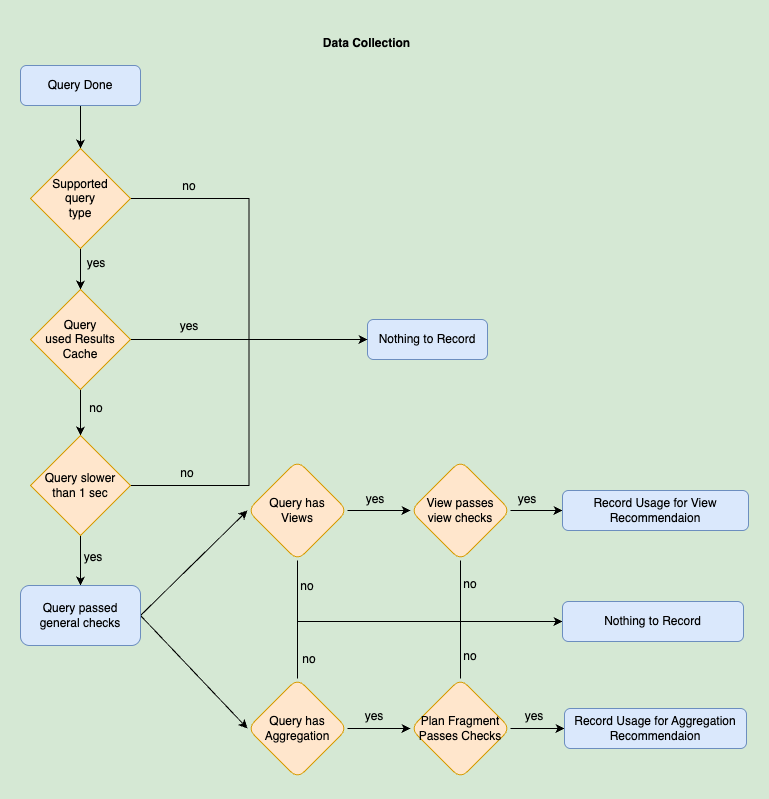
Any query run on Dremio is a potential candidate for acceleration with Autonomous Reflections. To ensure that query performance is not impacted, usage information is collected asynchronously, after the query results have been returned to the user.
We gather two types of usage data relevant to the Autonomous Reflections we create:
view usage information that is used for creating Default Raw Reflections on an existing user created view.
plan fragment hashes that represent a query fragment that is the basis for an Aggregation Reflection recommendation. For each view or plan fragment hash we aggregate the usage data on a daily level and keep a sample of 10 job IDs per day using reservoir sampling.
In all cases, the workload analysis is done in the customer’s environment, and is used by Dremio locally to make decisions on what reflections to create or drop.
Not every query qualifies for Autonomous Reflections. Here are the criteria we check:
Query Type: We focus on queries that can benefit from acceleration, such as Select queries. We will not try to optimize DML queries such as Update/Insert/Delete as those don’t usually benefit from reflections
Query runtime: The query should take at least 1 second to run. If it already runs in sub-seconds, it’s considered fast enough, and the potential benefits of a reflection are limited.
Result cache: The query must not be using an existing result cache. We focus on queries that are similar but not identical—such as BI dashboard queries with slight filter variations each time. If the same query is run multiple times in quick succession, we only collect usage from the first run that did not benefit from results cache. The subsequent runs will use the results cache and won't benefit from a reflection even if we created it.
Reflection benefits: The reflection must provide value by aggregating or filtering data. We avoid creating reflections that offer little benefit, such as "SELECT * FROM existing_table," where the reflection would be identical to the base table. We also avoid reflections with high estimated row size and many expanding joins resulting in more expected rows than the base datasets used.
Supported datasets: Only datasets of supported types are considered for recommendations. In v26.0.0, we support Apache Iceberg and Parquet datasets, with plans to include other types in the future.
Recommend Reflections
The Recommend reflections, Cost-Benefits Analysis and Create/Drop reflections phases happens periodically (nightly) when the load on the system is low. We consider the last 7 days the reporting period for which we will be recommending reflections.
Default Raw Reflection recommendations
We review the collected view information and focus on the top views by usage count that don't already have a Default Raw Reflection. We exclude views containing dynamic or non-deterministic functions (e.g., rand()). These views are customer-created, and we recommend adding a Default Raw Reflection on top of them.
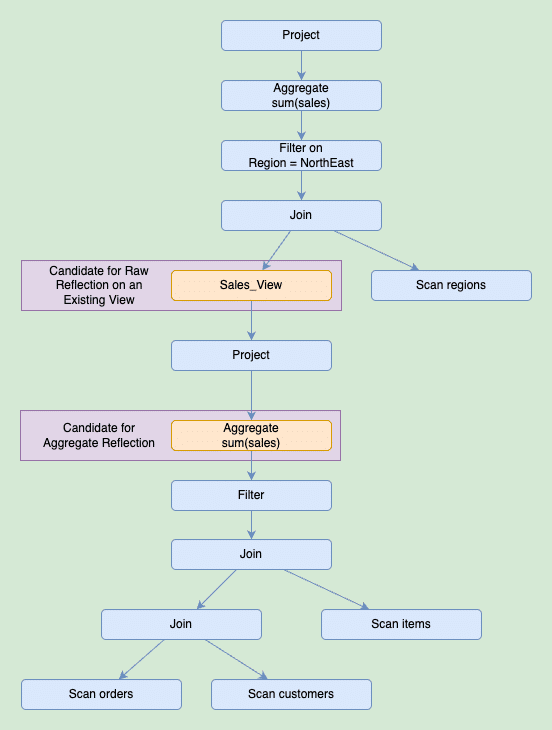
Aggregate Reflection Recommendations
Similarly, we will go through the different plan fragment hashes, and order them by usage count and filter out plan fragment hashes that already have an Aggregate reflection on them. We use some of the jobIds associated with the plan fragment hashes, to rebuild the candidate recommendation.
We build the recommendations in a bottom up fashion, terminating in nodes such as LogicalAggregate with joins under it in the plan if possible. Selecting an aggregation near the bottom of the plan allows for maximum reuse of the recommended reflections. Notice that filters near the top of the plan are not part of the recommended reflection on purpose. This is because they are most likely to be part of a selector in a BI dashboard and subject to change. Filters under the aggregation will be preserved and be part of the recommended reflection. We will look at what kind of projects, filters and aggregations happen in the plan and use that to determine the dimensions and measures of our recommended reflection.
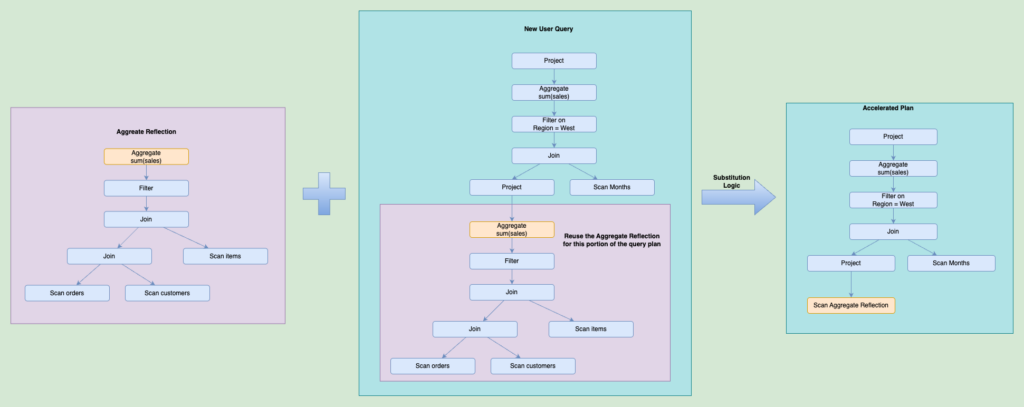
Once we create the reflections, we use them to accelerate queries. In the following diagram, we demonstrate how the aggregate reflection from the previous example is used to accelerate a completely different query. This new user query shares a plan fragment with the original query used for the recommendation, but it has a different filter at the top of the query plan and joins different tables.
Cost-Benefit Analyzer
The Cost-Benefit Analyzer is responsible for scoring both existing reflections and recommendations. It is designed to work independently of the recommendation algorithms, meaning it evaluates reflections without considering the specific algorithm that generated them or the method used. This decoupling allows us to easily develop and integrate new recommendation algorithms into the Autonomous Reflections framework in the future.
The cost-based analyzer works by replanning the query twice, once with the recommendation and once without the recommendation. Then we use the planner cost in both of those cases to give us a rough idea of how useful a recommendation is. The process is repeated for a sample of the queries associated with this recommendation or reflection to improve the accuracy of the estimate.
Replanning instead of reusing the existing planner cost from the original job run helps with queries in our sample that are relatively old. Some of the recommendations might be helping with queries from 7 days ago, so it is important to consider if other reflections introduced in the meanwhile will help. If there is already a similar reflection, the benefits of a reflection recommendation might be low or none and it will have very low score.
Each recommendation or existing reflection is assigned a score on a logarithmic scale from 1 to 100 with 1 being the lowest and 100 being the highest. The score is an estimate of the usefulness of a current or potential future reflection. The scoring algorithm itself is quite complex and outside of the scope of this blog. Some factors that affect the score are:
usage (how many times a reflection has accelerated a query in the reporting period or a recommendation is expected to accelerate a query in the reporting period)
speed up (e.g. a reflection makes a query 5 times faster)
query run time (e.g. it is more impactful to speed up a query 10 times from 10 secs to 1 sec vs 10 times from 2 sec to 0.2 sec)
Create/Drop Recommendations
We support two modes for managing reflection creation and deletion:
Autonomous Mode Enabled: Reflections are automatically created and dropped based on recommendations.
Autonomous Mode Disabled: We still generate recommendations to create and drop reflections, but user action is required to apply them.
We approach the creation of new reflections with caution due to the associated maintenance costs. Strict guardrails are in place to ensure that any created autonomous reflection delivers meaningful query performance improvements. Likewise, once reflections are created, we allow them time to demonstrate their value before considering their deletion. Here are some of the guardrails we have in place:
a reflection recommendation should be useful for at least one query for at least 2 days of the reporting period. That also means you will not get any Autonomous Reflections for 2 days after you upgrade to v26.0, even if you have high system usage.
a reflection recommendation should have estimated daily time savings of at least 60 secs
a reflection recommendation should benefit at least 7 queries for the reporting period
a reflection recommendation should have a speed up of at least 1.2x
a reflection recommendation should have a reflection score of at least 25 out of 100
a reflection recommendation should have an estimated rowcount of 10 Billion rows or less
a reflection recommendation should have an estimated rowcount less than the combined rowcount of all physical datasets used to build it
once created, an autonomous reflection is protected from automatic deletion for 7 days
Reflection Maintenance and Using Reflections to Accelerate Queries
Our goal is to make Autonomous Reflections completely transparent to the end user. When a user runs a query, the data displayed by Dremio should be the same, regardless of whether Autonomous Reflections are used. To achieve this, we must guard against situations where Autonomous Reflections might return stale data. If an Autonomous Reflection falls out of sync with the source data, it will be temporarily excluded from query acceleration until it is refreshed and up-to-date.
To ensure that Autonomous Reflections are up to date, we are reusing the Live mode for reflections on Iceberg datasets that we delivered in v25.1 to trigger reflection refresh immediately after a dataset data change is detected. In addition, in v26.0.0 we will trigger Autonomous Reflection refresh automatically based on your metadata refresh frequency for Parquet datasets too.
Additionally, we take advantage of our incremental refresh improvements to minimize the need for full dataset scans and achieving faster refresh duration. In many cases, Autonomous Reflections can be updated efficiently by only considering the new or modified data:
Append-Only Changes: For datasets with append-only changes (including optimize snapshots on an Iceberg dataset), we only refresh the newly added files.
Updates and Deletes: When there are updates or deletes in the base dataset, we limit the reflection refresh to the affected partitions, provided the partitions of the reflection and the modified base dataset are compatible
Benefits - Dremio’s Internal Data Lakehouse Achieves 10x Faster Performance
At Dremio, we implemented Autonomous Reflections in our own internal Data Lakehouse. We are happy to report that Autonomous Reflections exceeded our expectations. In just days, we saw significant improvements:
80% of dashboards autonomously accelerated—without the need for manual tuning.
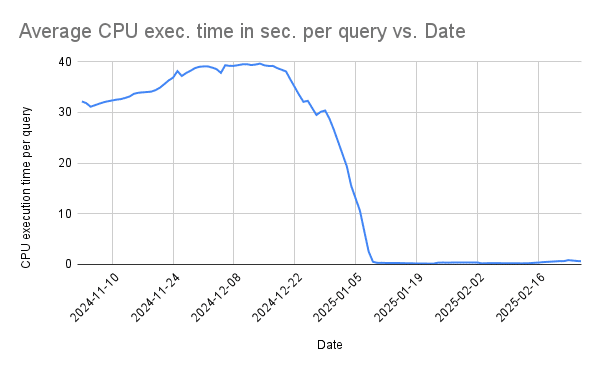
Query response times for the 90th percentile dropped from 13+ seconds to just 1 second.
Average CPU execution time per query improved by 30x, leading to substantial efficiency gains.
By reducing query load, we were able to scale down our consumption engine, freeing up resources for a dedicated Reflections refresh engine. This engine operates efficiently, automatically shutting down when idle—further optimizing costs without sacrificing performance.
Key takeaways
Automating query optimization is essential to maintain performance as data scales or query patterns evolve. It eliminates the manual effort required to tweak and optimize every query.
Dividing a large feature (like Autonomous Reflections) into smaller, manageable MVPs (Minimum Viable Products) and delivering them incrementally helps gather valuable feedback early and provides immediate customer value.
We knew reflections would help, but we were pleasantly surprised by how much they ended up speeding up our internal data lakehouse
Try Dremio Cloud free for 30 days
Deploy agentic analytics directly on Apache Iceberg data with no pipelines and no added overhead.
Column nullability serves as a safeguard for reliable data systems. Apache Iceberg's capabilities in enforcing and evolving nullability rules are crucial for ensuring data quality. Understanding the null, along with the specifics of engine support, is essential for constructing dependable data systems.
Apr 28, 2025·Engineering Blog
Dremio’s Apache Iceberg Clustering: Technical Blog
Clustering is a data layout strategy that organizes rows based on the values of one or more columns, without physically splitting the dataset into separate partitions. Instead of creating distinct directory structures, like traditional partitioning does, clustering sorts and groups related rows together within the existing storage layout.
Jul 1, 2025·Dremio Blog: Open Data Insights
Benchmarking Framework for the Apache Iceberg Catalog, Polaris
The Polaris benchmarking framework provides a robust mechanism to validate performance, scalability, and reliability of Polaris deployments. By simulating real-world workloads, it enables administrators to identify bottlenecks, verify configurations, and ensure compliance with service-level objectives (SLOs). The framework’s flexibility allows for the creation of arbitrarily complex datasets, making it an essential tool for both development and production environments.