14 minute read · July 20, 2021
Azure Storage Types and Use Cases

Azure Storage Types
Azure Storage is a Microsoft-managed cloud service that provides storage that is highly available, secure, durable, scalable and redundant. Whether it is images, audio, video, logs, configuration files, or sensor data from an IoT array, data needs to be stored in a way that can be easily accessible for analysis purposes, and Azure Storage provides options for each one of these possible use cases.Within Azure there are two types of storage accounts, four types of storage, four levels of data redundancy and three tiers for storing files. We will explore each one of these options in detail to help you understand which offering meets your big data storage needs.
Azure Storage Account Types
Types of Azure Storage
An Azure storage account is an access point to all the elements that compose the Azure storage realm. Once the user creates the storage account, they can select the level of resilience needed and Azure will take care of the rest. A single storage account can store up to 500TB of data and like any other Azure service, users can take advantage of the pay-per-use pricing model.There are two different storage account types. With the “standard” storage account, users get access to Blob Storage, Table Storage, Queue Storage and File Storage. The alternative, “premium” account, is the most recent storage option which provides users with data storage on SSD drives for better I/O performance; this option supports only page blobs.
Azure Blob Storage
Blob Storage is Microsoft Azure’s service for storing binary large objects or blobs which are typically composed of unstructured data such as text, images, and videos, along with their metadata. Blobs are stored in directory-like structures called “containers.”The blob service includes:
- Blobs, which are the data objects of any type
- Containers, which wrap multiple blobs together
- Azure storage account, which contains all of your Azure storage data objects
Blob Storage Categories
Although blob allows for storage of large binary objects in Azure, these are optimized for three different storage scenarios:
- Block blobs: These are blobs that are intended to store discrete objects such as images, log files and more. Block blobs can store data up to ~5TB, or 50,000 blocks of up to 100MB each.
- Page blobs: These are optimized for random read and write operations and can grow up to 8TB in size. Within the page blob category, Azure offers two types of storage: standard and premium. The latter is the most ideal for virtual machine (VM) storage disks (including the operating system disk).
- Append Blobs: Optimized for append scenarios like log storage, append blogs are composed of several blocks of different sizes — up to a maximum of 4MB. Each append blob can hold up to 50,000 blocks, therefore allowing each append blob to grow up to 200GB.
Blob storage accounts offer three types of tiers that are selected at the time of creation of the storage account.
- Hot Access Tier: Out of the three options, the hot access tier is the most optimized for data that is accessed frequently. It offers the lowest access (read-write) cost, but the highest storage cost.
- Cool Access Tier: This option is better suited for use cases where data will remain stored for at least 30 days and is not accessed frequently. Compared to hot access tiers, this tier offers lower storage costs and higher access costs.
- Archive Access Tier: Archive storage is designed for data that doesn’t need to be accessed immediately. This tier offers higher data retrieval costs, and also higher data access latency. It is designed for use cases where data will be stored for more than 180 days and is rarely accessed.
Why Use Blob Storage?
Much of what data consumers do with storage is focused on dealing with unstructured data such as logs, files, images, videos, etc. Using Azure’s blob storage is a way to overcome the challenge of having to deploy different database systems for different types of data. Blob storage provides users with strong data consistency, storage and access flexibility that adapts to the user’s needs, and it also provides high availability by implementing geo-replication.
Azure Table Storage
Azure Table Storage is a scalable, NoSQL, key-value data storage system that can be used to store large amounts of data in the cloud. This storage offering has a schemaless design, and each table has rows that are composed of key-value pairs. Microsoft describes it as an ideal solution for storing structured and non-relational data, covering use cases ranging from storing terabytes of structured data that serves web applications, to storing datasets that do not require complex joins or foreign keys, to accessing data using .NET libraries.
Azure Table Storage Components
Table storage includes:
- A storage account, which contains all your tables.
- Tables, which are composed of collections of “entities.”
- Entities, which are sets of properties, similar to database rows. An entity can grow to up to 1MB in size.
- Properties, the most granular element in the list, are composed of name-value pairs. Entities can wrap up to 252 properties to store data, and each entity contains three system properties that define its partition key, row key and timestamp.
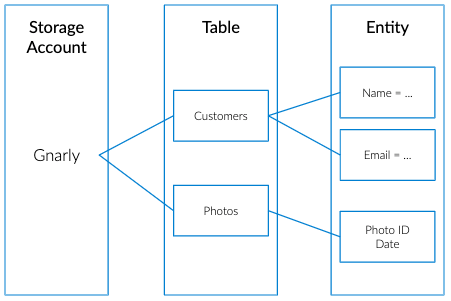 Because Azure Storage tables are represented in a tabular format, they can be easily confused with RDBMS tables. However, Azure tables don’t have the notion of columns, constraints or 1:1 or 1:* relationships and any of their variations.
Because Azure Storage tables are represented in a tabular format, they can be easily confused with RDBMS tables. However, Azure tables don’t have the notion of columns, constraints or 1:1 or 1:* relationships and any of their variations.
Azure Table Storage vs. Azure SQL Database
These two technologies, while very similar, are designed to tackle very different use cases. However, one of the main differences between the two is their capacity. Azure tables can have rows of up to 1MB in size with no more than 255 properties including the three identifying keys: partition, row and timestamp. Meaning, that when users add the size of all 255 properties, they can’t exceed 1MB.On the other side, Azure SQL databases can have rows up to 2GB in size. Naturally, this would make the user think that Azure SQL databases are a no-brainer when it comes to storing large amounts of data. However, Azure SQL databases can scale up to 150GB only, while the maximum data size for Azure tables is 200TB per table.
Why Use Azure Table Storage?
Azure table storage enables users to build cloud applications easily without worrying about schema lockdowns. Developers should consider using Azure table storage when they want to store data in the range of multiple terabytes, while keeping storage costs down — when the data stored does not depend on complex server-side joins or other logic. Additional use cases include disaster recovery scenarios, or storing data up to 500TB without the need to implement sharding logic.
Azure Queue Storage
Queues have been around for a long time — their simple FIFO (first in, first out) architecture makes queues a versatile solution for storing messages that do not need to be in a certain order. In simple terms, Azure Queue Storage is a service that allows users to store high volumes of messages, process them asynchronously and consume them when needed while keeping costs down by leveraging a pay-per-use pricing model.
Azure Storage Queues Components
Queue storage is composed of the following elements:Storage Account, which contains all your storage services.Queue, composed of a set of messages.Message, includes any kind of information. For example, a message could be a text message that is supposed to trigger an event on an app, or information about an event that has happened on a website. A message, in any format, can only be up to 64KB in size and the maximum time that a message can remain in a queue is seven days.However, a single queue can hold up to 200TB worth of messages. Messages can be text strings or arrays of bytes containing any kind of information in formats such as XML, CSV, etc.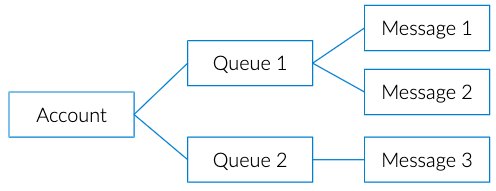
Why Use Azure Queue Storage?
Queues reduce the possibility of data loss due to timeouts on the data store or long-running processes; a good example of this scenario is a shopping cart or a forum where a user can place an “order” in the shape of a purchase or a message on a message board. A reader will then take care of ingesting or “de-queuing” the message while returning control to the user so they can continue navigating the site.Queues allow users to accept all information that comes in and then deal with it at the pace of the application. Going back to the shopping cart scenario, imagine a situation where a user places over 50 items on a shopping cart and is ready to check out. Once the user checks out, if a queue is not in place, the order information would have to be processed and stored in the database immediately, and as you can imagine, during peak times this could create a bottleneck and bring down the entire system. Queues provide a fault-tolerant mechanism where all the orders can be stored for a limited amount of time and then processed and executed as the system has bandwidth to do so. This way it is guaranteed that each element in the queue will receive attention.
Azure File Storage
Azure Files is a shared network file storage service that provides administrators a way to access native SMB file shares in the cloud. These shares — as well as the rest of the Azure storage offerings — can be set as part of the Azure storage account. The Azure File service provides a way for applications running on cloud VMs to share files among them by using standard protocols like WriteFile or ReadFile.
Why Use Azure File System (AFS)
There are many different scenarios in which you might want to use Azure File System:
- If you have an on-premises environment that requires a file share, and need to lift and shift it to the cloud, AFS provides an easy way to share files among cloud VMs. AFS allows users to set up a shared drive without the need to create a dedicated VM to handle the file share workload.
- AFS can also be used to simplify cloud development; it can be set as a shared resource for developers and sysadmins to have a central share when installing tools and applications.
- It can serve as the central location for config files and monitoring logs.
Benefits of Azure Files
Easy to manage: To deploy a shared file, all users need to do is navigate to their storage account and create a new file share. Within minutes the user will have a fully functional file share up and running.Secure storage: Azure file storage encrypts data at rest and in transit using Server Message Block (SBM 3) and HTTPS.Cross-platform support: Azure file uses the SMB protocol, which is natively supported by many open source APIs, libraries and tools.Highly Scalable: Users can store up to 5TB of data — or up to 100TB if they configure the share in the premium tier.Hybrid Access: Azure File Sync allows users to access data anywhere through SMB and REST protocols. This service provides a way to extend file shares to on-premises deployments by creating a local cache of the files providing local access through protocols such as NFS, SMB, FTPS and more. This type of synchronization allows users to have highly available access to their files and also the opportunity to implement enterprise-grade security protocols such as ACLs.
Sign up for AI Ready Data content
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
The Why and How of Using Apache Iceberg on Databricks
Dremio Blog: Open Data Insights,
Learn More ->

BLOG
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
Dremio Blog: Open Data Insights,
Learn More ->