dremio product
SQL Query Engine
The fastest SQL engine with the best price-performance for Apache Iceberg, built on Apache Arrow.
OVERVIEW
A Lakehouse Query Engine optimized for high performance and efficiency on Apache Iceberg and all your data
Sub-second BI workloads directly on your data lake and across all your data sources with no data movement. Deliver a seamless end-user experience with transparent SQL query engine optimization and acceleration, optimized for Apache Iceberg and powered by the Agentic Lakehouse.
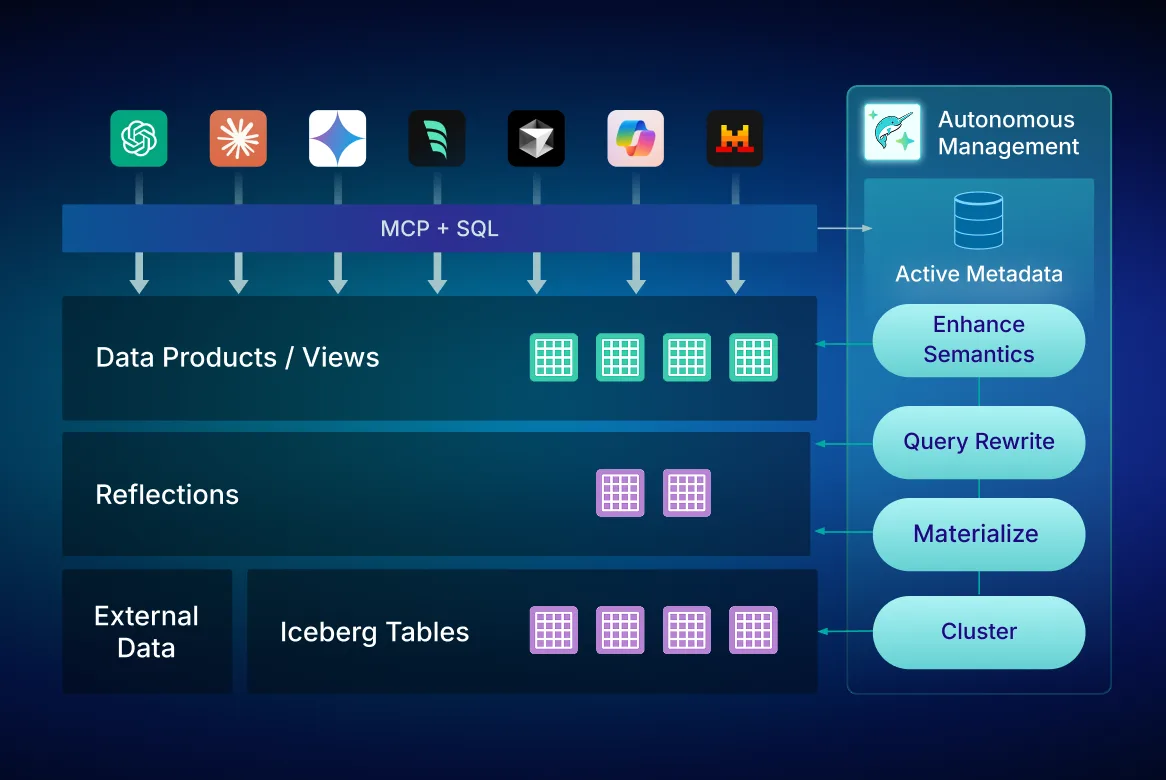
The #1 SQL Engine for Apache Iceberg
Designed from the ground up to be the fastest, most performant, and powerful SQL query engine for Apache Iceberg, Dremio delivers superior query performance and optimized price-performance across all your data. Real-time memory management dynamically manages memory and optimizes allocation, reducing memory usage while heightening performance, scalability, and stability—ensuring successful analytical query operations even with vast datasets.
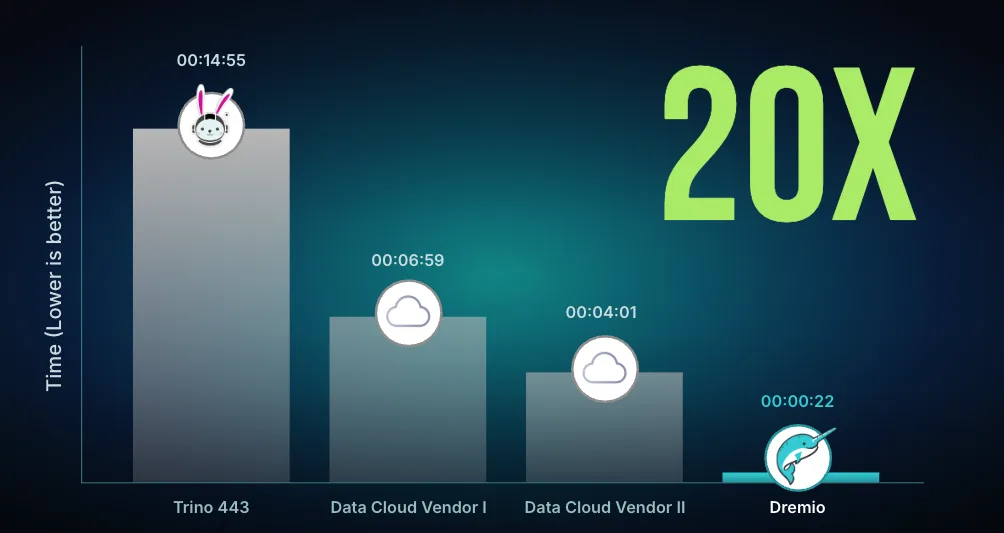
As co-creators of Apache Iceberg, Dremio delivers native optimizations that other query engines cannot match. Automatic Iceberg Clustering optimizes file layouts continuously, eliminating the manual tuning required by traditional systems and delivering 20× performance at the lowest cost.
Learn more about how Apache Iceberg powers improved performance
Optimized price performance for every engine query
Execute every query with the optimal balance of speed and cost-effectiveness. Dremio's multi-engine architecture enables sophisticated workload management. It's simple to create multiple right-sized, physically isolated engines for various workloads in your organization, ensuring market-leading concurrency, performance predictability, and making it easy to manage critical SLAs.
Intelligent autoscaling dynamically manages your query workload based on established engine parameters, ensuring you only pay for what you use with consumption-based pricing.
Cost-based optimization ensures the fastest path to complete every engine query by understanding deep data statistics, including location, cardinality, and distribution—delivering industry-leading price-performance without manual tuning.
Learn how workload management drives the best price performance


Up to 100x faster performance with Reflections query acceleration
Attain near-instantaneous query performance with Autonomous Reflections—optimized relational caches that use algebraic matching to accelerate entire or partial queries automatically. Reflections are completely transparent to data users and require no manual configuration or maintenance. During query execution, the Dremio optimizer automatically matches the best Reflections to accelerate the query, freeing platform teams from manual tuning while delivering sub-second performance.
Performance for all queries is also accelerated using Columnar Cloud Cache (C3). C3 selectively caches only the data required to satisfy your workloads, eliminating 90% of I/O costs and delivering the lowest total cost of ownership.
Flexible, fast, lightweight data transformation
Reduce reliance on costly ETL tools and brittle, complex data pipelines. Dremio's query engine makes it easy to apply last-mile data transformations, including filtering, sorting, aggregating, joining, and casting. These transformations can be quickly built as Dremio Views—governed virtual data sets with layered transformations—that can be flexibly shared and modified for downstream data projects.
Views integrate seamlessly with the AI Semantic Layer, providing business context that enables AI agents to understand and leverage your transformations automatically. This eliminates the need for separate transformation pipelines while maintaining governance and lineage throughout the analytics workflow.
Federated querying for all your data, everywhere
Designed for interactive analytics and DML on the data lake, the Dremio SQL Query Engine makes it easy to analyze all of your data—whether on the data lake or in other data sources. Our connector ecosystem features dozens of integrations with an array of sources, including object storage, metastores, and databases in the cloud and on-premises. Because Dremio queries your data at the source with zero-copy architecture, there is no data movement, no data copies, and no complex ETL.
Federated querying enables unified analytics across your entire data landscape while maintaining governance policies and access controls. AI agents can leverage federated queries to access data from multiple sources through a single interface, accelerating insights without data duplication or operational overhead.
Built for the Cloud, Multi-Cloud, on-premises, and hybrid environments
Query your data where it lives—whether in the Cloud, across clouds, on-premises, or in hybrid environments. Dremio understands that many organizations choose to distribute their workloads across different cloud platforms, allowing them to leverage the strengths of each provider while avoiding vendor lock-in. With Dremio, you can access all of your data and put it to analytic work in seconds.
Built on open standards including Apache Iceberg, Polaris, and Arrow, Dremio ensures you're never locked into proprietary formats or vendor-specific architectures. This open approach enables interoperability across your entire data ecosystem while maintaining performance and governance.
Built on Apache Arrow for the fastest performance
Dremio's optimized SQL query engine, powered by Apache Arrow, is core to delivering the best price-performance for queries across all your data. Dremio delivers lightning-fast query performance as well as market-leading query concurrency for lakehouse analytical workloads. In fact, Dremio co-created Arrow and subsequently contributed it to the Apache Foundation.
Arrow Flight is designed from the ground up to support modern analytical workloads for columnar data structures and parallel processing, enabling the high-performance data transfer that powers sub-second query execution across distributed systems.
customer stories
Explore how Dremio enables lakehouse analytics in our customer stories






Frequently Asked Questions
What is a query engine?
A query engine is a specialized software component that processes and executes data queries, translating high-level query languages like SQL into optimized operations that retrieve and transform data from storage systems. Query engines handle query execution by parsing SQL statements, optimizing execution plans, coordinating distributed computing resources, and returning results to users or applications—all while managing memory, parallelism, and performance optimization automatically.
Dremio's SQL query engine goes beyond traditional query execution by integrating directly with Apache Iceberg table formats, enabling advanced optimizations like Autonomous Reflections and Automatic Iceberg Clustering that deliver sub-second performance without manual tuning. Built on Apache Arrow, Dremio's query engine provides the fastest path for SQL querying across data lakes, warehouses, and federated sources—delivering 20× performance at the lowest cost through autonomous operations that eliminate operational overhead.
Query engine vs database: What are the main differences?
The distinction between a query engine and a database reflects a fundamental architectural difference in how organizations access and analyze data. A database is a complete system that includes storage, transaction management, data organization, and query processing—all tightly coupled within a single architecture. Traditional databases and data warehouses store data internally with proprietary formats, requiring data copies and vendor lock-in that increase cost and complexity.
A query engine, by contrast, separates query processing from storage, enabling organizations to query data where it lives without copying or moving it. This architectural separation provides several advantages: First, query engines like Dremio enable federated analytics across multiple sources—data lakes, warehouses, databases—without ETL pipelines or data duplication. Second, query engines can leverage open table formats like Apache Iceberg, avoiding vendor lock-in while maintaining performance and governance. Third, modern query engines deliver superior performance through specialized optimizations like columnar processing and vectorized execution that aren't possible in monolithic database architectures.
For complex queries spanning multiple data sources, Dremio's distributed query engine provides unified access with consistent governance and performance—eliminating the need for expensive data warehouses while delivering faster results at lower cost through autonomous optimization and zero-copy architecture.
How does an SQL query engine process data across different sources?
An SQL query engine processes data across different sources through a sophisticated coordination process that federates queries while maintaining performance and governance. When executing queries across distributed sources, the engine parses the SQL statement, identifies which data sources contain relevant tables, generates optimized sub-queries for each source, executes those sub-queries in parallel, and combines results while applying joins, filters, and aggregations—all transparently to the user.
Dremio's approach to cross-source query processing leverages several advanced capabilities: The AI Semantic Layer provides business context that helps the query optimizer understand relationships between datasets across sources, enabling intelligent join planning and predicate pushdown. The zero-copy architecture executes queries directly on source data without requiring ETL or data movement, reducing cost and operational complexity. Autonomous Reflections accelerate frequently accessed data patterns automatically, while Columnar Cloud Cache (C3) optimizes I/O by selectively caching only required data.
This federated approach differs fundamentally from traditional database management systems that require all data to be stored internally. By executing queries directly on Apache Iceberg tables in your data lake while federating to other sources as needed, Dremio eliminates the expensive data copies and complex pipelines required by warehouses—delivering faster insights at lower cost without sacrificing governance or performance.
What role does a query engine play in a data lakehouse?
A query engine is the analytical foundation of a data lakehouse, providing the interface through which users and AI agents access, transform, and analyze data stored in open formats like Apache Iceberg. Unlike traditional architectures where query engines are tightly coupled with proprietary storage, the lakehouse architecture separates storage and compute—enabling the query engine to deliver warehouse-like performance and governance on data lake economics.
In Dremio's Agentic Lakehouse, the query engine serves multiple critical functions: It translates natural language questions from AI agents into optimized SQL through integration with the AI Semantic Layer, ensuring queries reflect business context and semantic definitions. Its execution model leverages Autonomous Reflections to accelerate queries automatically without manual tuning, delivering sub-second performance at scale. The engine enforces fine-grained access controls and maintains lineage tracking, ensuring that both human users and AI agents operate within governance boundaries while querying unified data.
The query engine also enables modeling your Data Lakehouse through virtual datasets and views that provide abstraction layers without data duplication. This flexibility is essential for supporting both traditional BI workloads and modern agentic analytics, where AI agents need to explore data conversationally while platform teams maintain performance and governance. Unlike SQL Server and other traditional systems that require data copies, Dremio's query engine operates directly on open lakehouse data—eliminating vendor lock-in while delivering superior performance through autonomous optimization.
Why is Apache Iceberg important for engine query performance?
Apache Iceberg is foundational to modern engine query performance because it provides the table format capabilities that enable advanced optimizations impossible with traditional file formats. Iceberg's architecture includes features like hidden partitioning that eliminates user errors, time travel for accessing historical data, schema evolution without table rewrites, and metadata management that enables efficient query planning—all essential for big data analytics at lakehouse scale.
For query engines, Iceberg's metadata layer is particularly transformative. Rather than scanning entire directories to understand data distribution, query engines can leverage Iceberg's metadata to perform partition pruning, predicate pushdown, and intelligent file selection—reducing the data scanned by orders of magnitude. This metadata-driven approach enables sub-second query performance on petabyte-scale datasets that would take minutes or hours with traditional formats.
Dremio's position as co-creators of Apache Iceberg enables optimizations that other engines cannot match. As the best SQL engine for Apache Iceberg, Dremio delivers native integration with Iceberg's capabilities while adding autonomous features like Automatic Iceberg Clustering that continuously optimize file layouts without manual intervention. Combined with Autonomous Reflections that accelerate query patterns automatically, Dremio delivers 20× performance on Iceberg tables at the lowest cost—enabling organizations to scale big data analytics without the operational burden or expense of traditional data warehouses.
Can a distributed query engine run queries on cloud and on-prem data?
Yes, modern distributed query engines are specifically designed to run queries across hybrid environments that span cloud and on-premises infrastructure. This capability, called federated querying, enables organizations to analyze data wherever it resides without requiring data movement or creating separate analytical silos. A distributed query engine coordinates query execution across multiple sources, pushing computation to where data lives, retrieving partial results, and combining them into unified answers—all transparently to users.
Dremio's distributed architecture excels at hybrid deployment scenarios because it's built on open standards that work consistently across environments. Whether your data resides in AWS S3, Azure Data Lake Storage, Google Cloud Storage, on-premises HDFS, or across multiple locations, Dremio federates queries with the same performance optimizations and governance controls. The zero-copy architecture means you never duplicate data to enable analytics—reducing storage costs, eliminating ETL pipelines, and maintaining a single source of truth regardless of physical location.
This hybrid capability is essential as organizations navigate multi-cloud strategies and gradual cloud migration. Teams can begin analyzing cloud data immediately while maintaining access to on-premises systems, all through a single query interface backed by unified governance. The Data Lakehouse architecture that Dremio pioneered enables this flexibility by separating storage from compute, ensuring you're never locked into a single vendor or environment while maintaining the performance and governance required for enterprise analytics.
How does Data Lakehouse query acceleration improve analytics speed?
Data Lakehouse query acceleration improves analytics speed through multiple complementary techniques that reduce data scanning, optimize execution plans, and leverage intelligent caching—all working together to deliver sub-second performance on large-scale datasets. Traditional approaches to acceleration require manual tuning, index creation, and materialized views that create operational overhead and increase costs. Modern lakehouse acceleration automates these optimizations while maintaining consistency with source data.
Dremio's approach to query acceleration is fundamentally autonomous, eliminating the manual work required by traditional systems. Autonomous Reflections automatically identify frequently queried data patterns and create optimized representations that accelerate both full and partial queries through algebraic matching. Unlike traditional materialized views that require manual definition and maintenance, Reflections learn from query patterns and optimize themselves continuously—delivering up to 100× faster performance without platform team intervention.
Additional acceleration comes from Columnar Cloud Cache (C3), which selectively caches only the data required for active workloads, eliminating 90% of I/O costs while maintaining up-to-date results. Automatic Iceberg Clustering optimizes file layouts based on actual query patterns, improving partition pruning and reducing data scanned per query. These autonomous optimizations work together to deliver industry-leading price-performance: organizations get 20× faster queries at the lowest cost, without the manual tuning burden of traditional warehouses or the expensive over-provisioning required by systems that lack intelligent acceleration.
What are federated queries?
Federated queries are SQL operations that access and combine data from multiple heterogeneous sources—data lakes, databases, warehouses, and cloud storage—through a single query interface, without requiring data movement or creating copies. Federated querying enables organizations to analyze their complete data landscape as if it were unified, while data physically remains distributed across systems. This approach eliminates the expensive ETL pipelines and data duplication that traditional analytics architectures require.
In Dremio's implementation of query federation, queries execute with full optimization and governance regardless of source location. The query engine pushes predicates and projections down to source systems when possible, retrieves only required data, and performs final joins and aggregations efficiently using Apache Arrow's columnar processing. Users write standard SQL without needing to understand which physical systems store which tables—the federation layer handles complexity transparently.
This federated querying capability is essential for the Agentic Lakehouse, where AI agents need to access data from across the organization without encountering technical barriers or governance gaps. The AI Semantic Layer provides business context that works consistently across federated sources, ensuring AI agents interpret data correctly regardless of physical location. Fine-grained access controls enforce permissions uniformly across all sources, maintaining security even as queries span multiple systems. By federating data access rather than replicating data, organizations reduce costs, eliminate pipeline maintenance, and ensure AI agents always work with current, governed information—accelerating the path to AI-powered insights without operational overhead.
How do cost-based optimizations improve query performance?
Cost-based optimizations improve query performance by analyzing multiple possible execution strategies and selecting the approach that minimizes computational cost—measured in factors like data scanned, memory used, network transferred, and CPU cycles consumed. The query optimizer evaluates join orders, considers whether to push operations to source systems, determines when to leverage cached data, and selects optimal physical operators—all based on statistics about data distribution, cardinality, and access patterns.
Dremio's cost-based optimizer goes beyond traditional approaches by incorporating real-time understanding of lakehouse-specific optimizations. It knows which Autonomous Reflections are available and automatically rewrites queries to leverage them when beneficial. It understands Iceberg metadata deeply, enabling intelligent partition pruning and file selection that reduces data scanned by orders of magnitude. The optimizer also considers Columnar Cloud Cache (C3) contents, preferring execution plans that leverage cached data when it provides performance advantages.
This intelligent optimization delivers an optimized query execution path for every request without requiring manual intervention or tuning from platform teams. Combined with Automatic Iceberg Clustering that continuously optimizes physical data layout, Dremio's cost-based approach ensures queries maintain optimal engine price performance as data volumes grow and query patterns evolve. Organizations benefit from consistently fast results at the lowest cost—without the manual index creation, statistics collection, and query tuning that traditional systems require, freeing platform teams to focus on strategic priorities instead of performance firefighting.
When should teams use a distributed SQL query engine?
Teams should use a distributed SQL query engine when they need to analyze data at scale across multiple sources while maintaining performance, governance, and cost efficiency. Specific scenarios where distributed query engines deliver transformative value include: analyzing data lakes with petabyte-scale datasets that exceed single-node processing capabilities; federating queries across heterogeneous sources without ETL pipelines; supporting high concurrency for numerous simultaneous users and AI agents; enabling real-time and interactive analytics that require sub-second response times; and scaling analytics across cloud, multi-cloud, and hybrid environments without vendor lock-in.
The architectural advantages of distributed query engines become essential as data volumes and analytical demands grow. Traditional single-node databases cannot scale to handle modern data volumes or concurrent user loads without prohibitive costs. Data warehouses require expensive data copies and proprietary formats that create lock-in. Distributed SQL query engines like Dremio solve these challenges by parallelizing query execution across compute clusters, federating access to data wherever it lives, and leveraging open table formats like Apache Iceberg that enable warehouse-like performance on lake economics.
Beyond scale and performance, distributed query engines enable the Agentic Lakehouse architecture where AI agents access unified, governed data through natural language interfaces. The combination of distributed computing, autonomous optimization, and semantic understanding creates an environment where business professionals and AI agents can explore data conversationally at any scale. With features like query stability ensuring reliable execution even for complex long-running queries, distributed SQL query engines provide the foundation for enterprise AI adoption—delivering the fastest path to insights at the lowest cost without operational burden or vendor lock-in.