10 minute read · December 19, 2025
7 Ways Dremio’s Vectorized Architecture Redefines Lakehouse Performance
· Head of DevRel, Dremio

The most expensive resource isn’t just CPU or storage, it’s time. For the data architect, nothing is more frustrating than watching a multi-terabyte query crawl due to architectural friction. Often, the bottleneck isn't the data size itself, but the legacy "tax" imposed by how that data is moved, translated, and cached.
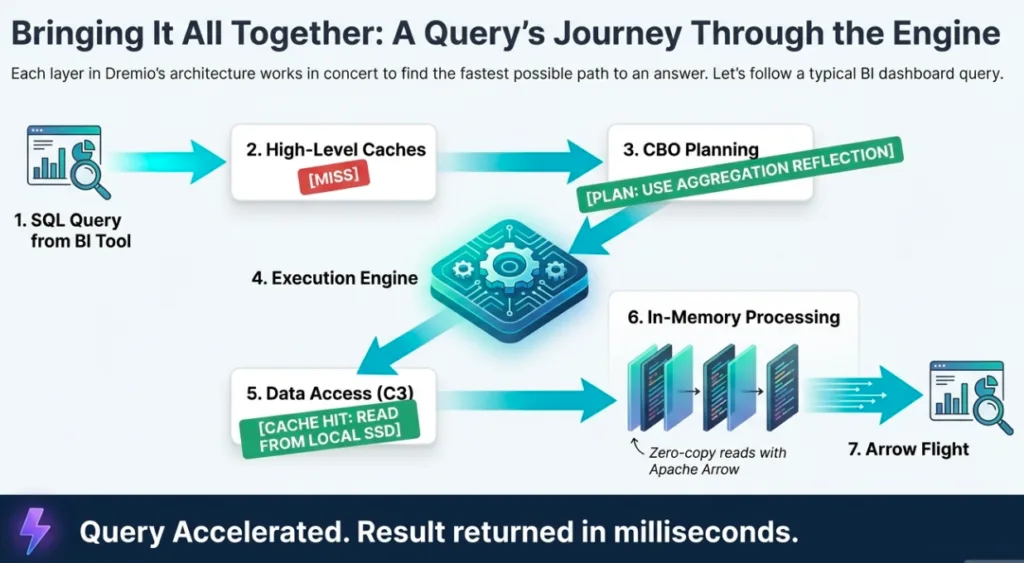
Dremio is more than just a query engine; it is a fundamental paradigm shift in how we handle data at scale. By reimagining the journey of a bit from object storage to the end-user’s memory, Dremio eliminates the traditional speed-to-insight bottleneck. It treats performance as an inherent property of the architecture rather than a manual tuning exercise.
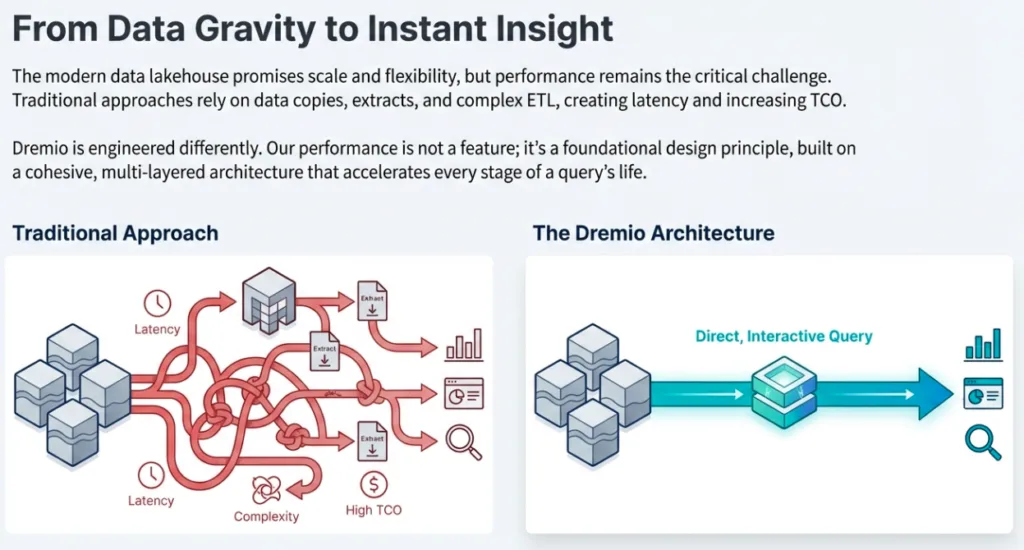
1. The Unified Language of Apache Arrow and Flight: Ending the Serialization Tax
Historically, data transport has been the "straw" through which we try to pull a "lake" of data. Traditional JDBC and ODBC drivers are row-based legacy protocols that require a heavy "serialization tax", the CPU-intensive process of converting columnar data from disk into row-based formats for transport, only to have the application convert it back into columnar memory for analysis.
Dremio breaks this cycle by leveraging Apache Arrow and the Arrow Flight transport standard. Because Dremio uses Arrow as its internal in-memory format, Arrow Flight enables a "firehose" of parallel data streams that move data in its native columnar state. By supporting the ADBC (Arrow Database Connectivity) protocol, Dremio remains client-agnostic, enabling sub-millisecond handoffs to tools such as Python or Power BI. This is the architectural epiphany: by moving the optimization from the application layer to the transport layer, we achieve near-zero-copy data transfer.
Dremio's vectorized Parquet file reader improves parallelism on columnar data, reduces latencies, and enables more efficient resource and memory usage.
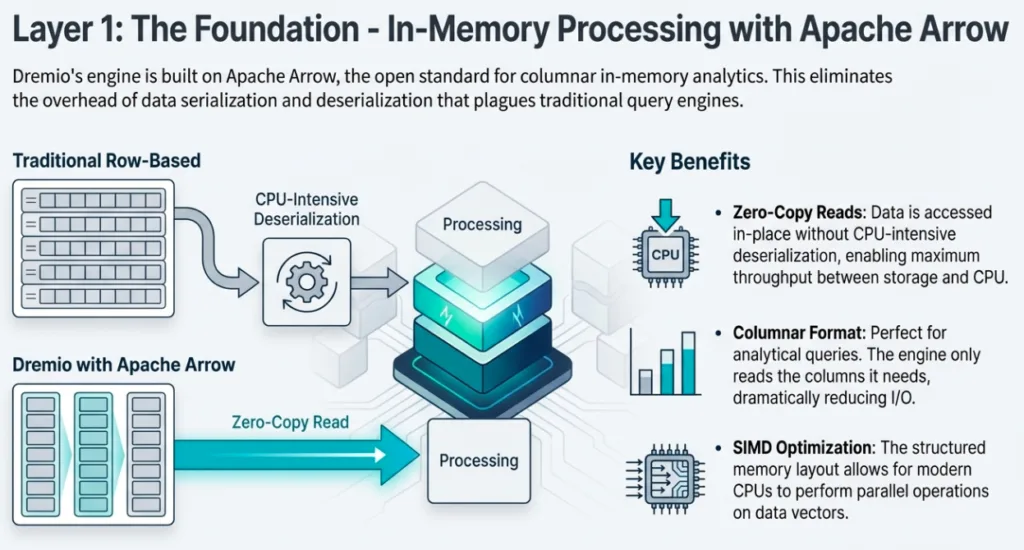
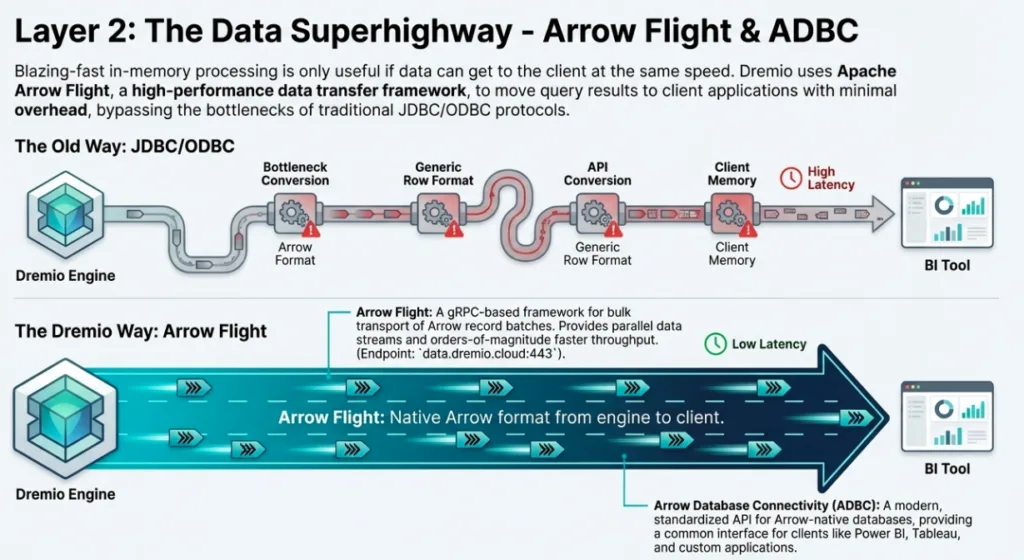
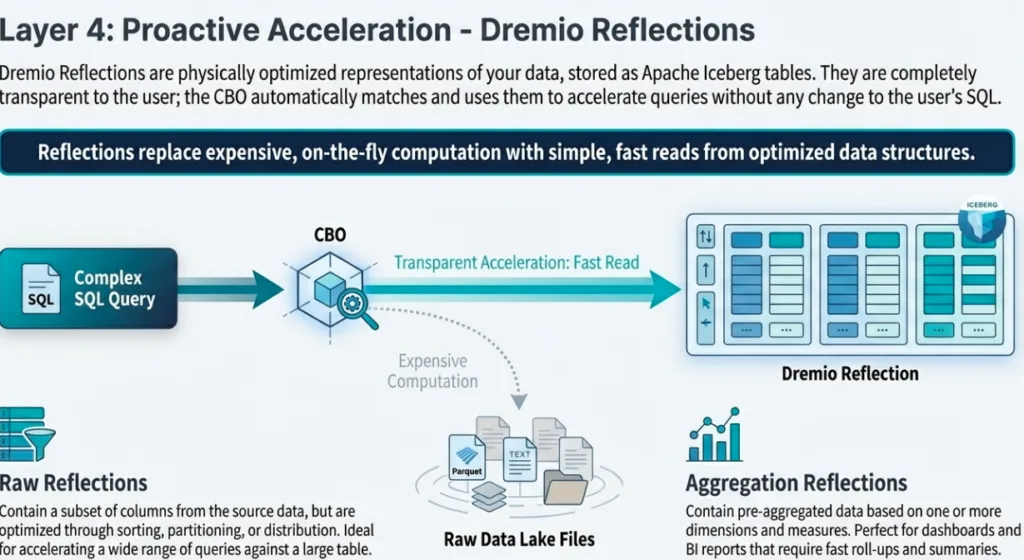
2. Data Reflections: The Magic of Transparent Acceleration
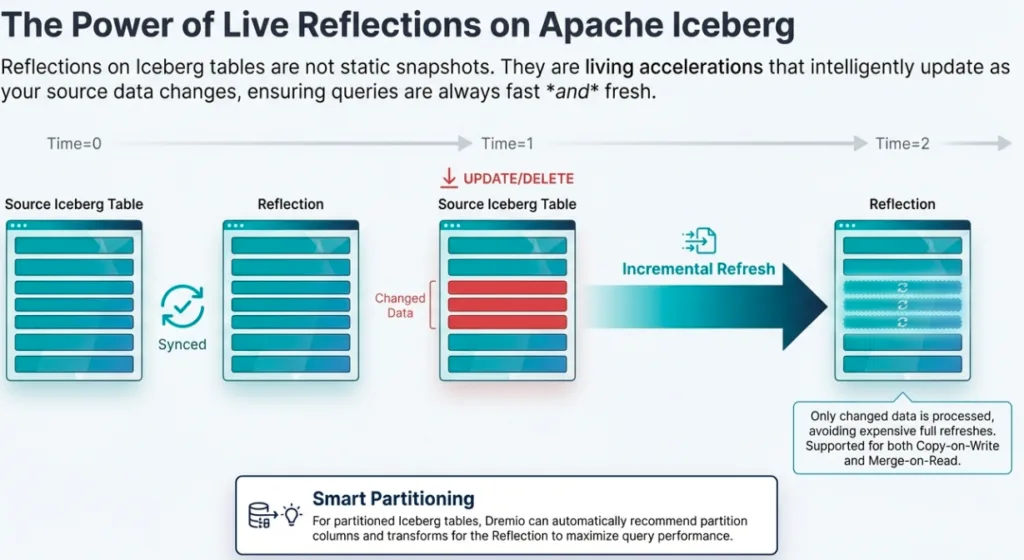
Data Reflections are Dremio’s "secret weapon," but they aren't proprietary black boxes. They are physically optimized Apache Iceberg materializations stored in the data lake..
Reflections come in two flavors: Raw Reflections for accelerating broad scans and Aggregate Reflections for pre-computing complex groupings. The "magic" occurs in the cost-based optimizer: a user writes standard SQL against a view, and Dremio automatically substitutes the most efficient Reflection without the user ever changing their code. To maintain parity with real-time data, Dremio uses a 10-second polling mechanism for Iceberg tables, ensuring incremental refreshes keep the acceleration layer in lockstep with the source.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
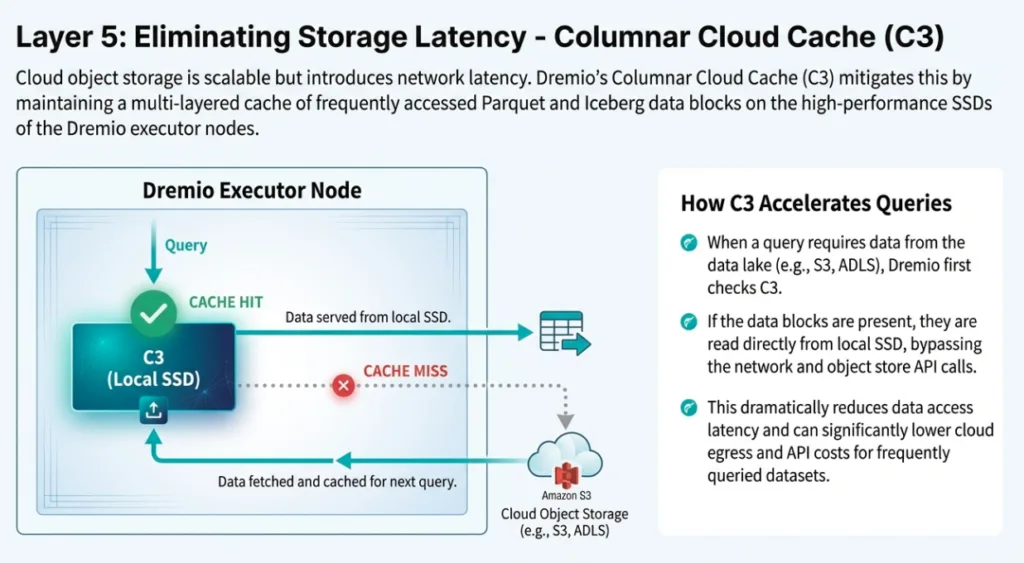
3. Columnar Cloud Cache (C3): Eliminating Object Storage Latency
Cloud object storage (S3, ADLS) provides infinite scale but introduces significant network latency. Dremio’s Columnar Cloud Cache (C3) bridges the performance gap between local NVMe speed and cloud-scale storage.
C3 resides on local NVMe storage on executor nodes, automatically caching data as it is read from the lake. This creates a "hot" tier for the lakehouse. Instead of fetching data across the network for every repeated query, C3 provides sub-millisecond response times by serving data directly from the executor's local storage. For an architect, this means the performance characteristics of a local data warehouse are now available at the cost and scale of a data lake.
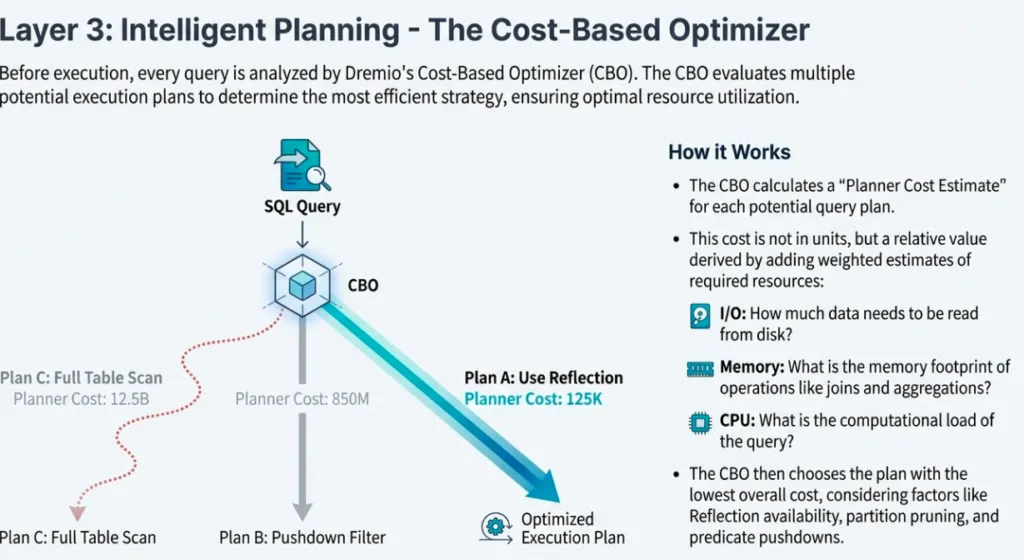
4. The Intelligence Engine: Cost-Based Optimization and AI
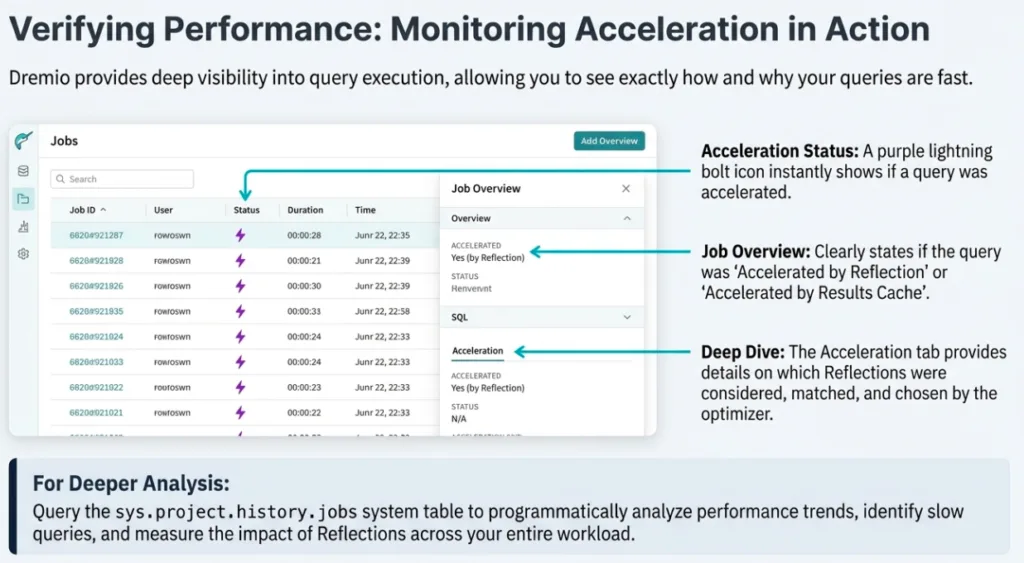
Manual query tuning is a relic of the past. Dremio’s Cost-Based Optimizer (CBO) works in tandem with an AI Agent to understand "optimal performance characteristics."
Through features like "Explain Job" and "Explain SQL," the AI Agent doesn't just provide a high-level summary; it analyzes Dremio’s SQL Parser results to identify performance-killing issues such as data skew, threading efficiency, memory usage, and network utilization. This deep-level synthesis allows the engine to recommend specific optimizations, such as adjusting join orders or creating new Reflections, far more accurately than a human operator could in a petabyte-scale environment.
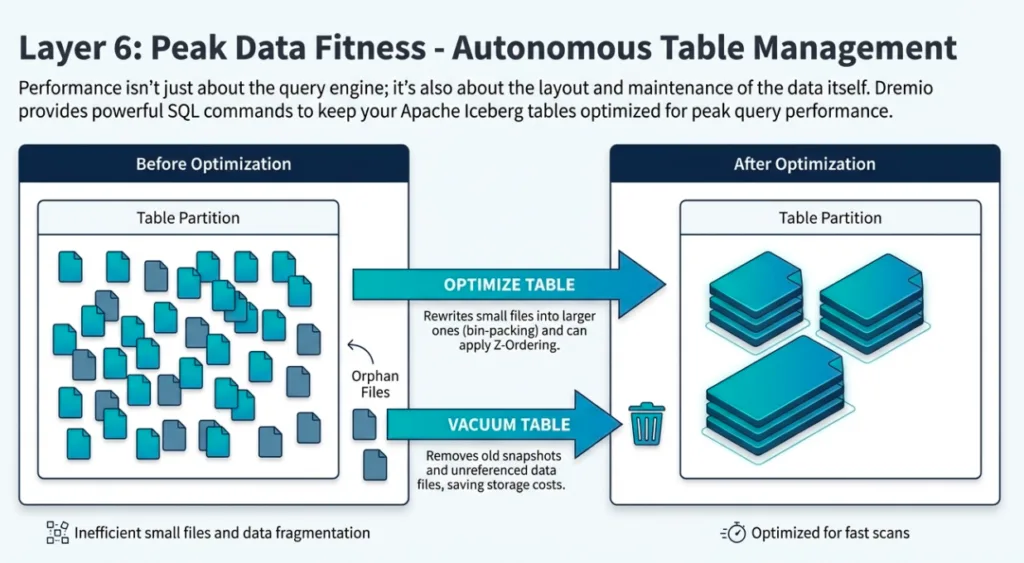
5. Keeping the Lakehouse Lean with Table Optimization
In a distributed system, performance is often defined by what you don't read. Small files and disorganized metadata are the silent killers of query speed. Dremio’s Open Catalog handles this through automated table maintenance using VACUUM and OPTIMIZE commands.
The engine constantly evaluates file sizes, targeting an optimal file size of 256 MB. Beyond simple compaction, Dremio handles Clustering, sorting records in data files based on clustering keys defined in the DDL. By rewriting manifest files and organizing documents into these optimized clusters, Dremio dramatically reduces I/O overhead and metadata bloat, ensuring the lakehouse remains lean and performant over time.
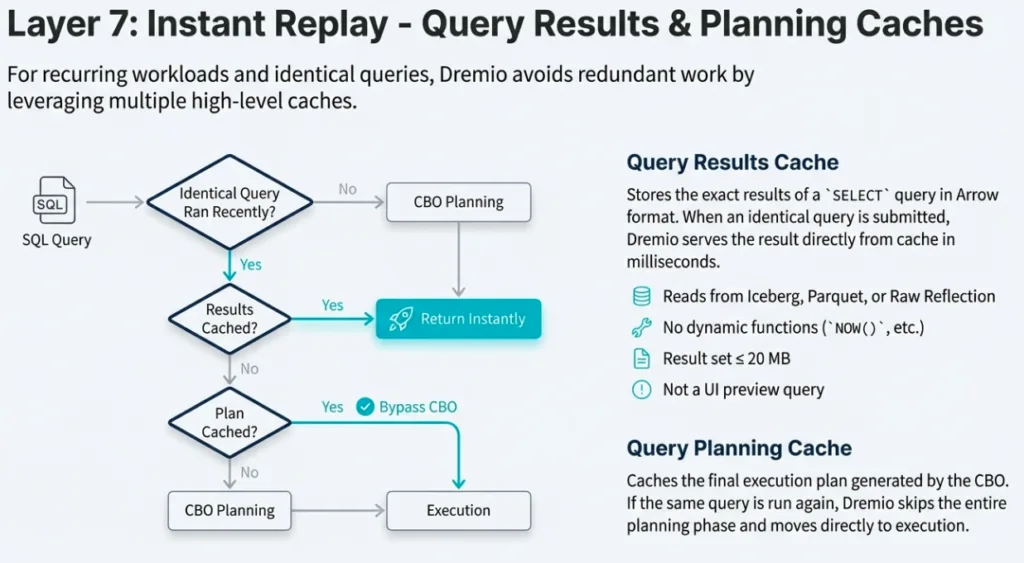
6. Results and Query Planning Caching: Don't Repeat Yourself
The most efficient query is the one you don't have to re-plan or re-execute. Dremio employs a dual-caching strategy:
- Query Planning Cache: Reuses the intelligence of previous SQL parsing and optimization phases.
- Results Cache: Returns data directly if the underlying dataset hasn't changed.
These caches are client-agnostic; a result generated by a BI tool via JDBC can be reused by a data scientist via Arrow Flight. Crucially, this architecture supports seamless coordinator scale-out, allowing new nodes to immediately benefit from the entire cluster's cached intelligence, ensuring consistent performance as the environment grows.
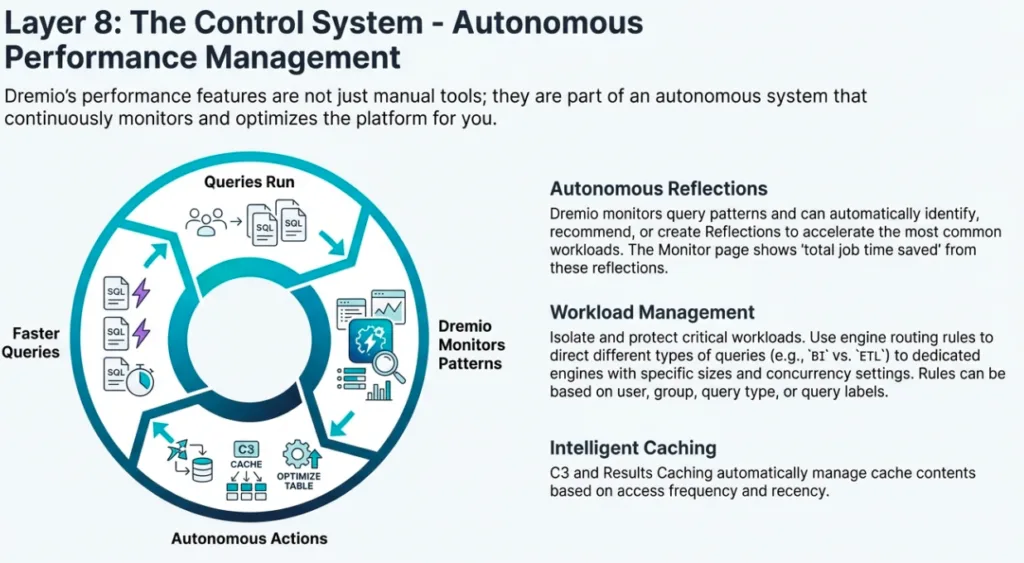
7. Autonomous Performance Management: Scaling on Demand
Dremio removes the burden of infrastructure management through its autonomous query engines. These engines automatically start, scale, and stop based on actual query demand.
By configuring "Min Replicas" and "Max Replicas," architects can balance cost and performance. Setting Min Replicas to 0 enables auto-stop, the ultimate cost-saving measure where compute resources are only consumed during active analysis. Combined with Autonomous Reflections, which recommend acceleration based on real-world query patterns, the system manages its own health. This autonomy allows the organization to stop managing servers and start focusing on the data analysis that actually moves the needle.
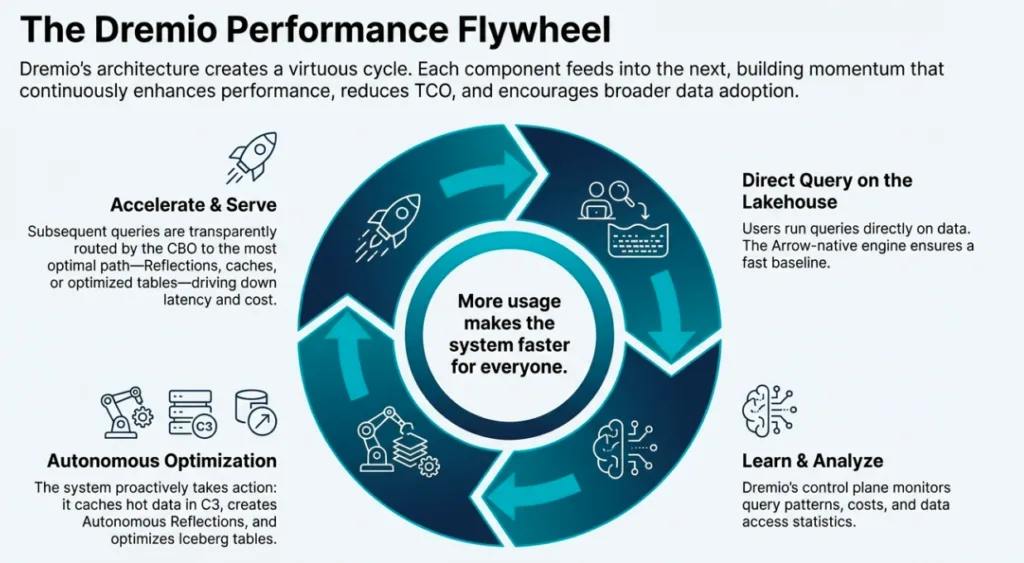
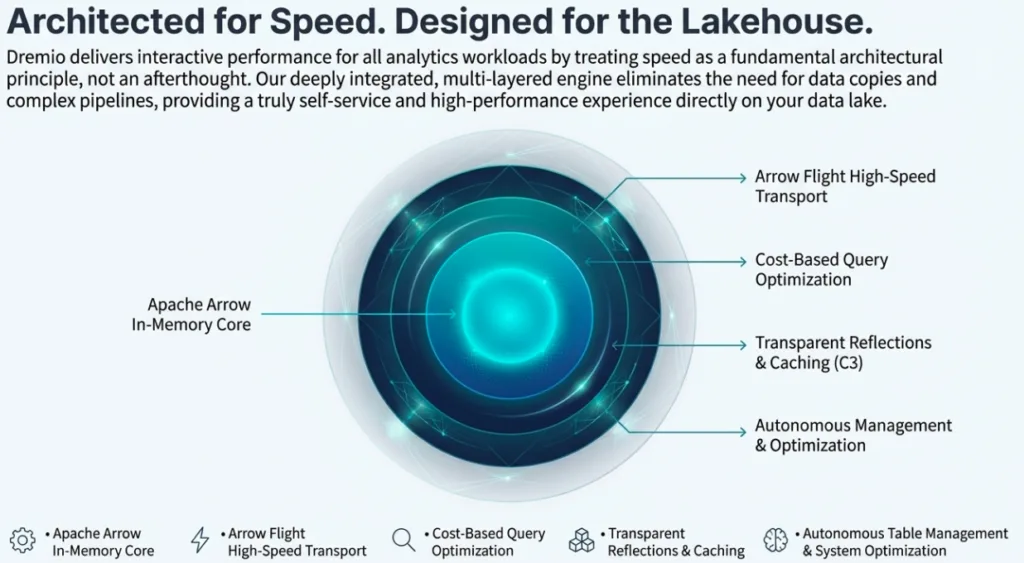
Conclusion: The Future is Vectorized
The Dremio performance story is a narrative of engineering excellence meeting operational simplicity. By combining the efficiency of Apache Arrow, the "magic" of Iceberg-backed Reflections, and the intelligence of an AI-driven optimizer, Dremio has built a system where performance is an automated byproduct of the architecture.
As we look forward, the era of the "serialization tax" and manual tuning is ending. The future of data is vectorized, open-standard, and autonomous. The only question left for the architect is: How much faster could your business move if query latency were no longer a factor?
Additional Resources

BLOG
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Product Insights from the Dremio Blog,
Learn More ->

BLOG
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dremio Blog: News Highlights, Dremio Blog: Open Data Insights, Product Insights from the Dremio Blog,
Learn More ->