DREMIO FEATURE
Query federation across all of your data
Federated queries with no data movement for comprehensive analytic insight
OVERVIEW
Database federation for streamlined queries
Break down data silos with query federation across all of your data - in the cloud, on-premises, multi-cloud or hybrid - with the industry's most price-performant SQL query engine, designed for Apache Iceberg and powered by the Agentic Lakehouse.

Broad connector ecosystem for real-time federation all of your data
Our connector ecosystem features dozens of integrations with an array of sources, including object storage, metastores, and databases in the cloud and on-premises. Because Dremio queries your data at the source with zero-copy architecture, there is no data movement, no copies, and no complex extract, transform, and load (ETL) process.
This broad connectivity enables AI agents to access unified data across your entire ecosystem without encountering technical barriers or requiring data duplication—accelerating the path to AI-powered insights while maintaining governance and reducing operational overhead.
Semantic layer for integrated data access, analytics and insight
The AI Semantic Layer enables a single, verified unified view across all of your data. You'll have consistent, collaborative, governed, and real-time access to data, easily curating virtual data sets or projects with no data movement. The semantic layer provides the business context AI agents need to find the right data and deliver accurate insights across all federated sources.
By embedding business definitions, metric calculations, and data relationships directly into the semantic layer, Dremio ensures that both human users and AI agents interpret data consistently—eliminating the confusion and errors that arise when different teams use different definitions across federated sources.


Built for the cloud, multi-cloud, on-premises and hybrid environments
Query your data where it lives—whether in the Cloud, across clouds, on-premises, or in hybrid environments. Many organizations choose to distribute their workloads across different cloud platforms, allowing them to leverage the strengths of each provider while avoiding vendor lock-in. With Dremio, you can access all of your data and put it to analytic work in seconds.
Built on open standards including Apache Iceberg, Polaris, and Arrow, Dremio ensures interoperability across your entire data ecosystem. This open architecture enables true agent choice—use integrated agents or bring your own with MCP—without proprietary formats or vendor-specific dependencies that limit flexibility.
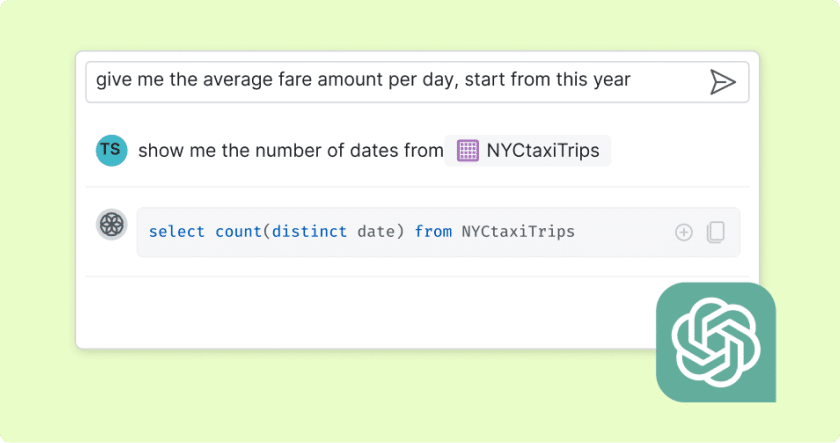
Simplified federated querying: As easy as asking a question with text-to-SQL
Harness the power of conversational AI for seamless data analysis. Dremio's Lakehouse AI Agent allows anyone to query federated data using natural language, making it easier and more intuitive to interact with data across all sources. Type a simple question, and Dremio generates fast, accurate SQL to query any of your data—whether stored in your data lake, cloud warehouses, or on-premises databases.
The AI Semantic Layer ensures that natural language queries understand business context across all federated sources, translating questions into optimized SQL that leverages Autonomous Reflections for sub-second performance. This enables business professionals to explore data across your entire ecosystem without SQL expertise or understanding which systems store which tables.
customer stories
Discover how innovative companies leverage Dremio for federating data


ABC Supply delivers self-service analytics using Dremio to organize domain data and accelerate development
Read more


KION Group Accelerates Data Access on Near Real-Time Supply Chain Analytics with Dremio's Data Lakehouse
Read more


NCR Uses Dremio to Deliver Business Insights at a Faster Clip
Read more
Frequently Asked Questions
What are federated queries?
Federated queries are SQL operations that access and combine data from multiple heterogeneous sources—data lakes, databases, warehouses, and cloud storage—through a single query interface, without requiring data movement or creating copies. This approach enables organizations to analyze their complete data landscape as if it were unified, while data physically remains distributed across systems. Data federation eliminates the expensive ETL pipelines and data duplication that traditional analytics architectures require, delivering comprehensive business intelligence without operational overhead.
In Dremio's implementation of federated queries, the query engine pushes predicates and projections down to source systems when possible, retrieves only required data, and performs final joins and aggregations efficiently using Apache Arrow's columnar processing. Users write standard SQL without needing to understand which physical systems store which tables—the federation layer handles complexity transparently. The AI Semantic Layer provides consistent business context across all federated sources, ensuring that business intelligence derived from multiple systems reflects accurate, unified interpretations.
This federated querying capability is essential for the Agentic Lakehouse, where AI agents need to access data from across the organization without encountering technical barriers or governance gaps. Fine-grained access controls enforce permissions uniformly across all sources, maintaining security even as queries span multiple systems. By federating data access rather than replicating data, organizations reduce costs, eliminate pipeline maintenance, and ensure AI agents always work with current, governed information—accelerating the path to AI-powered business intelligence without operational burden.
What is a federated database?
A federated database is a data management architecture that provides unified access to multiple autonomous database systems without physically consolidating data into a central repository. Unlike traditional approaches that require copying data into a single warehouse, federated databases enable queries across heterogeneous sources while data remains in its original location. This separation of query processing from storage reduces data management complexity, eliminates data duplication costs, and enables organizations to analyze their complete data landscape without vendor lock-in.
Dremio's approach to database federation goes beyond traditional federated database systems by combining zero-copy architecture with advanced optimizations that deliver warehouse-like performance on federated queries. The query engine understands the capabilities of each source system, intelligently pushing operations down when beneficial and leveraging Autonomous Reflections to accelerate frequently accessed patterns. This data management approach eliminates the performance penalties that plagued earlier federated database implementations, enabling sub-second queries across distributed sources.
The federated database architecture is particularly valuable in the Agentic Lakehouse, where unified access to diverse data sources is essential for AI agents to deliver comprehensive insights. The AI Semantic Layer provides consistent business context across all federated databases, ensuring that queries interpret data correctly regardless of source system. Fine-grained access controls enforce security uniformly, maintaining governance as queries span multiple databases. This modern approach to data management enables organizations to scale analytics without the cost and complexity of consolidating data into expensive, proprietary warehouses—delivering the fastest path to AI-powered insights at the lowest cost.
When should organizations use a federated data lake architecture?
Organizations should use a federated data lake architecture when they need to analyze data across multiple sources while avoiding the cost, complexity, and operational burden of consolidating everything into a single repository. Specific scenarios where data lake federation delivers transformative value include: organizations with data distributed across cloud providers, on-premises systems, and hybrid environments; teams requiring real-time data access without ETL delays; enterprises undergoing cloud migration who need to analyze both legacy and modern systems simultaneously; organizations with regulatory requirements that prevent data consolidation across regions or business units; and companies seeking to avoid vendor lock-in by maintaining data in open formats across multiple platforms.
The federated data lake architecture enables access to real-time data without the delays inherent in ETL pipelines that copy and transform data for centralized warehouses. When business questions require current information—monitoring operational metrics, detecting anomalies, or responding to market changes—federation ensures queries access the most recent data from source systems rather than stale copies. This real-time capability is essential for agentic analytics, where AI agents need current information to deliver accurate, actionable recommendations.
Additionally, federated data lake architectures reduce total cost of ownership by eliminating data duplication, storage redundancy, and pipeline maintenance overhead. Organizations avoid the expensive compute required by warehouses that process redundant data copies, instead leveraging Dremio's Autonomous Reflections to accelerate only frequently accessed patterns. Built on open standards including Apache Iceberg, Polaris, and Arrow, the federated architecture ensures interoperability without vendor lock-in—enabling organizations to scale analytics across their entire data landscape while maintaining the performance and governance required for enterprise AI adoption.
How does federated querying work across multiple data sources?
Federated querying works across multiple data sources through a sophisticated coordination process that unifies data from multiple sources while maintaining performance and governance. When executing queries across distributed sources, Dremio's query engine parses the SQL statement, identifies which data sources contain relevant tables, generates optimized sub-queries for each source, executes those sub-queries in parallel, and combines results while applying joins, filters, and aggregations—all transparently to the user who experiences a unified analytical interface.
The process of unifying data sources involves several intelligent optimizations: The query planner analyzes which operations can be pushed down to source systems, leveraging their native capabilities for filtering and aggregation. The AI Semantic Layer provides business context that helps the optimizer understand relationships between datasets across sources, enabling intelligent join planning that minimizes data movement. Zero-copy architecture ensures that data remains in source systems whenever possible, with only required results transferred for final processing.
For complex queries spanning data from multiple sources, Dremio leverages Apache Arrow's columnar format to efficiently transfer and process data across systems. Autonomous Reflections can accelerate frequently joined datasets even when they originate from different sources, delivering sub-second performance without manual tuning. Fine-grained access controls enforce permissions consistently across all sources, ensuring that federated queries respect security boundaries while providing unified access. This comprehensive approach enables AI agents to explore data conversationally across the entire organization, accessing data from multiple sources through natural language interfaces without encountering technical barriers or governance gaps.
How does query federation impact performance and scalability?
Query federation impacts performance and scalability by enabling organizations to analyze data at any scale without the operational overhead and costs associated with centralizing data into expensive warehouses. While early federated systems suffered performance penalties from network latency and suboptimal query planning, modern implementations like Dremio's Agentic Lakehouse deliver performance that matches or exceeds centralized architectures through intelligent optimization and autonomous acceleration.
Dremio's federated architecture delivers superior performance through several complementary mechanisms: Autonomous Reflections automatically cache frequently accessed data patterns from federated sources, accelerating subsequent queries by orders of magnitude without manual configuration. Predicate pushdown ensures that filtering happens at source systems whenever possible, reducing data transferred across networks. Columnar Cloud Cache (C3) selectively caches data from remote sources, eliminating 90% of I/O costs while maintaining query performance. Cost-based optimization evaluates multiple execution strategies, selecting approaches that minimize latency and resource consumption across distributed sources.
For scalability, federation provides fundamental advantages over centralized approaches. Organizations can add new data sources without impacting existing performance—each source scales independently, and the query engine coordinates access without creating bottlenecks. Workload isolation through Dremio's multi-engine architecture ensures that queries against different sources don't compete for resources, maintaining predictable performance even as analytical demands grow. This scalability is essential for agentic analytics, where AI agents may explore diverse data sources simultaneously. Combined with autonomous optimization that eliminates manual tuning, federated query architecture enables organizations to scale analytics across unlimited sources while delivering 20× performance at the lowest cost—without the operational burden of managing centralized warehouses.
How does database federation support governance and security?
Database federation supports data governance and security by enforcing unified policies across all federated sources, ensuring that access controls, compliance requirements, and audit capabilities apply consistently regardless of where data physically resides. In traditional architectures where data is consolidated into warehouses, governance must be replicated across source systems and the warehouse itself—creating gaps, inconsistencies, and compliance risks. Federated architectures eliminate these gaps by enforcing centralized governance at the query layer, maintaining security even as data remains distributed.
Dremio's approach to governance in federated environments provides multiple layers of protection: Fine-grained access controls enforce permissions at query time, ensuring users only access data they're authorized to see across all sources. Row-level and column-level security policies apply uniformly, whether data originates from data lakes, warehouses, or operational databases. Lineage tracking maintains complete audit trails showing which sources contributed to query results, which transformations were applied, and which policies governed access—essential for compliance in regulated industries. The AI Semantic Layer ensures that business definitions and governance rules apply consistently across federated sources, preventing the data governance gaps that arise when different teams interpret data differently.
For AI agents operating in federated environments, unified governance is particularly critical. AI agents authenticate once and inherit the same access controls as human users—if a user can't access certain data in the Dremio UI, their AI agent won't access it through natural language queries either. This unified approach enables organizations to confidently deploy agentic analytics across their entire data landscape without creating security gaps or compliance vulnerabilities. By maintaining centralized governance while federating data access, organizations accelerate AI adoption while ensuring that every insight, visualization, and recommendation respects organizational policies and regulatory requirements—delivering trustworthy analytics at scale without operational overhead.
Can federated queries run across all environments?
Yes, federated queries can run seamlessly across all environments—cloud, multi-cloud, on-premises, and hybrid architectures—enabling organizations to analyze their complete data landscape without consolidating data into a single location. This capability is essential for modern enterprises that distribute workloads across different platforms to leverage each provider's strengths while avoiding vendor lock-in. Dremio's hybrid lakehouse architecture federates queries across diverse environments with the same performance optimizations and governance controls, ensuring consistent analytics regardless of physical infrastructure.
The ability to federate across all environments provides critical flexibility for organizations at various stages of cloud adoption. Teams can begin analyzing cloud data immediately while maintaining access to on-premises systems—all through a single query interface backed by unified governance. As organizations migrate workloads to the cloud, federated queries enable gradual transitions without disrupting analytics workflows or requiring expensive data replication. Multi-cloud strategies become operationally feasible, as teams can leverage best-of-breed services from different providers while maintaining unified analytics across all platforms.
Built on open standards including Apache Iceberg, Polaris, and Arrow, Dremio's federated architecture works consistently across any infrastructure that supports these formats. The zero-copy approach means you never duplicate data to enable cross-environment analytics—reducing storage costs, eliminating ETL pipelines, and maintaining a single source of truth regardless of physical location. For AI agents, this environmental flexibility is transformative: agents can explore data conversationally across the entire organization without needing to understand infrastructure topology or navigate different access patterns for different environments. This seamless federation accelerates the path to AI-powered insights while maintaining the performance and governance required for enterprise analytics—delivering 20× performance at the lowest cost without operational burden or vendor lock-in.

