Eliminate Expensive Data Copies with a SQL Lakehouse Platform
Over the past few decades most of us have synonymized BI and data analytics with data warehouses. Oh, how mistaken we’ve been — especially in today’s world!
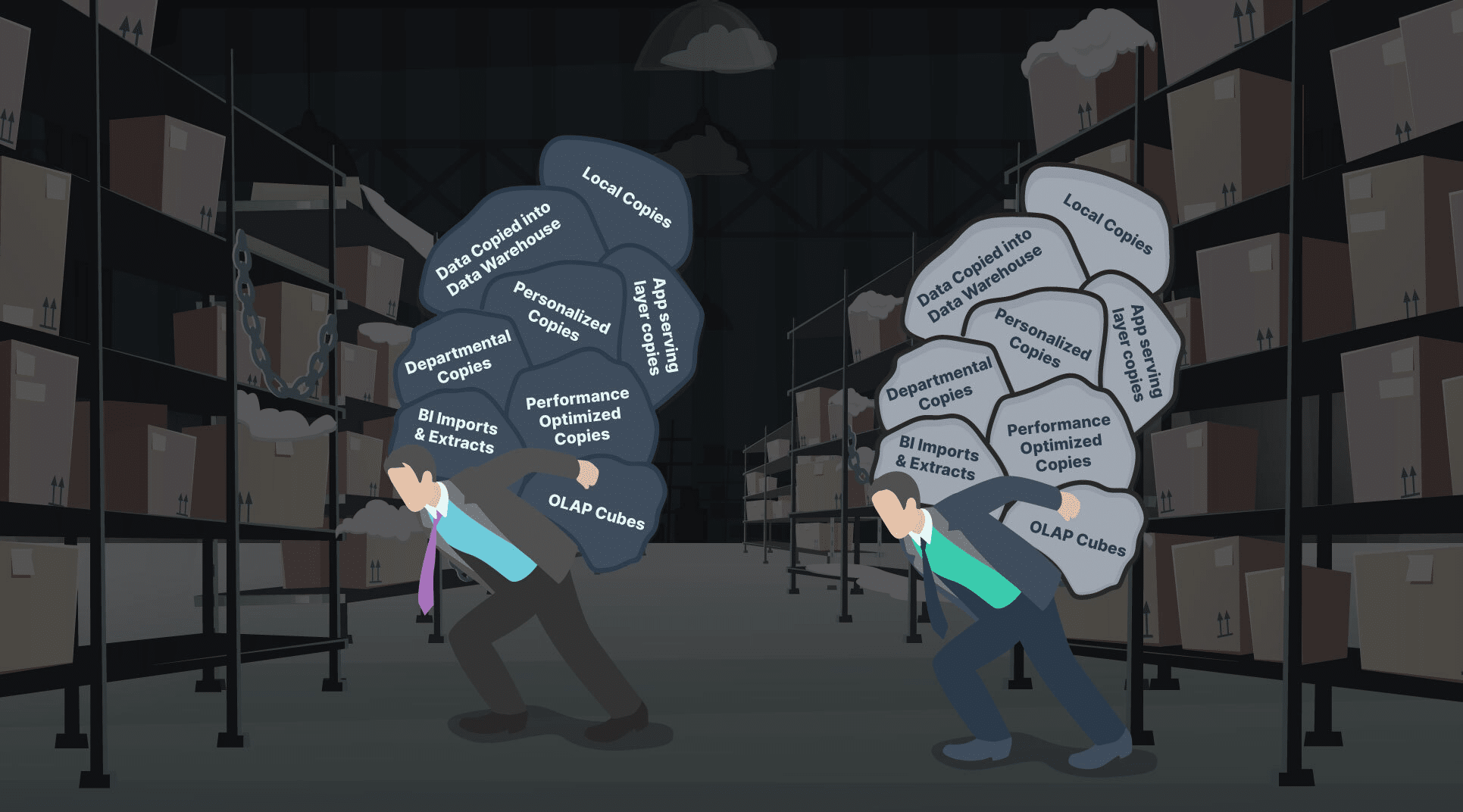
All these years, the sheer design and inherent architecture of data warehouses (traditional and cloud) and data warehousing processes such as ETL/ELT have inevitably forced you, your data teams and business users to think that the only way to get super-fast queries and dashboards was to create multiple “performance-optimized” data copies. Well, not now! This is no longer true!
When data analytics and reporting on historical company data became a “thing” in the 80s, I understood and respected the role that data warehouses played — a sole central repository of data collected from multiple transactional systems. Back then, we didn’t mind moving and copying a whole new replica of data into the data warehouse, or creating more data copies via cubes and abstracts to massage data for optimized reporting and dashboards, or creating even more copies for personalization, or making local copies of data, etc.
But look where we are now! We experienced the internet era of the 2000s, the “cloud revolution” over the past decade, and the most recent “new normal” in the past year of almost everything — applications, users, experiences and apps — going digital, online and cloud! Organizations are modernizing to the cloud, and modern-day applications and user behavior, psychology and expectations are creating humongous amounts of data that none of us could have ever imagined! We are living in a world of Peta-, Exa-, Zetta- and Yottabytes! An IDC study estimated that as much as 60% of all data storage is dedicated to managing copies of data at an estimated cost of $55 billion annually.
We have either ignored, not realized or helplessly watched this huge burden of costs to our organizations evolve, as a result of our dependency on proprietary data warehouse vendors, as well as the unimaginable cost of redundant data copies throughout our data architectures due to the sheer design of data warehouses and ETL/ELT processes!
It’s time to shake ourselves from the shackles of age-old technologies that were once a boon, and are now a constant financial burden for our companies, and the primary cause of significant damage to our organizations’ bottom line due to the irreparable footprint of multiple data copies that constantly hinder our ability to be open to new technologies of the future. It is just wise to choose open!
If there’s one thing to take away from this blog it is to just pause for a moment and reflect on the footprint of our decisions and architectures. Don’t you think it is high time to invest in solutions that enable lightning-speed queries and dashboards, increase productivity and significantly reduce time to insight through self-service data access to all users and have all this directly on the data lake storage without any additional data copies? — No footprint! No additional costs!
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.