Dremio vs Redshift: Which is better for modern agentic AI and analytics?
Avoid the limitations of Redshift with Dremio’s Agentic Lakehouse
Deliver agentic analytics faster with an open Iceberg lakehouse that’s simple to manage, lightning-fast at scale and dramatically lower cost than Redshift.

TRUSTED BY:
Overcome Redshift limitations with Dremio
Feature
Dremio Cloud
Amazon Redshift
AI Readiness
Integrated AI Agent; cross-source AI Semantic Layer; MCP server connects any external AI agent to all federated data
No integrated AI agent; no unified semantic context across sources; data must be loaded into Redshift for AI access
Governance & Security
RBAC, row-level filtering and column masking at the catalog layer; consistent governance across all federated sources
Governance limited to data within Redshift; no fine-grained access across external data lakes and sources
Performance
Autonomous Reflections auto-create, auto-refresh and auto-retire query accelerators; Apache Arrow-native engine delivers sub-second queries without tuning
Requires manual tuning, sort keys and distribution keys; degrades under high concurrency
Cost Model
Elastic Engines scale dynamically; queries data in place, eliminating ETL pipelines and data duplication costs
Always-on clusters drive costs even when idle; ETL pipelines add storage and compute overhead
Open Standards
Built on Apache Iceberg, Arrow and Parquet for full data portability and multi-engine interoperability
Proprietary storage format; data ingested into Redshift creates vendor lock-in
Migration Complexity
Low: direct connectivity to Redshift tables and views; automated SQL translation via built-in AI Agent
High: requires ETL pipelines and schema re-engineering to move data in or out
Redshift vs Dremio: why choose Dremio's advanced lakehouse platform
Dremio is one of the best Redshift alternatives, delivering an AI Semantic Layer, Autonomous Reflections and an Open Catalog built on Apache Polaris. Customers report 50-70% lower TCO when using Dremio vs Redshift, driven by reduced infrastructure costs, fewer manual operations and the ability to consolidate analytics, AI and data engineering workloads into one platform.


Query Performance
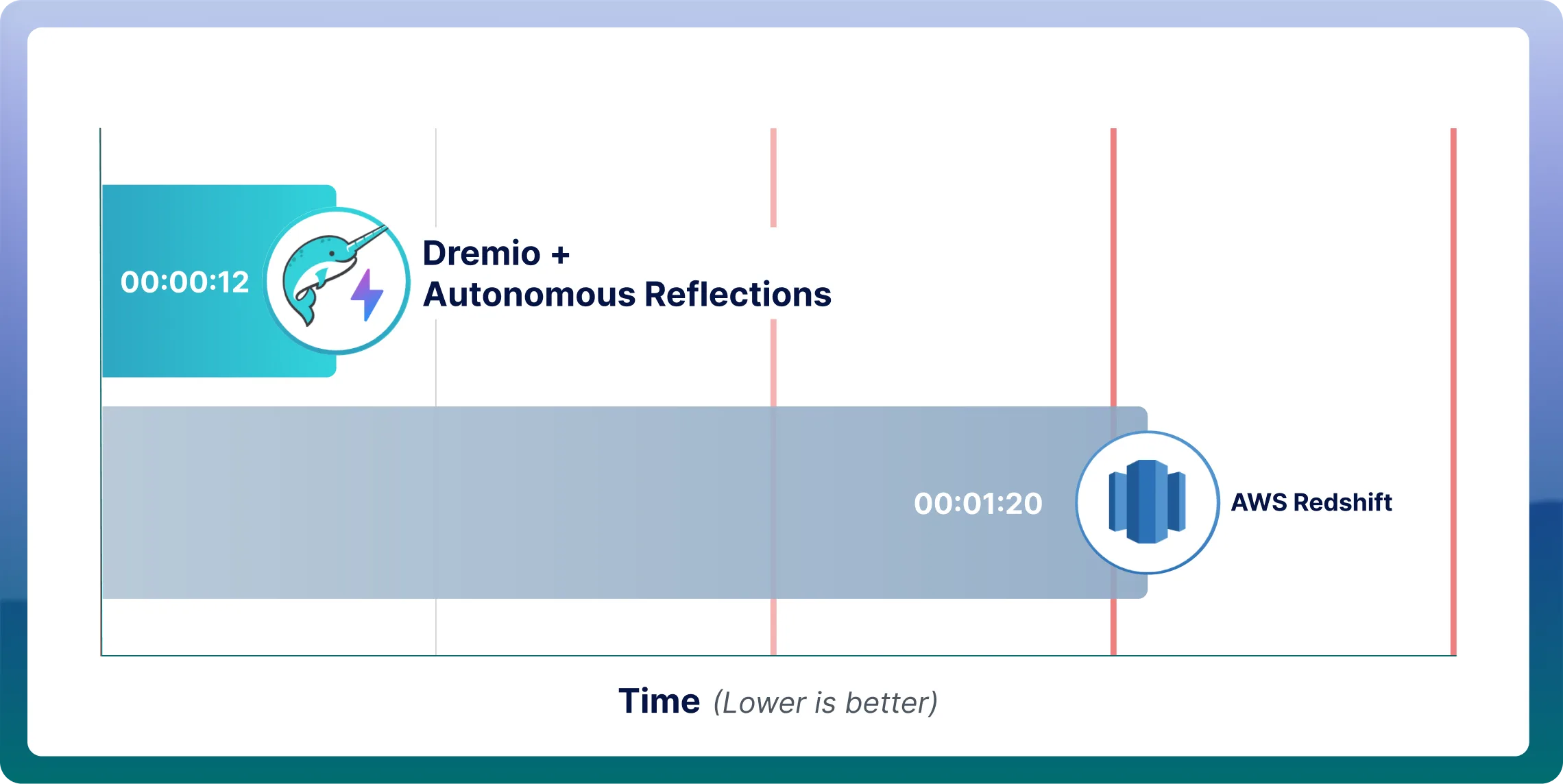
What makes Dremio the best alternative to Redshift?
When evaluating Dremio vs Redshift, three capabilities set Dremio apart: autonomous optimization that removes the tuning burden Redshift places on engineering teams, zero-ETL federation that eliminates the need to move data into a proprietary warehouse, and a unified semantic layer that makes all of your data AI-ready.
Autonomous optimization
Dremio removes the performance engineering burden that comes with Redshift, with no distribution keys, no sort keys and no manual tuning cycles. Autonomous Reflections learn from real query patterns over a rolling 7-day window and automatically create, refresh and retire materialized accelerators. Elastic Engines scale to zero when idle, eliminating always-on cluster costs. Customers consistently report 50-70% lower TCO compared to Redshift.
Auto-created from observed query patterns, no distribution key or sort key engineering required.
Auto-refreshed when underlying data changes via Intelligent Incremental Refresh.
Auto-retired when query patterns shift: scored 0-100, disabled for 7 days, then dropped.
Apache Arrow-native engine with LLVM code generation maximizes CPU efficiency and throughput.
Native Iceberg Clustering (Z-order) at GA, Redshift has no open-format clustering equivalent.

Zero-ETL federation
Redshift requires data to be loaded into its proprietary storage before it can be queried or governed. Dremio is built around the opposite philosophy: query data where it lives, in open formats, without duplication. This eliminates the ETL pipelines, storage overhead and lock-in that come with centralizing data into a legacy warehouse.
Query data in place across ~31 native source types: lakehouses, relational databases, cloud warehouses, object storage.
No ingestion into proprietary storage; data stays in Apache Iceberg, Parquet and Arrow.
Open Catalog built on Apache Polaris (ASF top-level project). Any Iceberg REST engine reads and writes, with no lock-in.
Zero-ETL architecture eliminates pipeline maintenance, storage duplication and data movement costs.

Unified semantic layer
Redshift has no semantic layer: no unified business definitions, no governed metric context for AI agents and no cross-source data access model. Dremio’s cross-source AI Semantic Layer provides consistent business and technical context to analysts and AI agents alike, across every connected source.
SQL views spanning any connected source: Iceberg catalogs, relational databases, cloud warehouses, object storage.
MCP Server connects any MCP-compatible agent (Claude, ChatGPT, Cursor) to all federated data with governance enforced.
RBAC, row-level filtering and column masking at the catalog layer for consistent governance across every source.
AI functions in SQL (AI_CLASSIFY, AI_GENERATE, AI_COMPLETE) for enrichment and generation without separate pipelines.

FAQs
Frequently Asked Questions
01
Why would a company look for an Amazon Redshift alternative?
Many companies start out using the Redshift database because it handles structured data and traditional BI workloads reasonably well within AWS. But as data volumes grow, the variety of data types increases and demand shifts toward real-time analytics, agentic AI and more dynamic workloads, Redshift’s legacy warehouse architecture shows its limits.
The need to maintain complex ETL pipelines, data duplication and cluster provisioning — plus the overhead of manual tuning, distribution keys and complex table management — creates friction for agile teams. Enterprises increasingly value flexibility, openness and cost control: architectures that avoid vendor lock-in, reduce management complexity and allow querying data directly where it lives.
That said, Redshift can still be a reasonable fit for organizations with simple, structured BI workloads running entirely within the AWS ecosystem. The challenges tend to emerge as data complexity grows, concurrency demands increase and teams begin exploring AI and real-time analytics use cases.
02
What makes Dremio one of the best Amazon Redshift alternatives?
Dremio is the best alternative to Redshift because it delivers a truly modern lakehouse architecture that eliminates many of the limitations inherent in Redshift’s legacy warehouse approach. Instead of requiring data ingestion into a proprietary system, Dremio lets organizations query directly in open formats on object storage — eliminating costly ETL pipelines, data duplication and heavy maintenance.
Autonomous Reflections accelerate complex queries automatically, providing fast analytics without ongoing tuning, indexing or caching configuration. The built-in AI Semantic Layer gives both users and AI agents governed, business-aware access to data without needing extra copies, separate modeling tools or manual metadata work. Open-source foundations leveraging Apache Iceberg, Arrow and Apache Polaris ensure data portability, future-proof flexibility and no vendor lock-in.
03
What are some common limitations of Redshift that make Dremio a better solution?
Redshift performance often deteriorates as datasets grow and concurrency increases, causing slow queries and bottlenecks when many users or workloads run simultaneously. To maintain acceptable performance, teams must rely on distribution keys, sort keys, caching and complex ETL pipelines to move data into Redshift. This heavy operational effort is compounded by Redshift’s always-on compute model, which drives up costs even when workloads are idle.
Dremio removes these limitations with Autonomous Reflections (no tuning or data duplication required) and massively parallel, cloud-native execution that supports high concurrency across thousands of users and AI agents. Unlike Redshift, Dremio provides a built-in AI Semantic Layer and Open Catalog built on Apache Polaris — delivering business context and centralized data governance essential for enterprise-grade agentic AI.
04
How does Dremio’s solution compare to the cost of Redshift?
Dremio significantly lowers the total cost of ownership compared to Redshift by eliminating many of the hidden and ongoing expenses that come with traditional data warehouses. Because Dremio queries data in place on open storage in the data lakehouse rather than requiring ingestion into proprietary storage, it removes the need for costly ETL pipelines, reduces storage duplication and avoids paying for always-on compute clusters when idle.
Users consistently report 50–70% lower TCO when using Dremio vs Redshift, driven by reduced infrastructure costs, fewer manual operations and the ability to consolidate analytics, AI and data engineering workloads into one platform. See the Dremio pricing page and TCO resources for methodology and detail.
05
How does Dremio support AI and LLM workloads?
As an agentic lakehouse platform, Dremio accelerates AI and LLM workloads by combining an Open Catalog with an AI Semantic Layer that provides governance, metadata and business context for both users and AI agents. Instead of copying data into a proprietary system, queries are made in place on object storage, allowing models and agents to train, retrieve and reason over the same governed datasets used for analytics.
Dremio also includes AI functions for classification, extraction, enrichment and generation, enabling the transformation of unstructured data into agentic AI insights directly within the platform.
Beyond acting as an AI-ready, big-data processing foundation, our platform provides its own integrated AI agent and connects to external agents through the MCP (Model Context Protocol), empowering multi-agent collaboration across the lakehouse. Using Dremio’s semantic layer, these agents gain:
- Governed access
- Business understanding
- Query generation capabilities
- Automatic metadata creation
Combined with autonomous performance, high concurrency and an open Iceberg catalog that avoids lock-in, Dremio delivers a lakehouse platform purpose-built for enterprise-grade agentic AI and LLM workloads.
06
How difficult is it to migrate data from Redshift to Dremio?
Migrating from Redshift to Dremio is a fairly straightforward process, especially when an organization has an existing data lake environment. Data can be unloaded from Redshift into open formats like Parquet in Amazon S3 and then registered or loaded directly into Iceberg tables in Dremio using CTAS and COPY INTO commands.
Dremio provides direct connectivity to Redshift, allowing tables, views and schemas to be converted without relying on heavy ETL pipelines. SQL differences can be automated using Dremio’s built-in AI Agent or other AI agents for fast translation. Because Dremio maps Redshift databases and hierarchies cleanly into its catalog and supports auto-ingestion pipelines for ongoing data sync, organizations can move incrementally with minimal disruption. Most organizations complete their initial migration in days.
Make data engineers and analysts 10x more productive
Boost efficiency with AI-powered agents, faster coding for engineers, instant insights for analysts.