Traditional data management techniques increasingly struggle to keep pace with modern data volume, variety, and velocity. The need to evolve legacy data management to enable AI-ready data has caused organizations to evaluate their data strategies. Two innovative approaches have gained prominence: Data Mesh and Data Fabric. While distinct in their philosophies, they are not mutually exclusive. Both offer valuable strategies for managing and leveraging enterprise data assets.
Data Mesh
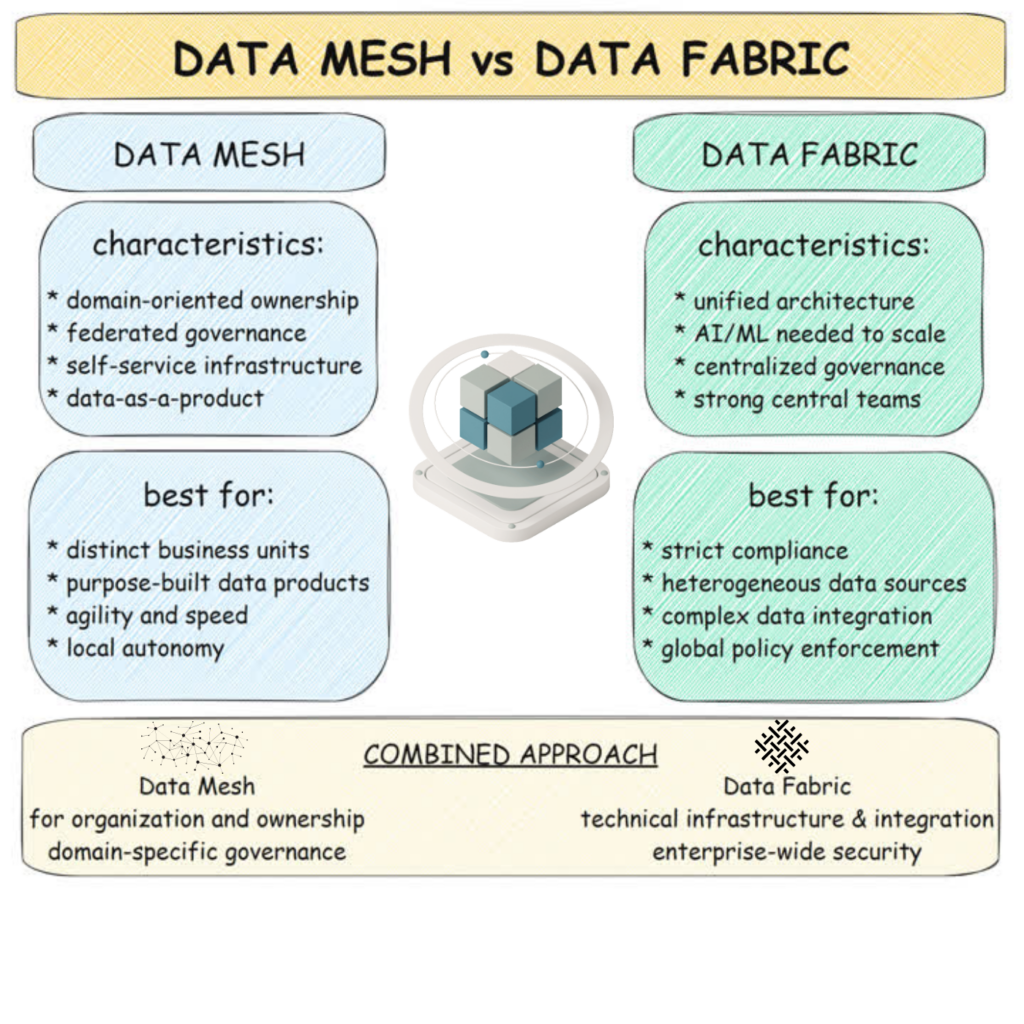
Data Mesh, introduced by Zhamak Dehghani in 2019, represents a fundamental shift in how organizations think about and manage their data. Rather than treating data as a byproduct or a centralized asset, Data Mesh views data as a product that should be owned and managed by domain experts. This approach operates under the assumption that those closest to the business context are best positioned to manage and deliver value from their data.
Data Mesh has four core pillars to create a scalable and efficient data architecture:
The first principle, domain-oriented decentralized data ownership and architecture, shifts data ownership from central IT teams to domain teams who understand the business context. This principle recognizes that data is most valuable when managed by those who understand its business context and use. Domain teams - whether in Sales, Marketing, Finance, or other business areas - take full responsibility for their data products, including decisions about storage, processing, and access patterns.
The second principle, data as a product, transforms how organizations approach data management by applying product thinking to data assets. Under this principle, each dataset is treated as a valuable product with its own lifecycle, roadmap, and metrics for success. Data product owners must consider their users' needs, ensuring their data products are discoverable, addressable, trustworthy, self-describing, and interoperable.
The third principle, self-serve data infrastructure as a platform, provides domain teams with the technical capabilities to manage their data products independently. This infrastructure must be universally available and standardized across the organization, offering data storage, processing, security, and monitoring capabilities.
The fourth principle, federated computational governance, balances autonomy and consistency. This principle recognizes that domain teams must operate within a framework that ensures interoperability, security, and compliance while they need the freedom to manage their data products. Federated governance provides global standards and policies while allowing for domain-specific implementation.
Dremio supports these Data Mesh principles through its semantic layer capabilities, which enable domain teams to create and manage their data products effectively. The platform provides:
Dremio Capability
Data Mesh Support
Semantic Layer
Enables domain-specific data modeling
Self-Service Analytics
Supports direct data access and exploration
Governance Framework
Facilitates federated access controls
Data Documentation
Enables product documentation and discovery
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Data Fabric
Data Fabric represents a different approach to solving modern data challenges. Rather than focusing on organizational change, Data Fabric creates an intelligent, automated layer that simplifies data access and management across distributed sources. This approach leverages artificial intelligence and automation to reduce the complexity of data integration and management.
The technical capabilities of Data Fabric have strong benefits:
Data Fabric Feature
Technical Implementation
Business Value
Automated Integration
AI-driven data discovery and pipeline creation
Reduced manual effort, faster insights
Active Metadata
Real-time collection and analysis
Improved data understanding and optimization
Unified Access
Consistent APIs across sources
Simplified data access, enhanced security
Smart Operations
ML-powered optimization
Reduced costs, improved performance
At its core, Data Fabric employs automated data integration to streamline the movement and synchronization of data across the enterprise. AI-driven systems discover and map data relationships, create and optimize data pipelines, and handle real-time synchronization needs. This automation extends to error handling and recovery, continuously optimizing based on actual usage patterns to improve efficiency over time.
Comparing Approaches
The most fundamental distinction between Data Mesh and Data Fabric is their primary focus. Data Fabric is a technological solution that emphasizes automated data integration and management through intelligent tools and platforms. It seeks to solve data challenges through technical means, using AI and automation to create a unified data access layer that simplifies data management across the enterprise.
Data Mesh is a people-oriented approach that focuses on organizational structure and human interactions with data. It recognizes that technical solutions alone cannot solve the complex challenges of enterprise data management. Instead, it emphasizes the need to reorganize how people work with and manage data, placing responsibility on the domain experts who understand the business context best.
This core difference in focus - technology versus people - influences every aspect of how these approaches are implemented and managed. Understanding these fundamental differences is crucial for making informed architectural decisions:
Aspect
Data Mesh
Data Fabric
Primary Focus
People-oriented: organizational and cultural change
Technology-oriented: integration and automation
Management Approach
Human-centric data product management
Technology-driven data management
Decision Making
Domain experts drive data decisions
AI/ML systems optimize data processes
Data Ownership
Domain teams
Centralized with distributed access
Governance Model
Federated
Centralized
Implementation Complexity
High (organizational change)
Medium (technical integration)
Time to Value
Longer (cultural shift needed)
Medium (technical implementation)
Resource Requirements
Domain expertise + technical
Primarily technical
Data Mesh and Data Fabric: Better Together
While often presented as competing approaches, Data Mesh and Data Fabric can work together by combining their strengths in people management and technology automation. Data Fabric's automated technical capabilities can powerfully enhance Data Mesh's focus on human organization and data product thinking. This combination allows organizations to address the human and technical aspects of data management simultaneously. Data Mesh provides the organizational framework and principles for managing data as a product. At the same time, Data Fabric delivers the technical infrastructure and automation capabilities needed to make this vision a reality.
The complementary nature of these approaches can yield several benefits:
The choice between Data Mesh and Data Fabric - or a combined approach - should be guided by your organization's specific needs, capabilities, and goals. Success requires careful planning, strong leadership support, and a commitment to continuous improvement. Tools like Dremio can significantly accelerate implementation and enhance the value derived from either approach. Start small, iterate, and scale based on proven success. Maintain focus on business value while building a flexible, scalable data architecture that can adapt to your organization’s changing needs.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Sep 22, 2023·Dremio Blog: Open Data Insights
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.