Breakthrough Performance: Dremio Sets New Standard—20x Faster Than Any Other Lakehouse
In recent days, we’ve seen growing industry attention on query performance—most recently with Databricks announcing a 25% improvement. At Dremio, we’ve taken a fundamentally different approach—one that delivers a step-function leap in speed and efficiency. Today, we’re excited to share a breakthrough that reflects years of deep engineering investment and innovation.
In a full run of the industry-standard 1TB TPC-DS benchmark, Dremio executed all 99 queries in just 22 seconds using an m7gd.4xlarge 8-node cluster. No tuning. No pipelines. No specialized configuration.
This isn’t a 25% gain. It’s 20x faster.
Strategies for Optimizing Query Performance
Data platforms enhance query performance through three key strategies:
Query Planning Optimization: The query planner uses data statistics and historical query patterns to generate efficient execution plans.
Query Execution Optimization: Techniques such as columnar execution, caching, and resource-efficient processing ensure fast and lightweight query execution.
Data Optimization: Organizing data to minimize scan requirements significantly boosts performance.
These strategies are interconnected. For instance, Dremio’s query planner integrates with its distributed cache (Columnar Cloud Cache, or C3), leveraging cached data locality to inform scheduling decisions.
Note: Caching wasn’t used in the Benchmark results above
Historically, data platforms prioritized query planning and execution optimization. Dremio has led the industry in these areas, employing adaptive cost-based optimization, columnar execution via Apache Arrow, and comprehensive caching. However, data optimization has proven more complex and less transparent to users. Traditional methods like materialized views require data teams to analyze workloads, create and maintain materialized views, and modify applications to use them. These approaches are fragile, costly, and impractical for most organizations.
Breakthrough in Data Optimization
Three years ago, Dremio recognized that achieving order-of-magnitude performance improvements hinged on revolutionizing data optimization, rather than further refining query planning or execution. Traditional data optimization methods, such as materialized views and manual indexing, impose significant burdens on data teams. Analyzing query workloads to identify optimization opportunities is time-intensive and error-prone. Creating and maintaining materialized views requires continuous effort as data and query patterns evolve. Rewriting applications and dashboards to leverage these structures adds complexity and cost. These methods are brittle, fail to scale with growing data volumes or diverse workloads, and are often impractical for most organizations.
To address these challenges, we invested extensively in a fundamentally different technology over the past three years. The system automatically analyzes query patterns, identifying access trends without manual intervention. It dynamically generates optimized data structures, such as tailored indexes, joins and aggregates, and applies them transparently during query execution. This approach eliminates the need for manual workload analysis, materialization maintenance, or application rewrites, delivering scalable, high performance across diverse datasets and use cases. Not only is this created automatically, but maintained transparently in an efficient manner focusing on only updating what matters.
Additionally, we tackled the separate issue of traditional partitioning. Partitioning struggles with skewed data and high-speed ingestion, leading to inefficient scans and maintenance overhead. By eliminating reliance on partitioning, Dremio ensures robust performance in dynamic, modern data environments.
Autonomous Reflections: 20x Faster Execution, No Manual Tuning
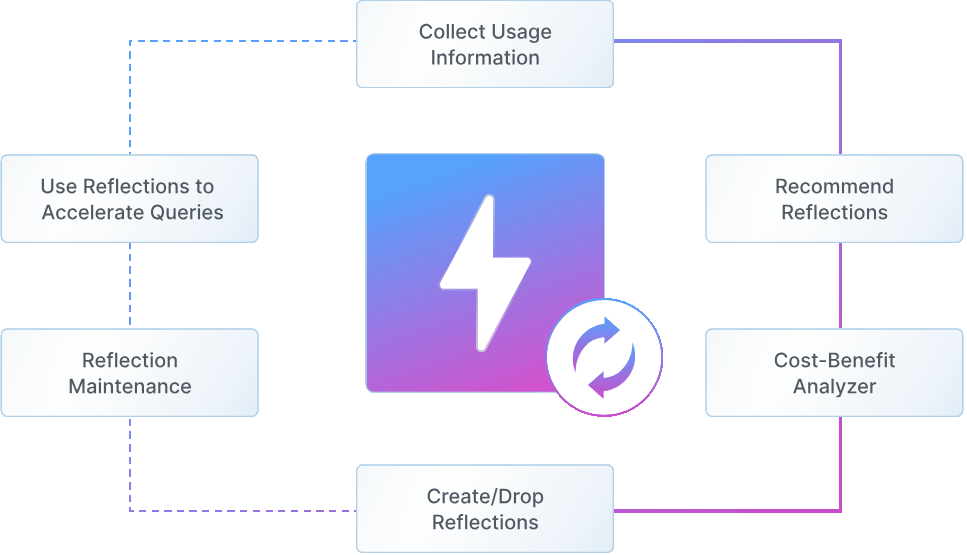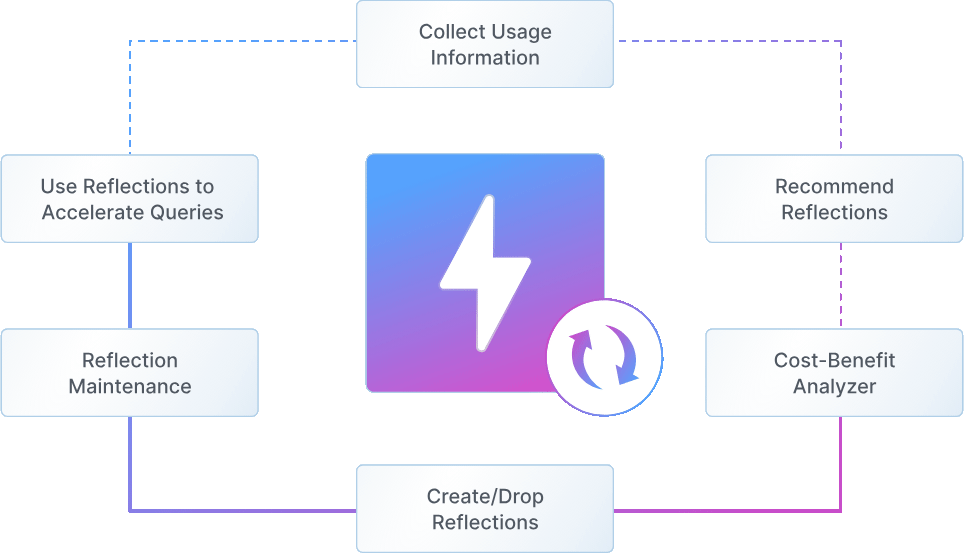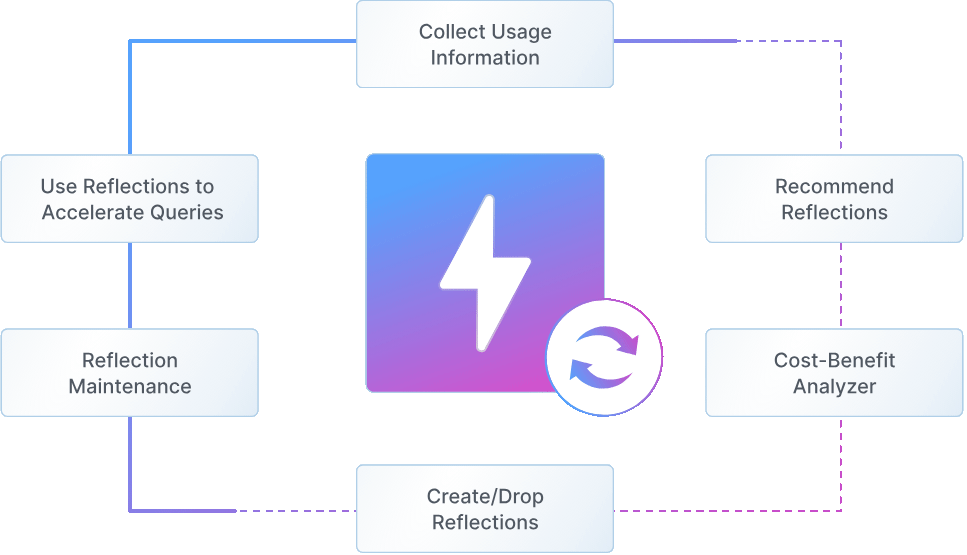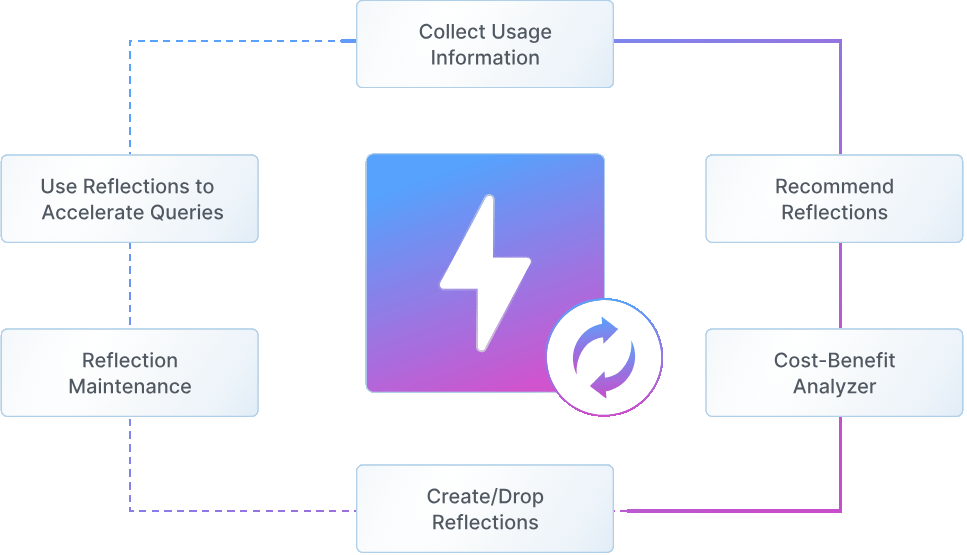
At the core of this performance leap is Autonomous Reflections, a technology we designed to completely reimagine how queries can be accelerated. With Autonomous Reflections, the system continuously analyzes query patterns, automatically creates and manages data structures, and rewrites query plans for optimal performance—all without any user intervention or query changes.
How It Works
Query-Aware Intelligence Dremio continuously monitors running workloads to detect expensive patterns and subqueries (joins, filters, aggregations, etc.)—pinpointing opportunities for acceleration.
Autonomous Management
An intelligent engine continuously analyzes Iceberg table metadata—such as column-level stats, file sizes, and snapshot lineage—alongside query patterns to evaluate and score optimization opportunities. Instead of creating static materialized views, Dremio generates lightweight, query-aware data structures that take advantage and leverage Iceberg metadata for intelligent execution. These structures are automatically maintained and incrementally updated, ensuring they stay in sync with source data and adapt to evolving workloads.
Transparent Query Rewriting When queries are received from a client application (e.g., AI agent, application, dashboard), Dremio’s planner automatically rewrites them to take advantage of the autonomously created data structures, without requiring any client-side changes to the original SQL or endpoint.
Hands-Free Maintenance Reflections stay synchronized with source data, refresh incrementally, and are automatically compacted and maintained—no pipelines, no jobs, no back and forth with teams.
Full Lifecycle Management As query patterns change, lower value reflections are recycled and the system maintains an ROI based approach to ensure compute is never wasted against the benefits it can provide – net net, the “hidden” cost of keeping reflections up to date is amortized across the queries ensuring that there is never wasted compute.
The result? Sub-second response times on queries that used to take 10–15 seconds with no manual effort. In our internal lakehouse, 80% of dashboards were accelerated automatically, and 90th percentile query time dropped from 13 seconds to under 1 second—with zero manual effort.
This approach is what makes AI agent workflows possible - gone are the days of going back and forth with a central data team and well, when was the last time you saw an AI Agent do that? You can simply have agents run queries and Dremio automatically ensures they are accelerated on an ROI basis.
While Autonomous Reflections may initially be thought of as a take on materialized views, they are fundamentally different in design, operation, management and outcomes.
Traditional materialized views require manual effort: analyzing workloads, manually defining the tables and the views, adjusting ETL pipelines, scheduling refresh jobs, and modifying queries to use the new materialized views. They’re often fragile and hard to scale - they can also lead to data inconsistency.
Autonomous Reflections are different. They’re built dynamically based on query activity, maintained incrementally with no jobs to manage, and applied transparently without changing a single line of SQL. In addition, they guarantee data accuracy so that you as a practitioner never have to worry about getting inaccurate results.
Query performance at scale often comes down to table layout. But designing partitions and physical structures manually is time-consuming and brittle. Over time, as data changes, these optimizations degrade—requiring constant upkeep.
With Dremio, partitioning is no longer needed. Instead, Dremio now provides the industry’s only Iceberg clustering technology. And it is fully automatic. Our engine continuously organizes Iceberg tables using Z-order-based clustering, adapting to new data and evolving usage patterns in real time.
Key Innovations
Partition-Free by Design You don’t need to define partitions or worry about data skew (unbalanced partitions), small files, or slow ingestion. Clustering works out-of-the-box.
Iceberg Native, Open by Default Optimizations occur directly on Iceberg tables, preserving table history and ensuring compatibility with other engines. In fact, users can write to the table using any Iceberg compatible engine or tool, while Dremio continues to cluster behind the scenes.
Incremental Optimization Clustering happens incrementally as new data arrives. There’s no need for full table rewrites or downtime.
Z-Ordering for Multidimensional Queries Z-ordering improves pruning for queries with multiple filters. The table is clustered on multiple columns, ensuring that nearby values are concentrated in the same files.
The outcome is faster scans and reduced I/O—without manual effort or orchestration. Dremio handles the complexity so your teams can stay focused on insights, not infrastructure.
Arrow-Based Columnar Execution: Built for Modern Analytics
Dremio’s execution engine is built natively on Apache Arrow, the open, columnar in-memory format we co-created and that now sees over 100 million downloads per month.
This gives us foundational advantages in raw processing speed and system efficiency, as well as an advantage in client connectivity performance.
Columnar Vectorized Execution Arrow enables batch processing that takes full advantage of modern CPUs.
Arrow Flight Transport A high-performance protocol that eliminates traditional data transfer bottlenecks.
Zero-Copy Efficiency Arrow allows data to flow through the engine with minimal serialization or overhead.
Open by Nature Arrow is an open standard—ensuring Dremio integrates seamlessly into your broader data ecosystem.
The result is a highly efficient, high-throughput engine designed for modern workloads and AI-ready data architectures.
End-to-End Caching: Real-World Speed, Even Beyond Benchmarks
Dremio’s layered caching system accelerates performance even further in production environments—though none of these caches were used in our benchmark to ensure full transparency.
Caching Layers
Columnar Cloud Cache (C3) Hot data blocks are automatically cached locally on NVMe, giving object storage the speed of local disk—without data copying.
Result Cache Repeated queries on the same data return instantly, avoiding re-execution.
Query Plan Cache Structural query similarities are detected and planned instantly, reducing latency before execution begins.
These caching layers compound performance benefits in real-world workloads. But even without them, as shown in the 22-second TPC-DS benchmark, Dremio’s core engine delivers industry-leading speed.
From Benchmarks to Real Workloads
Benchmarks are a good reference point—but the real value comes when you see this performance on your own data.
Dremio’s 22-second TPC-DS result illustrates what’s possible with Autonomous Performance and a modern lakehouse engine. But more importantly, this performance is repeatable across real workloads, with no tuning or refactoring required.
Whether you’re powering AI agents or simply accelerating traditional dashboards, Dremio delivers sub-second query speeds—consistently and automatically.
Ready to experience it? Get started now or explore these guides:
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.
Dec 7, 2023·Dremio Blog: News Highlights
Dremio Cloud on Azure Available Now
Unveiling Dremio Cloud on Azure, a Fast, Scalable and Secure Lakehouse Platform Introduction Today we introduce Dremio Cloud on Azure, newly landing on Azure in November 2023, in public preview. Dremio Cloud is a powerful lakehouse platform providing streamlined self-service, unparalleled SQL performance, centralized data governance and seamless lakehouse management. In this blog post, we […]