Dremio's Open Catalog offers a free, interoperable data solution using open standards like the Iceberg REST Catalog specification.
You can adopt a 'bring your own' architecture for compute, storage, and AI, avoiding vendor lock-in and additional costs from Dremio.
The Open Catalog supports connections to other compatible engines and storage solutions, enhancing flexibility in data management.
Dremio ensures robust governance and multi-tenancy through a structured organizational model, allowing data isolation and tailored security policies.
Dremio's approach prioritizes user choice and cost control, transforming the data catalog into a less restrictive and more versatile asset.
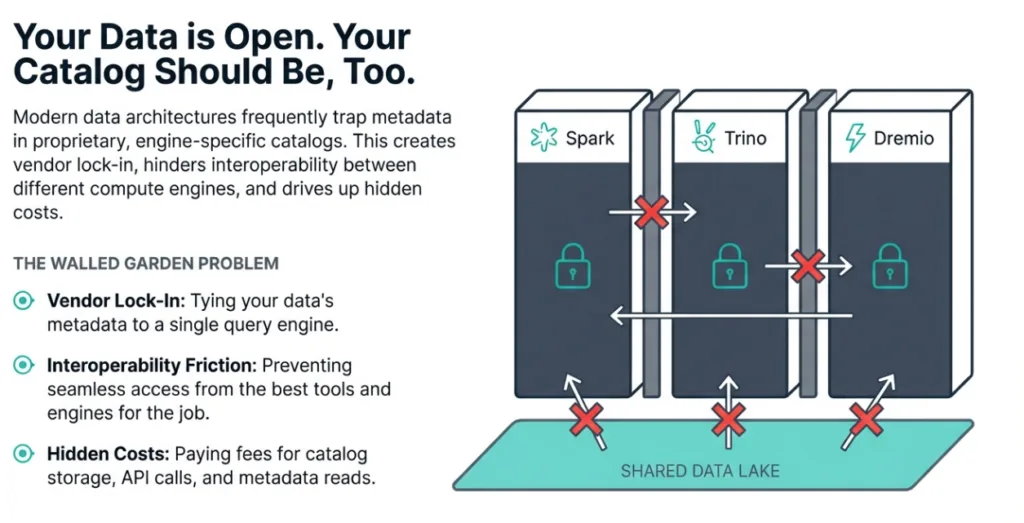
For data professionals building a modern lakehouse, the data catalog often becomes a point of contention. Proprietary catalogs can create vendor lock-in, introduce unnecessary complexity, and carry hidden costs that aren't apparent until you're deeply invested. They promise integration but often deliver a walled garden, limiting your choice of tools and inflating your bills.
Dremio's Open Catalog (Powered by Apache Polaris, an incubating Apache Project) presents a powerful and surprisingly different alternative. It’s designed to put you back in control of your data architecture. This post will explore three impactful truths about Dremio's catalog that challenge the status quo: interoperability, a "bring your own everything" philosophy, and a uniquely transparent pricing model.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
Takeaway 1: Your Lakehouse Catalog is Now Open, Interoperable, and Free
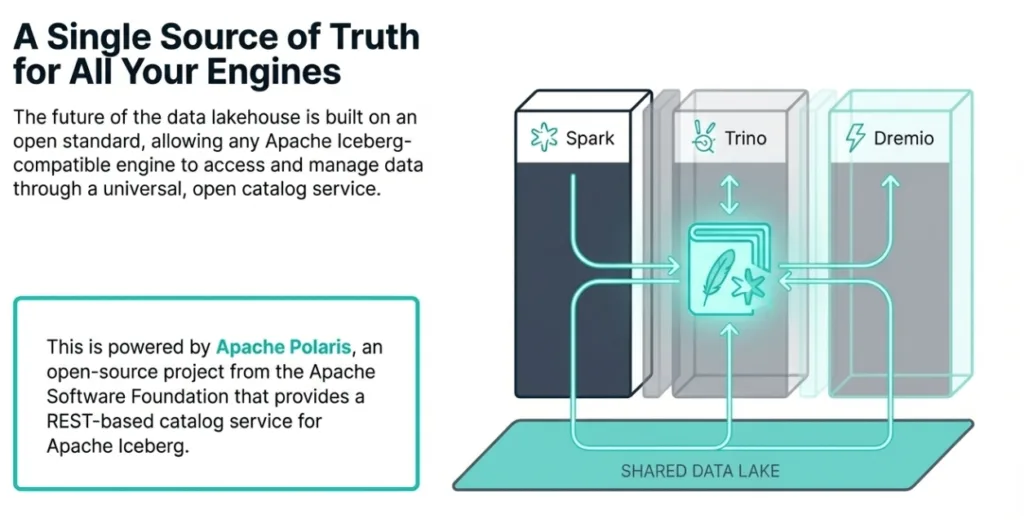
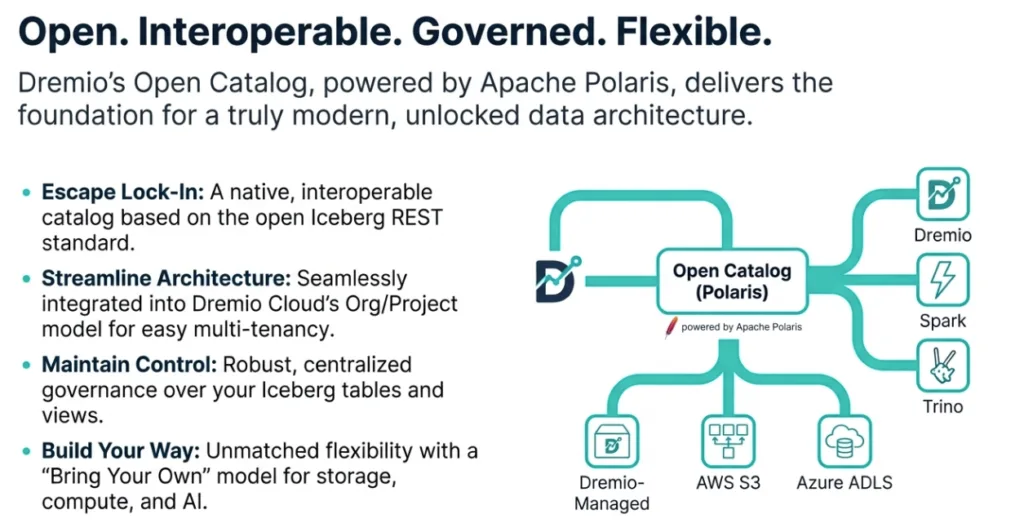
Every Dremio Cloud project includes a native Open Catalog powered by the open-source Apache Polaris project. This isn't just a branding choice; it's a commitment to open standards.
The catalog fully supports the Iceberg REST Catalog specification, which means it’s not exclusive to Dremio. Other query engines that support this open standard, such as Apache Spark, Trino, and Flink, can directly connect to the Dremio catalog to query and manage your Iceberg tables. This is made possible through a stable, public endpoint (https://catalog.dremio.cloud/api/iceberg) that adheres to the open REST protocol, ensuring any compatible client can connect. This fundamental interoperability frees your data from engine-specific silos.
The most significant differentiator is the pricing model. Dremio does not charge for the Open Catalog itself, nor for API calls made to it from external tools. Dremio's charges are based on consumption of its own services:
Dremio compute resources (DCUs)
Optional Dremio-managed project storage
Optional use of the Dremio-hosted Large Language Model (LLM)
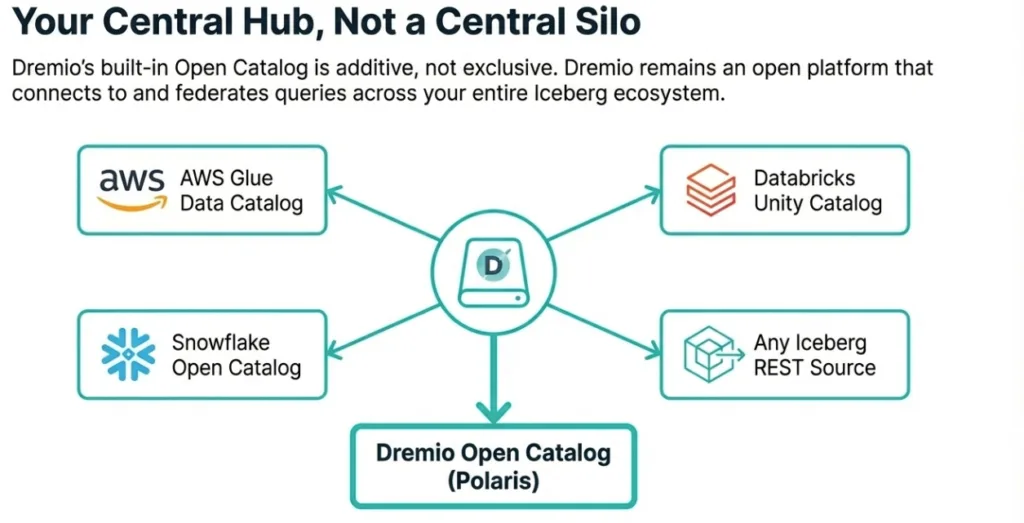
Your catalog, the central pillar of your lakehouse, is a free and open foundation, not a recurring cost center. This open approach also extends to connecting with other existing catalogs you may have, such as AWS Glue or Unity Catalog, allowing Dremio to query data in place.
Takeaway 2: Embrace Radical Flexibility with a "Bring Your Own" Architecture
Dremio’s open-platform philosophy extends beyond the catalog, giving you the freedom to choose your own components for compute, storage, and even artificial intelligence.
Bring Your Own Compute
Because the Open Catalog adheres to the Iceberg REST standard, you are not locked into Dremio’s query engine. You can connect your catalog to any compatible engine, whether it’s a large-scale Spark cluster or Apache DataFusion scripts running on your laptop. Dremio does not charge you for compute resources used by these external engines.
Bring Your Own Storage
While the first Dremio Cloud project in a Dremio Org (the free trial) may initially use Dremio-managed storage for convenience, you have the option to use your own. After upgrading your account (by adding a credit card), you can create new projects configured to use your own AWS S3 buckets for storage. Dremio provides clear instructions for setting up the necessary IAM roles. When you use your own S3 buckets, Dremio does not charge you for data storage.
Bring Your Own LLM
Dremio includes an internal AI agent to help you explore and analyze data using natural language. However, you are not required to use Dremio's provided model. You can configure the agent to be powered by your own LLM from providers like OpenAI, Anthropic, Google Gemini, AWS Bedrock, or Azure OpenAI. When you connect your own model provider, you are not charged by Dremio for AI usage.
Bring Your Own Catalog
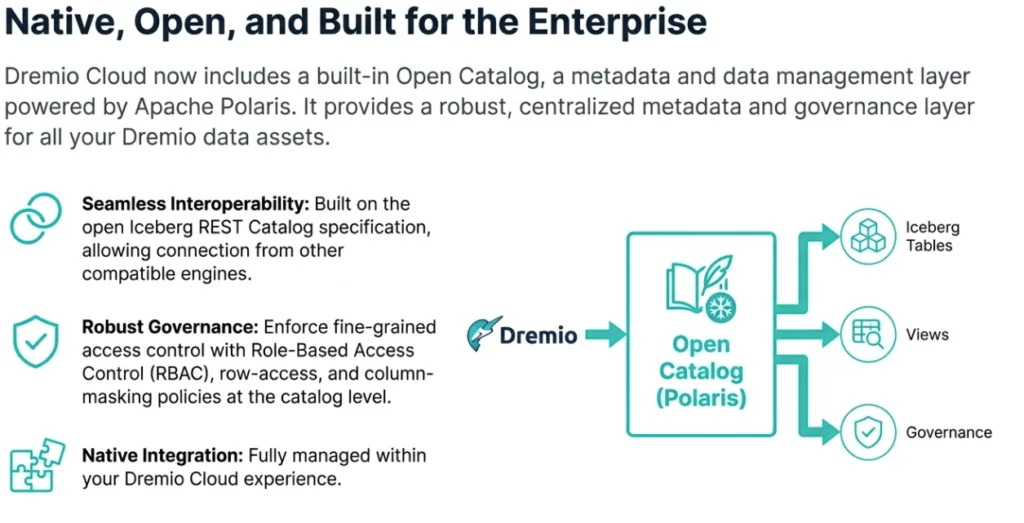
While every Dremio project has a built-in catalog integrated into the experience that provides RBAC, automatic table optimization, and more, Dremio also enables you to connect all of your existing Apache Iceberg Catalogs external to Dremio via its Iceberg Rest, AWS Glue, Unity Catalog, and Snowflake Open Catalog connectors. This allows you to benefit from Dremio’s first-class Apache Iceberg query performance features like end-to-end caching and autonomous reflections on your Apache Iceberg tables everywhere. These catalogs can use any storage layer, whether AWS, Azure, GCP, or S3-compatible layers such as Minio. Dremio can also virtualize your data from non-iceberg sources like databases, data lakes, and data warehouses.
Takeaway 3: Simplify Governance and Multi-Tenancy
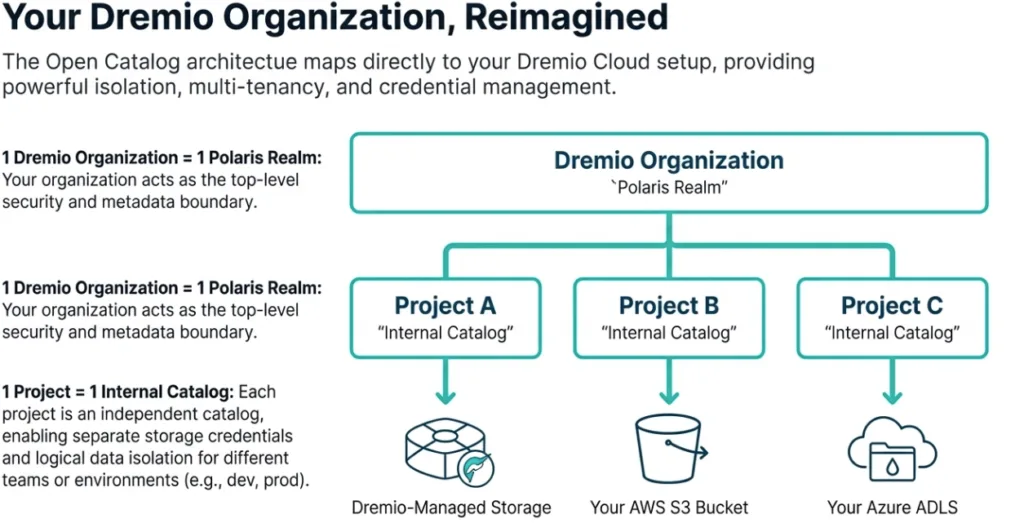
Dremio Cloud provides a simple yet powerful organizational structure that facilitates multi-tenancy and data governance. A Dremio Organization serves as the top-level container (An Apache Polaris “Realm” or Tenant), and within it, you can create multiple Projects. Each Project functions as a distinct and separate Apache Polaris internal catalog.
This structure is critical for creating a clean separation of data, administration, and even compute. For example, you can create dedicated Projects for different teams, like Marketing and Engineering, or for various stages of the development lifecycle such as dev, staging, and production. Each Project can be configured with its own unique AWS S3 storage location and credentials, ensuring that data is properly isolated. This model also allows you to segregate workloads, such as BI dashboards, ad hoc queries, and ETL jobs, into different compute engines, preventing "noisy neighbor" problems and enabling better cost allocation.
This architecture also enables robust governance. You can apply fine-grained security policies, including row-access and column-masking rules, directly to the Iceberg tables and views managed by the catalog, ensuring that sensitive data is protected consistently across your organization.
The Unlocked Lakehouse
The Power of an Open Platform
Dremio’s Open Catalog delivers a free, interoperable, and flexible foundation for the modern data lakehouse. By embracing open standards and a "bring your own" philosophy for compute, storage, and AI, Dremio provides a platform that prioritizes user choice and cost control over vendor lock-in. This commitment to openness gives you the flexibility to select the best tools to achieve your data analytics goals.
Now that your data catalog is no longer a point of lock-in, how will you redesign your data architecture for true flexibility and cost control?
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.