This is Part 2 of a four-part series on building a true agentic analytics platform. Part 1 introduced the three pillars: data unification, data meaning, and governed agentic access. This post goes deep on the first one.
Here's a problem that sounds mundane but is actually the root cause of most agentic analytics failures: AI agents can only answer questions about data they can see.
That seems obvious. But when you map it onto a real enterprise data environment (customer records in Salesforce, transactions in a data warehouse, telemetry logs in S3, product data in a PostgreSQL instance, and three-year-old historical data sitting in a legacy Oracle system) "what the agent can see" becomes a real architectural question.
The answer determines everything. Which questions can agents answer? Which insights do they miss? Whether they hallucinate because they're working with an incomplete context. Whether query times allow for real conversational interaction. Data unification is the foundation that makes the rest of agentic analytics work.
Why Agents Need a Complete, Unified View
Human analysts navigate fragmented data environments with patience, tribal knowledge, and a lot of Slack messages. They know that sales pipeline data lives in Salesforce, that the "canonical" customer table is in the warehouse (not the operational database), and that the S3 bucket in us-east-1 has the clickstream data they need. They've learned this over months.
Agents don't have that buffer. They operate based on what's available and what's described. If a data source isn't accessible, it simply doesn't exist from the agent's perspective. If it is accessible but improperly described, the agent will either skip it or use it incorrectly.
This matters more for agents than for traditional analytics in one important way: agents are often asked to synthesize across domains. A question like "Which customer segments have the highest support costs relative to their revenue?" requires joining customer revenue data (warehouse), support ticket data (probably a SaaS tool or operational database), and customer segment definitions (maybe a CRM or an internal taxonomy table). No single source has all of it.
Without data unification, an agent either gives a partial answer or gives up.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
The Two Components of Data Unification
Solving the data unification problem requires two complementary capabilities that most platforms treat separately. A strong agentic analytics platform delivers both as integrated pieces of the same architecture.
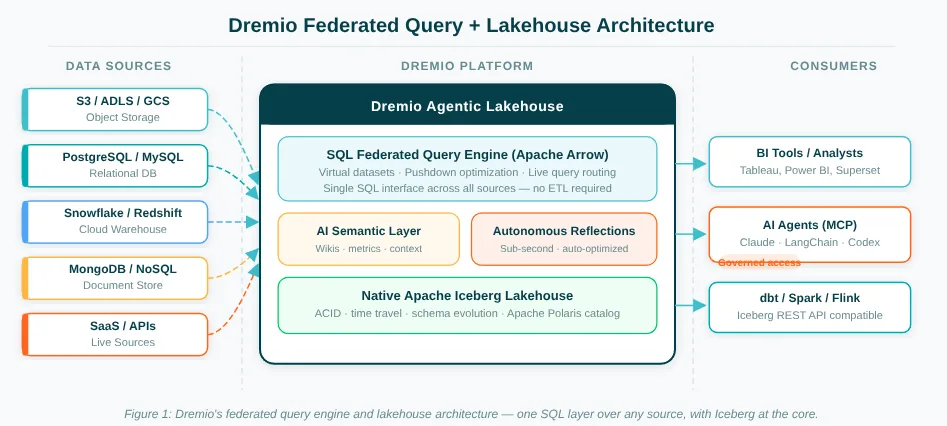
Figure 1: Dremio's federated query engine routes queries across any source without ETL, while the native Iceberg lakehouse manages and optimizes your core data assets.
Federation: Querying Data Where It Lives
The traditional approach to data unification is ETL: extract data from source systems, transform it, and load it into a central warehouse. It works, eventually. But it introduces delay (pipelines run on schedules, not in real time), duplication (you now have two copies of the data to maintain), and brittleness (pipelines break when source schemas change).
For agentic analytics, ETL pipelines pose another problem: they're designed for datasets someone anticipated would be useful. Agents often need to access data that wasn't in scope when the pipelines were built. An agent answering an unexpected question about a rarely-queried source might not find what it needs in the warehouse.
Federation solves this differently. Instead of moving data to the compute, federation brings compute to the data. A federated query engine can connect to source systems directly (S3 buckets, PostgreSQL databases, Snowflake, MongoDB, cloud data warehouses) and execute SQL queries against all of them from a single interface. No ETL pipeline required. No waiting for a sync job. Live data, queried where it lives.
For agents, this means access to the full data environment, not just what was preemptively loaded into a warehouse.
Dremio's federated query engine, built on Apache Arrow for in-memory performance, connects to dozens of source types: cloud object stores, relational databases, NoSQL stores, SaaS platforms, and other data warehouses. An agent querying Dremio can cross source boundaries in a single SQL statement. One query might join a table from S3, filter against a reference table in PostgreSQL, and aggregate on a metric view spanning multiple sources. The agent writes SQL; Dremio handles the routing.
Virtual datasets are part of what keeps this manageable. Data engineers can define curated, named views that abstract away source complexity, so agents don't have to know the difference between prod_db.orders and warehouse.fact_orders. They query the virtual dataset; the platform resolves it.
Figure 2: ETL moves data to the query. Federation moves the query to the data. The difference shows up in freshness, engineering overhead, and what agents can actually reach.
The Lakehouse: Your Own Data, Governed and Fast
Federation is excellent for accessing data that lives in other systems. But most enterprises also have significant data that lives in their own cloud storage: S3, Azure Data Lake Storage, Google Cloud Storage. This is often the largest and most valuable dataset: logs, events, transactions, ML training data, and historical archives.
Managing this data well is what a lakehouse does. And the quality of the lakehouse capability in your agentic analytics platform matters enormously.
The modern open lakehouse standard is Apache Iceberg. Iceberg tables in cloud object storage give you ACID transactions (so concurrent writes don't corrupt data), time travel (so agents can query historical states), schema evolution (so tables can change without breaking downstream queries), and fine-grained metadata that enables extremely efficient query planning.
A strong lakehouse platform doesn't just read and write Iceberg tables. It actively manages them. That means automated table optimization: compaction (merging small files that accumulate over time), clustering (physically organizing data to enable faster predicate pruning), and vacuuming (cleaning up deleted or expired data). Without these, Iceberg tables degrade in query performance over time.
Dremio is a core contributor to the Apache Iceberg project and the co-creator of Apache Polaris, the open catalog standard that enables interoperability among Iceberg tables across engines like Spark, Flink, and Trino. Dremio's catalog handles automated table optimization without manual intervention. Clustering alone can deliver significant query performance improvements on large Iceberg datasets, and it all happens without a DBA scheduling jobs.
Autonomous Reflections are worth calling out specifically. These are smart materializations that Dremio creates and maintains automatically based on observed query patterns. When an agent (or human) runs a query frequently enough, Dremio detects the pattern and builds an acceleration structure, a precomputed materialization, that serves future similar queries in sub-second time. The agent continues to query the underlying tables; it just gets answers much faster without knowing any optimization happened.
What This Looks Like for an Agent in Practice
Picture an AI agent tasked with answering: "What are the top product categories driving customer churn among enterprise accounts this quarter?"
To answer that, the agent needs:
Customer segmentation data (likely in a CRM or warehouse)
Churn events (either in the warehouse or logged to a data lake as events)
Product usage data (possibly in a different operational database or event log)
Revenue classification by account tier (probably in the warehouse or a finance system)
With a properly federated lakehouse platform, this is a four-source join that the agent can compose in SQL and execute in seconds. Without federation, the agent hits a wall at the first source boundary.
The lakehouse side matters when the churn event data and usage logs live in S3 as Iceberg tables. A well-managed lakehouse means those tables are compact, clustered, and up to date, not slow because no one remembered to run a compaction job last week.
Why Open Standards Matter for Long-Term Unification
One data unification trap: building on a proprietary storage format or catalog that only one engine understands. As agentic workloads mature, enterprises will run multiple AI frameworks, multiple query engines, and multiple compute environments against the same underlying data. A proprietary format locks you into one vendor's query layer.
Apache Iceberg's open table format, combined with the Iceberg REST API implemented by Apache Polaris, enables interoperability for Dremio's lakehouse. A Spark job, a Flink pipeline, and a Dremio AI agent can all work with the same Iceberg tables, with full ACID semantics and no format translation. That's the architecture that scales as agentic workloads grow.
For data engineers building the foundation for agentic analytics, this open-standards approach also means less lock-in risk. The investment in modeling data as Iceberg tables is portable. The catalog is accessible to any Iceberg-compatible engine. Dremio handles the performance and governance layer without trapping the underlying data.
Building the First Pillar
Data unification for agentic analytics comes down to two practical commitments:
Give agents access to everything. A federated query layer that covers all your data sources means agents start with a complete picture. No important data source should be off-limits because it wasn't included in an ETL pipeline.
Maintain the data you own. A well-managed lakehouse ensures that your core data assets are performant, governed, and consistent. Automated optimization means that as data volumes grow and query patterns evolve, performance doesn't degrade.
For data engineers building the foundation for agentic analytics, this open-standards approach also means less lock-in risk. The investment in modeling data as Iceberg tables is portable. The catalog is accessible to any Iceberg-compatible engine.
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Aug 16, 2023·Dremio Blog: News Highlights
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.