This is Part 3 of a four-part series on building a true agentic analytics platform. Part 1 introduced the three pillars; Part 2 covered data unification through federation and the lakehouse. This post focuses on the second pillar: data meaning.
The agent has access to all your data. It can query across your data lake, your warehouse, and a half-dozen connected sources. Federation is working. The lakehouse is clean and fast.
Now you ask it: "What's our monthly active user count?"
And the agent queries the wrong table.
Not because it can't write SQL. It can. Not because the data isn't accessible. It is. It returned a number with confidence, just the wrong one, because your platform has three different tables that could plausibly be "monthly active users," and without any encoded context about which one is authoritative, the agent made its best guess.
This is the data meaning problem. And it's the second pillar that separates a real agentic analytics platform from a fast query engine with an AI interface bolted on top.
What Agents Don't Know That Analysts Do
Senior analysts at any data-mature company carry a map in their heads. They know which tables are production-ready and which are experimental. They know that revenue in the finance team's dashboard means recognized revenue, while the same column name in the sales team's dataset means bookings. They know the customer ID schema was changed 18 months ago, and there are two different formats in circulation across the warehouse.
That institutional knowledge wasn't documented. It was accumulated through experience, mistakes, conversations, and a constant process of correction.
AI agents don't have that background. They have what's encoded in the platform. If business definitions aren't explicitly captured and surfaced at query time, the agent has no way to distinguish between "this is the right table" and "this table has the right name but is used for a different purpose." It fills that gap by guessing, usually using pattern matching on column names and table names, which is a proxy for understanding, not the real thing.
The result is that agents produce plausible-looking answers that may not be correct. In a dashboard, a wrong number is caught when someone challenges it in a meeting. In an agentic workflow where the agent's output drives a downstream decision or automation, it might not be caught at all.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
What a Semantic Layer Actually Does
The semantic layer is the platform layer that holds the meaning of data, separate from the data itself.
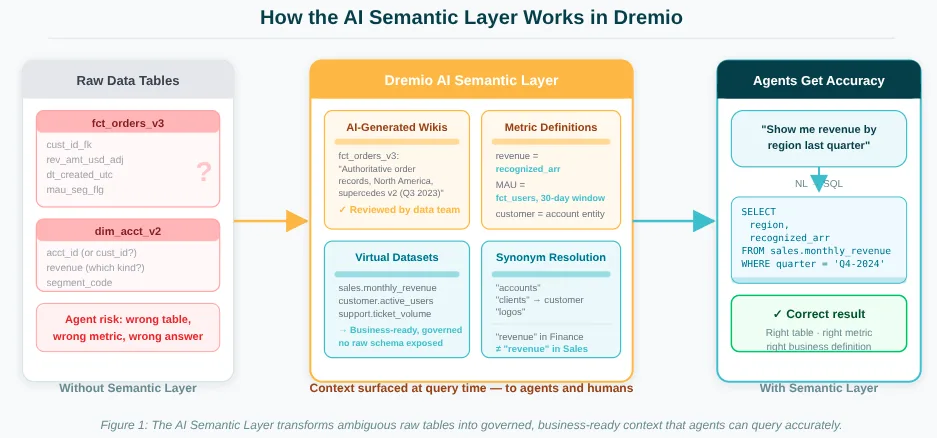
Figure 1: Without a semantic layer, agents guess. With it, they get AI-generated wikis, metric definitions, virtual datasets, and synonym resolution, surfaced at query time.
At its core, a semantic layer does four things:
Defines metrics consistently. Rather than letting every query define "monthly active users" independently, the semantic layer holds one authoritative definition: which table, which column, which filter, which time grain. Any query from any agent or human analyst that references MAU uses that definition. Consistency becomes structural, not cultural.
Documents tables and columns with business context. A table named fct_orders_v3 tells an agent very little. A table documented as "authoritative order records for the North American market, used for finance and operations reporting, supersedes fct_orders_v2 as of Q3 2023" gives the agent enough to make a good decision about whether that's the right table for a given question.
Resolves naming conflicts and synonyms. Business data is full of multiple names for the same thing and the same name for different things. A semantic layer can register that "accounts," "clients," "customers," and "logos" all refer to the same entity, and that "revenue" means different things depending on the business function being analyzed.
Encodes relationships. Which tables join to which, what the join keys are, which tables are fact tables versus dimension tables. Agents can infer some of this from schema inspection, but they make errors. Explicit relationship definitions reduce those errors dramatically.
Figure 2: Virtual datasets are the correct interface between raw tables and AI agents. Curated, documented, and governed, they replace 47 cryptic raw tables with 8 business-ready views an agent can navigate accurately.
Why the Semantic Layer Has to Be AI-Aware
Traditional semantic layers were built to serve human analysts through BI tools. The definitions lived in the BI platform (Looker, Tableau, or similar) and they were used when a human ran a report. Outside of that environment, the definitions didn't apply.
Agentic analytics breaks this model. Agents don't work through BI tools. They work through query interfaces, MCP servers, or API calls. A semantic layer that only surfaces its context inside a BI platform is invisible to agents.
An AI-aware semantic layer has to work differently. The context has to be available in forms that agents can consume: as structured metadata surfaced through search tools, as descriptions returned alongside schema information, as constraints and join definitions that inform SQL generation. When an agent calls a tool to explore a dataset, the semantic layer's context should come back as part of the response, not as a separate documentation step the agent has to take.
There's also a generation component that's increasingly important. Building a comprehensive semantic layer manually is slow. At most enterprises, it never reaches full coverage because documenting every table and column is a maintenance burden that grows faster than data teams can keep up with. AI-generated semantic documentation, using LLMs to analyze table structure, query history, and existing documentation to produce draft definitions, dramatically accelerates this process. The human data team's job shifts to reviewing and curating, rather than writing from scratch
.
How Dremio's AI Semantic Layer Works
Dremio's AI Semantic Layer addresses this directly. It's not a documentation system that lives outside the query engine. It's integrated into the platform that agents use to query data.
Wikis and descriptions are attached to tables, columns, and virtual datasets within Dremio. These surfaces automatically when an agent (or human) explores the data environment. When Dremio's MCP Server returns schema information to an AI agent, it includes the semantic context alongside the structural metadata. The agent knows not just what columns exist but what they mean.
AI-generated wikis accelerate the coverage problem. Dremio analyzes table structures and query patterns to generate draft documentation that data teams can review and approve. Instead of starting from a blank page, a data engineer can review a suggested description, edit it for accuracy, and publish it in a fraction of the time.
Virtual datasets are central to how this works in practice. A virtual dataset is a named, saved view in Dremio that presents data in a business-ready form. An agent querying sales.monthly_revenue gets a clean, pre-defined, documented view, not a raw fact table with ambiguous column names and no context. These virtual datasets become the interface between the raw data and the agents that consume it, with all the business logic and documentation baked in.
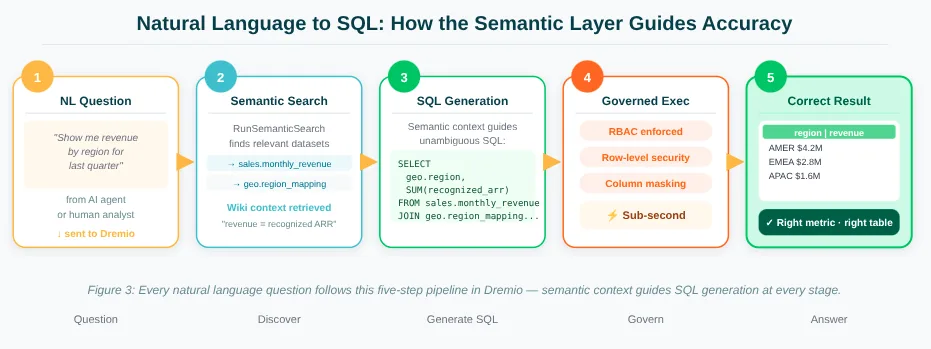
The semantic layer also supports Dremio's natural language-to-SQL capability. When a business user or agent sends a question in natural language, the AI Agent uses the semantic context to disambiguate the question before generating SQL. "Show me revenue by region last quarter" becomes a correctly constructed query because the platform knows which "revenue" field is authoritative, how regions are defined, and which tables hold that combination of data.
Figure 3: Dremio's natural language to SQL pipeline is guided by semantic context at every step, from discovery through execution, so the resulting query reflects actual business intent, not just pattern matching.
The Practical Impact: What Agents Can Do With a Good Semantic Layer
The difference shows up most clearly in the types of questions agents can answer reliably.
Without a semantic layer, agents handle simple factual queries well. "How many orders were placed yesterday" against a table where the structure is unambiguous is straightforward. Multi-domain questions with business terminology are where they struggle. Anything involving metrics defined across multiple tables, terminology that has multiple possible interpretations, or context that isn't obvious from column names alone tends to produce answers that look right but aren't.
With a good semantic layer, agents can handle the messier, more valuable questions: cross-functional analysis, trend comparisons across business definitions, performance metrics that require knowing how the business actually calculates things. These are precisely the questions that take a human analyst the longest, and where agent automation would deliver the most value.
There's a governance dimension too. A semantic layer that defines which tables are production-ready means agents route queries to the right datasets by default. Documentation that clarifies table ownership and data freshness lets agents communicate uncertainty when it exists. The semantic layer isn't just about getting the right answer. It's about agents knowing when they might be working with incomplete or stale context.
Building the Second Pillar
If your platform has good data access but weak semantic context, agents will be inconsistent at best and confidently wrong at worst. The investment in the semantic layer pays off not just in agent accuracy but in the reliability of every downstream workflow that depends on agent output.
A few concrete steps to strengthen the semantic layer:
Start with your most-used datasets. The tables your analysts query every day are the most important to document well. Those are also the datasets most likely to surface to agents first.
Use virtual datasets as the agent interface. Rather than exposing raw source tables, create curated virtual datasets that reflect how business users actually think about the data. Document them with business context, not just technical schema descriptions.
Let AI help with coverage. AI-generated documentation isn't a replacement for human curation. It's a way to get from 0% coverage to 80% coverage quickly, so human effort can focus on the 20% that needs careful attention.
Intro to Dremio, Nessie, and Apache Iceberg on Your Laptop
We're always looking for ways to better handle and save money on our data. That's why the "data lakehouse" is becoming so popular. It offers a mix of the flexibility of data lakes and the ease of use and performance of data warehouses. The goal? Make data handling easier and cheaper. So, how do we […]
Aug 16, 2023·Dremio Blog: News Highlights
5 Use Cases for the Dremio Lakehouse
With its capabilities in on-prem to cloud migration, data warehouse offload, data virtualization, upgrading data lakes and lakehouses, and building customer-facing analytics applications, Dremio provides the tools and functionalities to streamline operations and unlock the full potential of data assets.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.