Apache Iceberg, the open and interoperable table format that has become the industry standard for the modern data lakehouse, adds meaningful new capabilities in Iceberg version 3 (V3). With the March release of Dremio Cloud, those capabilities are now available in all regions. The release brings multiple support for multiple areas:
VARIANT Support: Processing a new data type - called VARIANT - that allows the Iceberg Lake to support semi-structured data (aka JSON). The VARIANT data type is now a first-class citizen. Semi-structured data stored as VARIANT gets the same columnar encoding and query optimizations as regular typed columns, no JSON parsing at query time anymore. Typical use cases include telemetry, security, and observability, as well as application data stored in JSON.
Deletion Vectors: Deletion vectors make row-level change management faster and cleaner, simplifying change data capture (CDC) pipelines. Any use case that has smaller row-level changes will see a significant acceleration in performance and cost savings
New Data Type: Universal Unique Identifier (UUID) support as a native column type in your tables.
Row-Level Lineage: Iceberg now stores row-level lineage information in a vendor-agnostic way. This enables much higher declarative auditability as well as additional metadata for AI agents to ascertain the source of specific rows of information.
Further to these, the April Release of Dremio Cloud will bring Iceberg nanosecond timestamps.
This post covers what's new, what it solves, and how to use it at a deeper technical level.
VARIANT for Semi-Structured Data Without Tradeoffs
Semi-structured data creates the same issues for all data teams. Event streams arrive from APIs, webhooks, IoT devices, and application logs, each with its own schema. Some events have an action field; some have nested pull_request objects; others have arrays of commits. The shape of this data varies not only across sources but also across event types within the same source.
Until now, teams had two imperfect options: flatten everything into a wide table with hundreds of nullable columns, or declare nested STRUCTs with typed fields. Wide tables tolerate missing fields but waste storage, and still require ALTER TABLE when new fields appear. . STRUCTs are clean and perform well, but every record must conform to the same rigid structure. Both approaches break down when the shape of incoming data changes frequently.
The Iceberg V3 VARIANT type eliminates these compromises. VARIANT is a native binary column type that stores semi-structured data, such as JSON objects, arrays, scalars, and nulls. VARIANT stores data in an optimized format that the query engine understands natively. VARIANT eliminates the need for schema flattening at ingest time and expensive JSON text parsing at query time. VARIANT data is ingested as-is, and you query it using SQL.
Try Dremio’s Interactive Demo
Explore this interactive demo and see how Dremio's Intelligent Lakehouse enables Agentic AI
A Real Example Using GitHub Events
GitHub's public Events API is a perfect illustration of the VARIANT use case. Like many public APIs, the events in the GitHub Events API include a common envelope: an ID, a type, an actor, a repository, and a timestamp. After the fixed envelope, the payload field varies significantly across event types: PushEvent, PullRequestEvent, WatchEvent, and others.
With VARIANT, the table schema stays clean:
To store events, define typed columns for the structured envelope fields and create a VARIANT for the polymorphic payload that changes for each event type. GitHub's API, like most modern APIs, returns data as JSON. The payload arrives ready to store using PARSE_JSON, which converts the JSON string to Dremio's binary VARIANT format on insert. TRY_PARSE_JSON does the same but returns NULL instead of an error on malformed input, which is useful when ingesting data from sources where JSON validity isn't guaranteed.
Query VARIANT Data
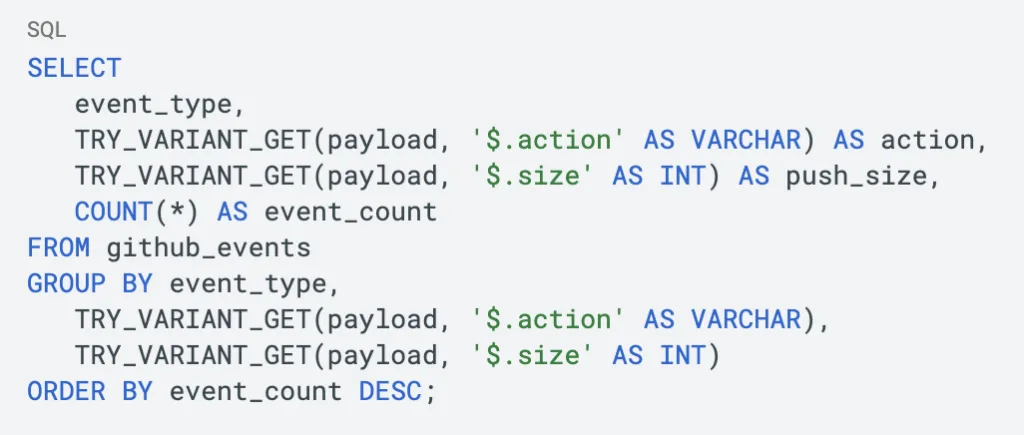
The VARIANT_GET function extracts typed values from the payload using path expressions:
The syntax VARIANT_GET(column, '$.path' AS TYPE) reads naturally: retrieve the value at this path and cast it to this type. The $ represents the root of the variant. Nested paths like '$.pull_request.merged', '$.commits[0].message', and '$.repo.owner.login' navigate into objects and arrays.
For analytical queries, VARIANT integrates with standard SQL aggregation. TRY_VARIANT_GET returns NULL instead of an error when the cast fails, which is very useful when querying across event types where the same path may hold different types. Note that GROUP BY, DISTINCT, and JOIN required extracted typed values - you can not aggregate on raw VARIANT columns directly.
VARIANT_GET also supports extracting typed arrays. For example, VARIANT_GET(payload, '$.commits' AS ARRAY<VARCHAR>) returns the commits array with each element cast to VARCHAR, and TRY_VARIANT_GET handles cases where the array contains mixed types by returning NULL for elements that can't be cast.
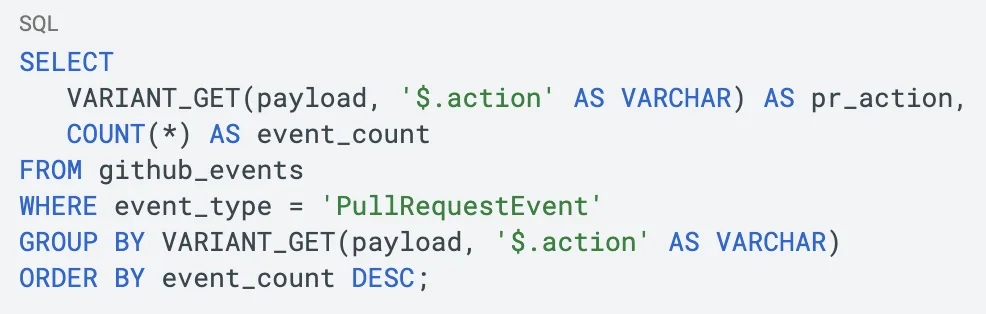
VARIANT_GET can be used with CASE, GROUP BY, and other standard SQL:
Type Inspection and Null Semantics
VARIANT includes a complete library of type-checking functions. TYPEOF returns the internal type of a variant value.Functions such as IS_VARCHAR, IS_BIGINT, IS_BOOLEAN, IS_OBJECT, and IS_LIST test specific types, which can be essential when the same path may contain different types across event payloads. Type checks are available for all supported types, including IS_INT, IS_DOUBLE, IS_DECIMAL, IS_TIMESTAMP, and IS_UUID.
VARIANT distinguishes between a missing path and a path that exists but holds a null value. Standard SQL IS NULL catches missing paths. IS_VARIANT_NULL returns TRUE where the field is present but explicitly set to NULL. The distinction between NULL types matters for data quality logic, and Dremio supports both checks:
VARIANT Data Storage
VARIANT stores data in Parquet's binary variant encoding, not as a serialized string. The binary format uses offsets and type tags to enable the query engine to navigate directly to the requested path without parsing the full JSON structure.
Because the binary format tags each value with its type, the engine knows that 42 is a number and "42" is a string without parsing anything. Type-checking functions such as IS_BIGINT and IS_VARCHAR work directly against these tags, which is not possible when JSON is stored as plain text.
Columnar Performance with Variant Shredding
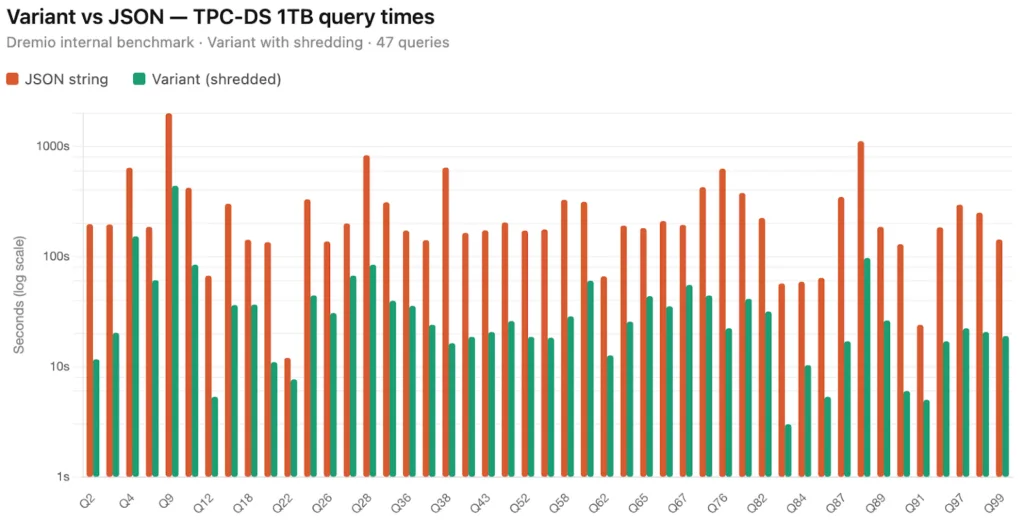
Dremio has implemented variant shredding, a capability not yet available in most query engines. It extracts frequently accessed fields from variant values into separate columnar chunks within Parquet, so shredded fields benefit from the same columnar storage advantages as regular typed columns, compact encoding, compression, and reduced deserialization overhead. We are actively working on extending this to include field extraction pushdown and predicate filtering using Parquet min/max statistics on shredded columns, bringing Variant read performance even closer to native typed columns. Shredding is handled automatically by the system, requiring no manual configuration, and delivers measurable query performance gains for semi-structured data workloads:
Across 47 TPC-DS queries at 1TB scale, Variant with automatic shredding delivers up to 10x faster reads compared to JSON-string storage, with consistent gains across the full query suite. The more selective the field access, the bigger the payoff.
Shredding is enabled by default but can be disabled for write-heavy workloads where the write overhead isn't justified. Dremio can also read shredded variant data produced by Spark and other compatible engines, preserving the columnar read performance regardless of which engine wrote the data.
Looking ahead, we are actively working on pushing field extraction and predicate filtering down to the scan layer, which will enable the engine to skip unneeded shredded columns entirely and apply row-group and page-level filtering using Parquet statistics on shredded fields. These optimizations will further close the performance gap between Variant queries and queries on traditional typed columns.
Faster Deletes and Updates with Deletion Vectors
Iceberg V2 introduced row-level deletes, which enabled delete operations without rewriting entire data files but introduced a read-time penalty for downstream consumers. Every delete operation created position delete files that had to be merged with data files at query time. As delete files accumulated, read performance degraded. The workaround was frequent compaction, which consumed compute and added maintenance overhead.
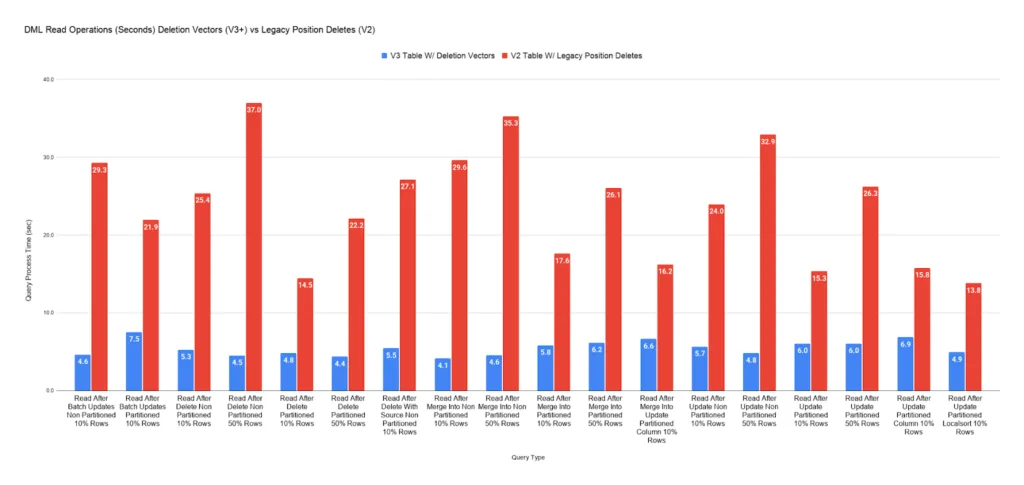
Deletion vectors replace position-deletion files with a compact bitmap that marks deleted rows directly within the data file's metadata. The read performance improvement is significant. Rather than joining against an external delete file at query time, the engine checks a local bitmap directly within the data file's metadata. Our testing shows a substantial read performance improvement of 50-80% compared to Iceberg V2 positional deletes.
Tables with deletion vectors deliver substantially better read performance than those using positional deletes.
For teams running workloads with frequent updates or deletes, such as CDC pipelines, GDPR compliance, and data retention policies, deletion vectors significantly reduce the accumulation of delete files that degrade read performance in V2. However, periodic compaction with OPTIMIZE TABLE remains essential.
For Iceberg V3 tables in Dremio, deletion vectors are enabled by setting the merge-on-read table properties. Here’s an example with an Iceberg V3 table we created earlier, github_events.
Once enabled, DELETE, UPDATE, and MERGE operations automatically use deletion vectors. Using the github_events table:
Both the DELETE and UPDATE above produce deletion vector entries rather than rewriting the underlying data files. Reads skip the marked rows automatically. The next OPTIMIZE TABLE consolidates the remaining live rows into clean files.
Nanosecond Timestamps for High-Frequency Data
Iceberg V3 introduces nanosecond timestamp precision with TIMESTAMP(9), extending beyond the microsecond precision available in earlier format versions.
Nanosecond precision is critical in domains where microsecond precision is insufficient, including high-frequency trading systems, IoT sensor networks, and industrial telemetry systems. Scientific instrumentation in particle physics, genomics, and astronomical observation often requires nanosecond precision.
Simple Schema Evolution Using Default Values
Adding a column to an existing table is straightforward in Iceberg. New columns are NULL for every existing row that was there prior to the column being added. But if the column should have a value, in V2, you have to UPDATE every row. Storing individual values is especially wasteful for low-cardinality columns where most rows share the same value: a status column that should be 'pending', a priority column starting at 0, or an is_expedited flag that should be FALSE.
Iceberg V3 introduces default column values for primitive types in the table schema, and Dremio will add support in mid-April:
Default values simplify schema evolution, particularly for tables that frequently change in response to evolving business requirements. When you add a new column with a default value to an existing table, the engine returns the default for rows in data files that predate the column. When inserting new rows, columns with default values do not need to be specified. The engine automatically applies the default from the table schema. UPDATE operations are not required on default rows because default values are stored in Iceberg metadata.
Native UUID
A UUID is a universally unique identifier. Dremio adds native support for the UUID type in this release. Rather than storing UUIDs as strings and relying on consistent formatting, the UUID type stores them in a compact 16-byte binary format.
The GENERATE_UUID() function generates version 4 (random) identifiers. The UUID column type stores any UUID version in a compact 16-byte binary representation, so comparisons and joins are faster than VARCHAR equivalents. Dremio's UUID implementation supports equality and ordering comparisons compliant with RFC 4122 and RFC 9562.
Built-In Audit with Row Lineage
Row lineage is an Iceberg V3 metadata feature that tracks which write operation produced each row. Every data file written to an Iceberg V3 table includes lineage information tracing back to the specific snapshot and operation that created it.
For regulated industries that need to answer "when was this record written?" and "which process produced this data?", row lineage makes this intrinsic to the format rather than requiring external logging. Because it's part of the open Iceberg specification, lineage metadata written by Dremio is accessible from any Iceberg V3-compatible engine.
As agents both within and outside of Dremio analyze your data, they can take advantage of this additional row-level lineage information. This drives incremental trust in the tables and data the agent is assessing to ensure it can build and convey confidence to chat-based interactions and agent-based workflows.
Getting Started with Iceberg V3
Creating an Iceberg V3 table in Dremio is straightforward. Any table that uses an Iceberg V3-specific feature is automatically created as an Iceberg V3 table. You can also explicitly set the format-version table property to '3' on either a new or existing table. This is a one-way operation. You cannot downgrade back to V2.
Iceberg V3 tables are fully compatible with Dremio's existing SQL operations, optimization commands, and catalog integrations. The upgrade from V2 is seamless for applications because queries, inserts, updates, and deletes continue to work as expected, while Iceberg V3 provides additional capabilities.
The Open Lakehouse Moves Forward
Iceberg V3 represents a meaningful step in the open lakehouse's maturation. VARIANT makes semi-structured data a first-class citizen. Deletion vectors solve a longstanding performance problem for mutable workloads. Nanosecond timestamps, UUID, and row lineage address gaps in real production workloads. These capabilities are available now in Dremio Cloud, with Dremio Software support coming later this year.
Dremio's implementation of Iceberg V3 is built on the open Apache Iceberg specification, with no proprietary extensions or vendor lock-in. Tables created in Dremio can be read by any engine that supports Iceberg V3, and vice versa. Dremio Iceberg V3 library functions such as VARIANT_GET, PARSE_JSON, and IS_VARIANT_NULL share common names across major engines, making variant SQL portable across the Iceberg ecosystem.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.