Dremio eliminates the need for traditional ETL processes by unifying data access and accelerating insights where data resides.
The Unified Namespace and Open Catalog enable organizations to manage heterogeneous data sources efficiently without movement.
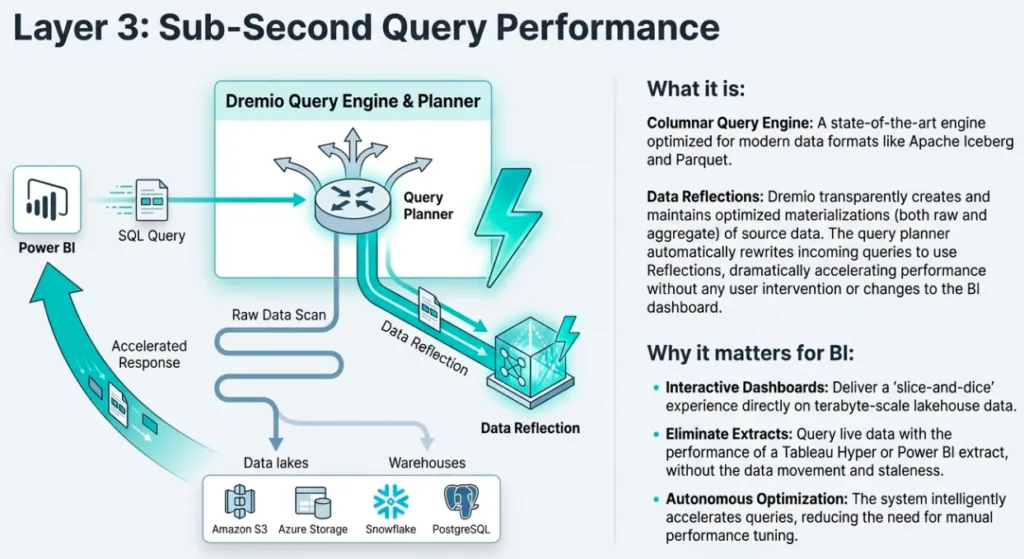
Reflections enhance dashboard performance by optimizing query execution without requiring SQL changes from users.
Apache Arrow Flight and ADBC reduce dashboard latency significantly, providing a client-agnostic results cache for consistent performance.
Dremio's Semantic Layer democratizes data engineering through AI integration, allowing analysts to find datasets and optimize queries using natural language.
For the modern analyst, the data experience is too often defined by a spinning wheel and the "ETL tax." Traditional architectures force a choice: suffer through slow dashboards by querying data in place, or wait weeks for engineering to move data into a proprietary warehouse. This warehouse-first mindset is a relic of the legacy era that creates a massive bottleneck for business value.
Dremio represents a visionary paradigm shift by unifying and accelerating data exactly where it lives. It is not just another query engine; it is a platform that eliminates the divide between raw storage and high-performance business intelligence. By integrating a sophisticated Semantic Layer with vectorized connectivity, Dremio provides a foundation for lightning-fast insights without the overhead of data movement.
The Unified Namespace: Ending the "Data Silo" Scavenger Hunt
The first barrier to organizational agility is the fragmented nature of modern data. Dremio’s Open Catalog provides a unified metadata and data management layer built on Apache Polaris. This creates a single organizational boundary for tables, views, and folders across heterogeneous sources, from S3 to relational databases.
As the documentation states, this architecture:
"Enables unified data access across heterogeneous sources without requiring data movement or ETL processes."
This approach is transformative because it removes the requirement to consolidate data before it is "query-ready physically." By supporting Apache Iceberg natively within a unified namespace, Dremio allows architects to govern and access data across the entire lakehouse as if it were a single, high-performance system.
Reflections: The Invisible Turbo Button for Dashboards
To bridge the gap between massive datasets and low-latency requirements, Dremio utilizes Reflections. These are physically optimized representations of source data stored as Apache Iceberg tables. Unlike traditional indexes, Reflections are transparent; Dremio’s optimizer automatically uses them to satisfy expensive joins and aggregations without requiring users to change their SQL.
A key technical advantage for architects is the ability to use the partitioning of Reflections. This allows you to partition the Reflection to accelerate queries for which the underlying source data wasn't initially optimized. BI teams can monitor these gains through the Jobs page, tracking metrics like total job time saved and average speedup provided by Autonomous Reflections.
To ensure a performant and maintainable foundation, Dremio recommends a "layered view" best practice. Architects should build from a Physical layer to a Preparation layer (cleansing), then a Business layer (joins/logic), and finally an Application layer for dashboard-specific views. This structured approach, combined with Reflections, creates a "Well-Architected" foundation for self-service BI.
Breaking the Speed Barrier: Apache Arrow Flight and ADBC
Legacy JDBC and ODBC drivers are often the silent killers of dashboard performance. Dremio shatters this barrier through Apache Arrow Flight and Arrow Database Connectivity (ADBC). These technologies enable a vectorized data pipeline that significantly reduces latency and optimizes resource usage by keeping data in the Arrow format from the engine to the BI tool.
The architecture also provides a client-agnostic results cache that acts as a major force multiplier. When a data engineer runs a query in the console to tune a view, they effectively "pre-warm" the cache for every executive viewing that same data in Power BI or Tableau. This ensures high-performance consistency across JDBC, ODBC, and Arrow Flight clients alike.
Pro-Tip: To unlock maximum speeds in Power BI, enable the ADBC option. Use the server URL adbc://data.dremio.cloud for the US control plane or adbc://data.eu.dremio.cloud for the European control plane to bypass legacy overhead.
The Living Semantic Layer: Where AI Meets Human Context
A Semantic Layer is only as valuable as its discoverability. Dremio combines an AI Agent with human-curated context, such as Wikis (supporting Markdown) and Labels. This "living" layer democratizes data engineering, allowing analysts to use natural language to discover datasets and generate complex SQL without manual intervention.
The AI Agent provides critical optimization insights for the technical architect:
Explain SQL: Uses the Dremio SQL Parser to identify referenced schemas and suggest performance optimizations.
Explain Job: Analyzes the query profile to identify bottlenecks in memory usage, data skew, network utilization, and threading efficiency.
Semantic Search: Allows users to find relevant sources, Reflections, and views using natural language across all metadata.
This self-service environment transforms the Semantic Layer into a collaborative "README" for the entire organization. By providing AI-driven recommendations on threading efficiency and skew, Dremio empowers analysts to solve performance issues that previously required a DBA.
Conclusion: The Shift from "Data Moving" to "Data Doing"
Dremio is the engine that finally transforms the lakehouse into a high-performance BI reality. By unifying namespaces, automating acceleration via Reflections, and utilizing the power of Apache Iceberg, it moves the organization away from the "data moving" era. The focus shifts from the plumbing of ETL to the actual "doing" of data science and analytics.
As you evaluate your current BI stack, consider the cost of your current ETL overhead. Is your team spending more time moving data than analyzing it? Transitioning to a unified, accelerated Semantic Layer is the definitive path to ending the era of the spinning wheel.
Ingesting Data Into Apache Iceberg Tables with Dremio: A Unified Path to Iceberg
By unifying data from diverse sources, simplifying data operations, and providing powerful tools for data management, Dremio stands out as a comprehensive solution for modern data needs. Whether you are a data engineer, business analyst, or data scientist, harnessing the combined power of Dremio and Apache Iceberg will undoubtedly be a valuable asset in your data management toolkit.
Oct 12, 2023·Product Insights from the Dremio Blog
Table-Driven Access Policies Using Subqueries
This blog helps you learn about table-driven access policies in Dremio Cloud and Dremio Software v24.1+.
Aug 31, 2023·Dremio Blog: News Highlights
Dremio Arctic is Now Your Data Lakehouse Catalog in Dremio Cloud
Dremio Arctic bring new features to Dremio Cloud, including Apache Iceberg table optimization and Data as Code.