Featured Articles
Popular Articles
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsBenchmarking Framework for the Apache Iceberg Catalog, Polaris
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsWhy Dremio co-created Apache Polaris, and where it’s headed
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsUnderstanding the Value of Dremio as the Open and Intelligent Lakehouse Platform
-

 Product Insights from the Dremio Blog
Product Insights from the Dremio BlogUsing the Dremio MCP Server with any LLM Model
Browse All Blog Articles
-
 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsBenchmarking Framework for the Apache Iceberg Catalog, Polaris
The Polaris benchmarking framework provides a robust mechanism to validate performance, scalability, and reliability of Polaris deployments. By simulating real-world workloads, it enables administrators to identify bottlenecks, verify configurations, and ensure compliance with service-level objectives (SLOs). The framework’s flexibility allows for the creation of arbitrarily complex datasets, making it an essential tool for both development and production environments.
-
 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsWhy Dremio co-created Apache Polaris, and where it’s headed
Polaris is a next-generation metadata catalog, born from real-world needs, designed for interoperability, and open-sourced from day one. It’s built for the lakehouse era, and it’s rapidly gaining momentum as the new standard for how data is managed in open, multi-engine environments. -
 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsUnderstanding the Value of Dremio as the Open and Intelligent Lakehouse Platform
With Dremio, you’re not locked into a specific vendor’s ecosystem. You’re not waiting on data engineering teams to build yet another pipeline. You’re not struggling with inconsistent definitions across departments. Instead, you’re empowering your teams to move fast, explore freely, and build confidently, on a platform that was designed for interoperability from day one.
-
 Product Insights from the Dremio Blog
Product Insights from the Dremio BlogUsing the Dremio MCP Server with any LLM Model
With traditional setups like Claude Desktop, that bridge is tightly coupled to a specific LLM. But with the Universal MCP Chat Client, you can swap out the brain, GPT, Claude, Gemini, Cohere, you name it, and still connect to the same tool ecosystem.
-
 Dremio Blog: News Highlights
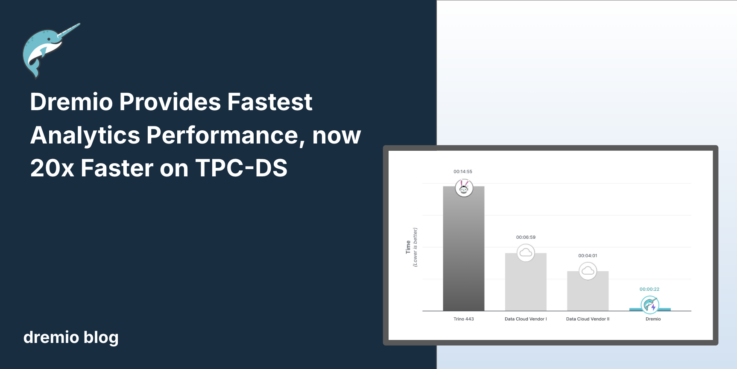
Dremio Blog: News HighlightsBreakthrough Announcement: Dremio is the Fastest Lakehouse, 20x Faster on TPC-DS
At Dremio, we have spent the last few years developing not only query execution improvements but also game-changing autonomous data optimization capabilities. Dremio is by far and away the fastest lakehouse. The capabilities deliver 20x faster query performance compared to other platforms, without requiring any manual actions.
-

 Dremio Blog: Various Insights
Dremio Blog: Various InsightsWhy Companies Are Migrating from Redshift to Dremio
Companies today are under constant pressure to deliver faster insights, support advanced analytics, and enable AI-driven innovation. Many organizations chose Amazon Redshift as their cloud data warehouse. However, as data volumes grow and workloads change, Redshift’s legacy warehouse architecture is not meeting their needs—driving many organizations to consider alternatives. Dremio’s intelligent lakehouse platform: a modern, […]
-

 Product Insights from the Dremio Blog
Product Insights from the Dremio BlogBuilding AI-Ready Data Products with Dremio and dbt
This guide will equip you with the expertise to easily build an AI-ready data product using Dremio and dbt.
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsExtending Apache Iceberg: Best Practices for Storing and Discovering Custom Metadata
By using properties, Puffin files, and REST catalog APIs wisely, you can build richer, more introspective data systems. Whether you're developing an internal data quality pipeline or a multi-tenant ML feature store, Iceberg offers clean integration points that let metadata travel with the data.
-

 Engineering Blog
Engineering BlogToo Many Roundtrips: Metadata Overhead in the Modern Lakehouse
The traditional approach of caching table metadata and periodically refreshing has various drawbacks and limitations. With seamless metadata refresh, Dremio now provides users with an effortless experience to query the most up-to-date versions of their Iceberg tables without wrecking the performance of their queries. So now a user querying a shared table in Dremio Enterprise Catalog powered by Apache Polaris for example can see updates from an external Spark job immediately with no delay, and they never even have to think about it.
-

 Dremio Blog: Partnerships Unveiled
Dremio Blog: Partnerships UnveiledUsing Dremio with Confluent’s TableFlow for Real-Time Apache Iceberg Analytics
Confluent’s TableFlow and Apache Iceberg unlock a powerful synergy: the ability to stream data from Kafka into open, queryable tables with zero manual pipelines. With Dremio, you can instantly access and analyze this real-time data without having to move or copy it—accelerating insights, reducing ETL complexity, and embracing the power of open lakehouse architecture.
-

 Product Insights from the Dremio Blog
Product Insights from the Dremio BlogIncremental Materializations with Dremio + dbt
Incremental materializations allow you to build your data table piece by piece as new data comes in. By restricting your build operations to just this required data, you will not only greatly reduce the runtime of your data transformations, but also improve query performance and reduce compute costs.
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsA Journey from AI to LLMs and MCP – 10 – Sampling and Prompts in MCP — Making Agent Workflows Smarter and Safer
That’s where Sampling comes in. And what if you want to give the user — or the LLM — reusable, structured prompt templates for common workflows? That’s where Prompts come in. In this final post of the series, we’ll explore: How sampling allows servers to request completions from LLMs How prompts enable reusable, guided AI interactions Best practices for both features Real-world use cases that combine everything we’ve covered so far
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsThe Case for Apache Polaris as the Community Standard for Lakehouse Catalogs
The future of the lakehouse depends on collaboration. Apache Polaris embodies the principles of openness, vendor neutrality, and enterprise readiness that modern data platforms demand. By aligning around Polaris, the data community can reduce integration friction, encourage ecosystem growth, and give organizations the freedom to innovate without fear of vendor lock-in.
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsA Journey from AI to LLMs and MCP – 9 – Tools in MCP — Giving LLMs the Power to Act
Tools are executable functions that an LLM (or the user) can call via the MCP client. Unlike resources — which are passive data — tools are active operations.
-

 Dremio Blog: Open Data Insights
Dremio Blog: Open Data InsightsA Journey from AI to LLMs and MCP – 8 – Resources in MCP — Serving Relevant Data Securely to LLMs
One of MCP’s most powerful capabilities is its ability to expose resources to language models in a structured, secure, and controllable way.
- 1
- 2
- 3
- …
- 30
- Next Page »