



Claiming Open Is Easy. Building Open Is Not. Don’t Be Duped.
An open lakehouse is now a universal vendor claim. It is not a universal reality. This has become even more important in the AI-centric world we live in as well as the AI-based outcomes we are now responsible for.
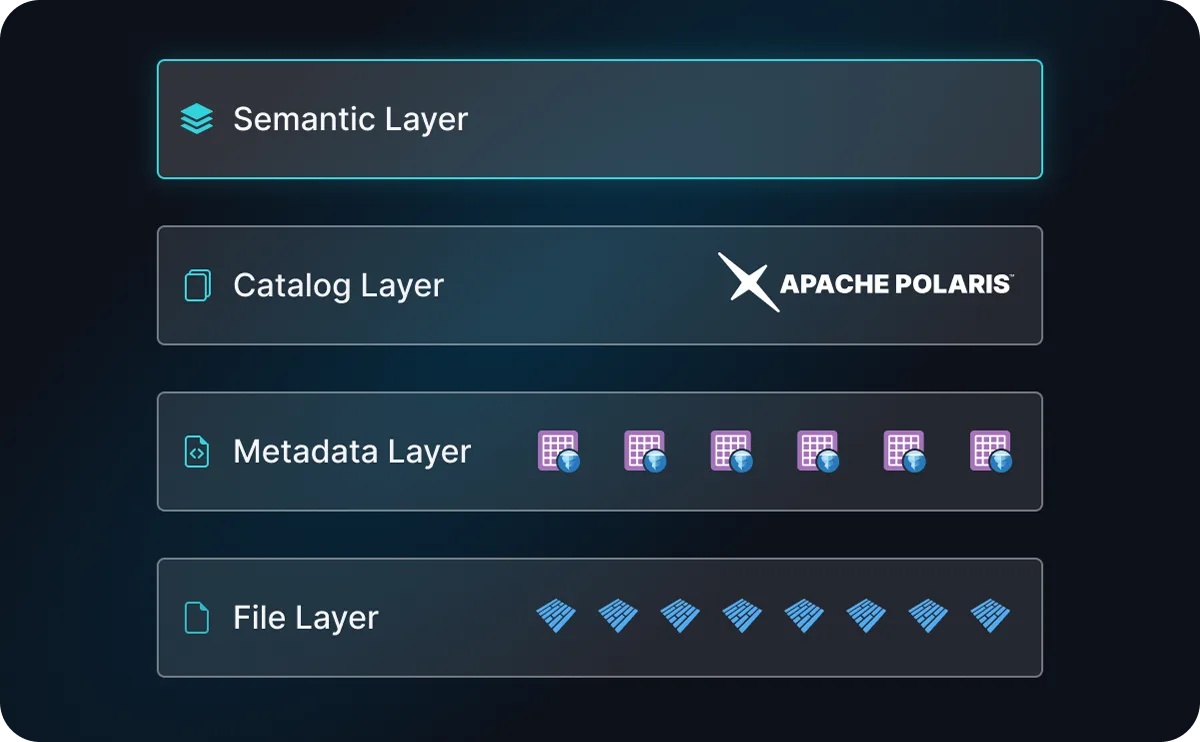
To achieve an open lakehouse that gives you flexibility, choice, and economic control, you need to assess all the fundamental layers:
Genuine openness - defined as multi-vendor, community support ecosystem - in these three areas is what gives your organization the ability to choose, change, and extend your platform without penalty. The above gives you the foundation for the lakehouse, but what else is needed in an AI-centric world where Agents will be primary drivers of query volume?
Within the next twelve months, the fourth layer will be the Semantic Layer:
Several vendors have gone about “open sourcing” their code base with the guise that this is for the benefit of the community. This is purely a marketing stunt - when only one vendor controls the majority of the code base, controls who contributes to it, controls the governance model, is it truly an open source project or a way to show openness, while they sell you their commercial lock-in solution?
This is why Apache Iceberg has been chosen by the broader community over Delta Lake, and why we believe Apache Polaris will be chosen over time versus other so-called “open” catalogs.
Within Dremio, we have changed AI tools 3 times in the last 9 months as they have advanced by leaps and bounds. Open layers allow for this flexibility - proprietary solutions or so called open standards built by a single vendor will keep you beholden to their evolution. While organizations getting this wrong are discovering the cost at renewal time (there is a reason these vendors have a high NDR), they are also beholden to these providers when AI tools evolve.
Three Layers. One Standard. No Lock-In.
File layer. Table format. Catalog. All three need to be open.
The file layer is where your actual data physically lives — raw and processed files stored as open formats on object storage like S3 or ADLS. Apache Parquet has become the gold standard here, not because it is the best format for every use case, but because it is universally accessible across engines, tools, and clouds. That universality is what makes it durable. When your data is in Parquet on open storage, no single vendor controls access to the bits themselves. That is the foundation everything else builds on.
The metadata layer is really the table format that turns a collection of raw Parquet files into coherent, queryable tables — with schema evolution, partition management, snapshot history, and ACID transaction guarantees. Apache Iceberg won this layer, and the reason matters: it is multi-vendor and community-governed under the Apache Software Foundation, meaning no single company controls the roadmap. AWS, Google, Microsoft, Snowflake, Databricks, and Dremio all support Iceberg and the fact that competing vendors have converged on the same standard is precisely what gives it durability. That governance model, not any single technical feature, is what drove the broadest adoption and made Iceberg the default for new lakehouse deployments. Organizations are increasingly consolidating on Iceberg because community governance is the lock-in protection that technical capabilities alone cannot provide.
The catalog is the layer that ties everything together — it tracks what tables exist, where they are stored, who can access them, and how engines coordinate against shared data. Without an open catalog, even Iceberg tables on Parquet files create partial lock-in: discovering and governing your data still depends on a proprietary service. Apache Polaris is following the exact pattern that made Iceberg the standard. It is multi-vendor, community-governed under the Apache Software Foundation, and recently graduated to a Top-Level Project; the clearest signal of ecosystem maturity and broad industry commitment. AWS, Dremio, Snowflake, and a growing contributor base are backing Polaris, mirroring the same competing-vendor convergence that made Iceberg unassailable as the table format standard. The catalog holds the policies; engines like Dremio enforce them. When both the catalog and the engines that enforce its policies are open, your governance framework travels with your data rather than being locked to a single platform.
The Emerging “Fourth” Layer
The semantic layer is the emerging fourth layer and arguably the one that matters most in an AI-driven world. It is how business meaning gets applied to data so that both humans and AI agents can query it correctly. A table called fact_orders with a column called amt_usd tells a query engine nothing about whether that number is gross or net, whether it includes returns, or how it rolls up into the metric the CFO calls "revenue." Without a semantic layer, every analyst writes their own interpretation and every AI agent hallucinates a different one.
This layer has moved from nice-to-have to critical infrastructure because AI agents are rapidly becoming a primary query interface and they need unambiguous, machine-readable definitions of metrics, dimensions, and business logic to generate correct SQL. The question is no longer whether you need a semantic layer. It is whether the one you invest in will be open.
The industry is moving toward an answer. The Open Semantic Layer initiative, driven by 20+ companies including Dremio, is building a vendor-neutral interchange format so that semantic definitions written once can be consumed by any engine, any BI tool, and any AI agent, without rewriting them for each vendor. This follows the exact pattern of the layers beneath it: Iceberg won table formats and Polaris is winning the catalog because community governance and multi-vendor adoption made them durable standards.
For organizations evaluating this space now, the practical guidance is straightforward: begin inventorying how your business metrics are currently defined and where those definitions live. If they exist only inside a single BI tool or in tribal knowledge across analyst teams, they are not AI-ready. Standardizing those definitions in a format that is portable across tools and engines is the first step and it is one you can take today regardless of which open semantic standard ultimately prevails.
Shell: Enterprise-Scale Analytics Without Vendor Lock-In

Shell operates data environments across multiple cloud platforms and geographic regions. Their challenge was a coordination problem: how to give analysts and data scientists access to data across global domains without requiring each domain to run on the same proprietary infrastructure.
By adopting Apache Iceberg as their table format and Dremio as the query layer, Shell processed 6 to 8 billion records in minutes, ran more than 100 concurrent analytical models against the same underlying data, and built a data mesh across global energy operations without requiring uniform cloud environments across regions. Individual teams continued using the compute tools already in their environment. The open catalog and query layer provided unified access without moving or copying data.
Iceberg Summit 2026: What the Ecosystem Told Us
Iceberg Summit 2026 brought the open lakehouse community together in San Francisco for two days of technical sessions, real-world implementation case studies, and roadmap discussions with the core maintainers shaping Apache Iceberg's future. With over 70 sessions and platinum sponsor participation from AWS, Databricks, Google Cloud, Microsoft, Snowflake, and Dremio, the breadth of the contributor base on display was itself the signal: the standard with the most diverse ecosystem wins, and Iceberg is that standard.
The conversations happening at an event like this one do not stay theoretical. They feed directly into the roadmap decisions, governance models, and interoperability commitments that determine whether open standards hold or fragment. That is why Dremio co-organizes it.

The Architecture Choices You Make Now Are Harder to
Change Later
Over the past quarter, I have met with data leaders across industries who are navigating the same question: how do you build a data platform that supports AI workloads today without constraining your ability to choose better tools as they emerge?
The pattern I see in organizations that are moving fastest is consistent. They made an early decision that every layer of their data architecture needed to be open and community-governed; the file layer, the table format, the catalog, and increasingly the semantic layer. Not because they planned to switch vendors, but because they wanted the option. That decision is paying off now as AI workloads multiply integration points and every proprietary layer in the stack creates a new switching cost.
A data architecture built on open standards does not feel different from a proprietary one in year one. The difference shows up when you want to run a new AI workload and the compute engine your team prefers cannot read your proprietary file format. It shows up at the catalog layer, when a new team needs access to a dataset and discovers that access policies are locked inside a single vendor's governance service. It shows up at the semantic layer, when an AI agent generates incorrect SQL because your metric definitions live inside one BI tool and are invisible to everything else. And it shows up at renewal time, when you are spending 40 to 50 percent more than you expected and the switching cost across all of these layers is the reason you sign anyway.
Dremio is built on the same open standards your other tools use, Apache Parquet, Apache Iceberg, Apache Polaris, Apache Arrow, across every layer of the stack.
"The data you manage through Dremio stays in formats any compatible tool can read, governed by catalogs any compatible engine can discover, and defined by semantic models that are portable rather than proprietary. That is the practical meaning of open."

Sendur Sellakumar
CEO, Dremio
Take the next step with Dremio


See Dremio in Action
Explore this interactive demo and see how Dremio’s Agentic Lakehouse powers AI and BI workloads.