Fewer Accidental Full Table Scans Brought to You by Apache Iceberg’s Hidden Partitioning

Partitioning Up Until Now
When it comes to running queries on your data lake, Hive delivers some great conveniences in being able to write SQL queries that can be converted into MapReduce jobs on HDFS (Hadoop Distributed File System). Hive provides users the ability to interact with tables by putting files in a particular directory – but this means when you query that table it will scan through every record (referred to as a full table scan), which makes queries take a long time to plan and to execute, especially at scale. To address this problem, Hive went with the tried-and-true method of partitioning, which enables you to specify a column or columns to split the dataset into smaller pieces.
For example, if the queries on a dataset commonly filter by month, you may want to partition the data by month. However, in most events and datasets, there isn’t an “event_month” field – rather, it’s usually event_date or event_timestamp. So, in order to partition by month, the ETL job writing the data to this table would have to duplicate the data in the event_timestamp field, truncate it to the month granularity, and write it to a new column “event_month.” This creates a directory in the table directory for each month, and queries that filter by this derived “event_month” field would take advantage of partition pruning and avoid a full table scan, resulting in much better response times.
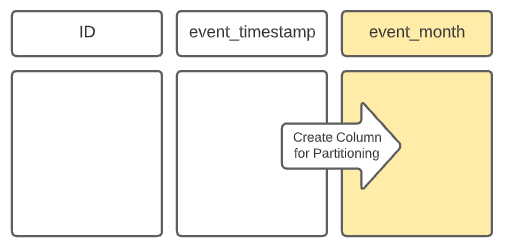
However, many users of the dataset, especially new users, may not know about this duplicative field. They’re typically used to filtering by when the event really happened – the event_timestamp. If a user’s query filters for a single month, but not on the new event_month field (e.g., event_timestamp BETWEEN ‘2022-01-01’ AND ‘2022-01-31’), the query will not do any partition pruning, resulting in a full table scan and painfully slow response times.

By relying on the physical file system structure to determine what is a table and a partition, Hive tables had several disadvantages:
- The wrong partition scheme could result in many subdirectories and files which could make query planning and execution take longer as they iterate through directories and files, aka the infamous small file problem.
- If you wanted to re-partition, it would involve a complete rewrite of the data because the data would have to be reorganized along with the directory structure which would be very costly.
- Partition columns must be used explicitly to avoid a full table scan. For some partition schemes, you need to create a new column (for example, taking a timestamp and making a year, month or date column). To benefit from the partition you always have to include the new month column in your query even if you specified a “where” clause on the original timestamp column.
There’s a need for a better way of tracking tables and partitions whether using Hive with HDFS, Cloud Object Storage, or any other storage layer.
Smarter Partitioning with Apache Iceberg
There have been several attempts to create a “table format” that can track tables in a way that eliminates many of these pain points. Each has different limitations, such as what file types you can work with, what types of transactions are possible, and more. At Netflix, a solution was created that is now an Apache Foundation Project called Apache Iceberg.
The Apache Iceberg table format separates the definition of tables and partitions from the physical structure of the files through three layers of metadata that track the overall table, its snapshots, and the list of data files, respectively. This brings many benefits:
- Since partitions are tracked within metadata files, you don’t have to worry about partition subdirectories slowing down your queries based on your partitioning.
- You can evolve your partitions. For example, if you were partitioning data by year and wanted to partition by month going forward you can do so without rewriting the table. The old data will follow the old partition, new data will follow the new partition, and Iceberg will be made aware in order to plan queries appropriately. Evolving your partitions can be a lot less expensive than a complete repartitioning rewrite.

In particular, an Iceberg feature called “hidden partitioning” helps overcome many of the challenges associated with partitioning Hive tables.
Let’s say you have a table of dentist visits with a timestamp of when the visit occurred as a column. Hive would need the timestamp column transformed into a new column to partition the data by month. In the query below, the data is taken from one non-partitioned table and created in a new partitioned table.

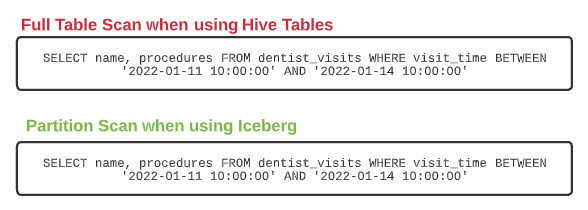
The problem arises when you want to query a particular set of days within a month (example below). Even though the where clause already captures the time window based on the same visit_time column that visit_month is based on, you still have to explicitly query the month column to get the benefit of the partition (without it a full table scan would occur). This could result in someone who is not familiar with the partitioning of the table running longer, more expensive queries than they need to.

The experience is significantly improved with the Iceberg format. Instead of creating a new field to be the partition column, you can specify a column and transform it. Both are tracked within the metadata without having to add a physical column to the table.

So when it comes to writing the files and organizing the data files and the metadata around them, such as manifests, Iceberg knows the table is partitioned by the column visit_time and the transform month. So when anyone queries the visit_time column there is no need to specify a different, partition-specific column in the query. That step is taken care of by Iceberg.
Manifest file(s)

When this query is being planned, Iceberg picks up on the column by which the table is physically partitioned and automatically generates two predicates, the scan predicate, and the partition predicate to filter which manifests or delete files (files that specify deleted records that shouldn’t show up in query results of the current snapshot) the query will be executed against.
Hidden partitioning allows for simplified management on the table definition and data writing side. On the data access side, data consumers don’t have to know precisely how the data is partitioned, if they query based on any defined permutation of a partitioned field they will automatically get the benefits from the query planning without having to add an explicit clause to take advantage of the partition.
Embrace an Open Architecture with Apache Iceberg
Iceberg metadata management provides huge gains in efficiency when writing/organizing/accessing business-critical data in the data lake. Hidden partitioning adds some very user-friendly functionality to make Iceberg easier to use and simpler to manage. Maximize your data lake by building on robust open formats like Apache Iceberg.
About the Author
Alex Merced
Alex Merced is a developer advocate for Dremio and has worked as a developer and instructor for companies like GenEd Systems, Crossfield Digital, CampusGuard and General Assembly. Alex is passionate about technology and has put out tech content on outlets such as blogs, videos and his podcasts Datanation and Web Dev 101. Alex Merced has contributed a variety of libraries in the Javascript & Python worlds including SencilloDB, CoquitoJS, dremio-simple-query and more.
Related Articles

Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files
Read more
Puffins and Icebergs: Additional Stats for Apache Iceberg Tables
Read more