
NEW YORK CITY + VIRTUAL
The Unified Lakehouse Platform for Self-Service Analytics and AI
Bring users closer to the data with lakehouse flexibility, scalability, and performance at a fraction of the cost. Dremio's intuitive Unified Analytics, high-performance SQL Query Engine, and Apache Iceberg Lakehouse Management service for next-gen dataops let you shift left for the fastest time to insight

Dremio Overview
1 MIN













24
Days
24
Hours
24
Mins

WHY DREMIO
Unified analytics on the lakehouse for high-performance, self-service access anywhere, on-premises, hybrid, or cloud
Shift left analytics means bringing your users closer to your data, delivering seamless enterprise-scale analytics with no data movement. Dremio makes it easy to shift left, letting you connect, govern, and analyze all your data, where it lives, at the speed of business.

Less than 50% TCO compared to leading lakehouse platforms, eliminating data warehouse workloads and data movement

Streamline and eliminate complex and costly data integration, ETL, and data pipeline management

Simplify data management and optimization with next-gen dataops on Apache Iceberg that reduce risk to production data
HOW IT WORKS
Lakehouse flexibility meets analytics velocity with Dremio
Unified Analytics
Drive business insight and innovation by putting all of your data to work. Dremio delivers streamlined self-service analytics for all your data, everywhere, for all of your users.
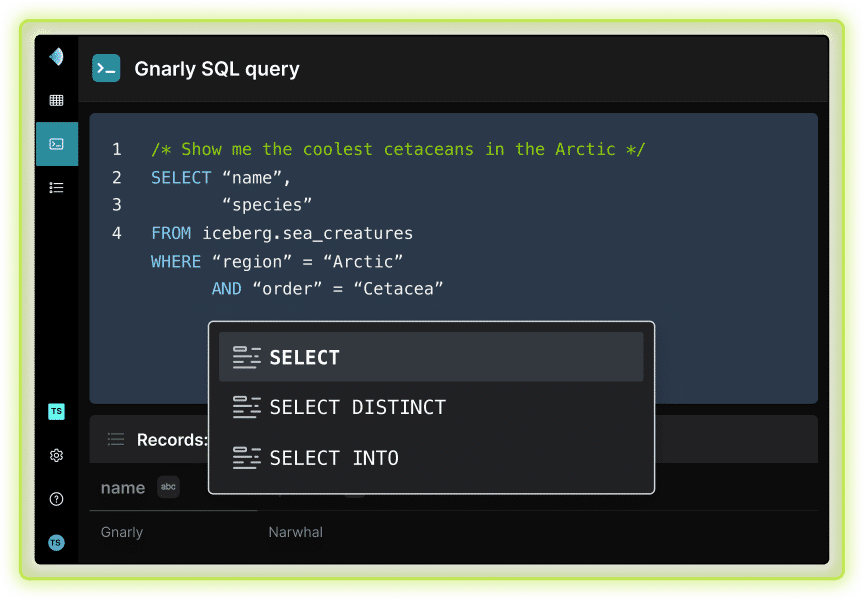
SQL Query Engine
Attain sub-second analytics performance on the data lake and across all data sources with no data movement. Dremio's intelligent query engine offers a powerful end-user experience with transparent query optimization and acceleration.

Iceberg Lakehouse Management
Simplify lakehouse data management with an integrated Apache Iceberg modern data catalog, automated data optimization, and Git-inspired versioning for next generation dataops.

Arctic Product Overview
1 min
Arctic Product Overview
1 min
Designed to meet your infrastructure needs with lakehouse analytics as a managed service in the Cloud or self-managed Software on-premises and in the cloud.

Solutions with Dremio
Unified lakehouse solutions for analytics challenges across industries
Solutions for data lakehouse flexibility, scalability, and performance at a fraction of the cost. Dremio is built for analytics use cases across all industries.
Lakehouse
Data Mesh
Hadoop Migration
Self-service analytics with data warehouse functionality and data lake flexibility across all your data
- Standardize on open data architecture, no vendor lock-in
- TCO savings by removing complex ETL processes and data copies in BI extracts and cube
- Simplify lakehouse management with Git for Data and automatic table optimization

Build a distributed data architecture with a single solution for data mesh
- Deliver meaningful data products to end users while preserving business context and logic
- Create, search, and access data products with Dremio's universal semantic layer
- Federate domain ownership and register data for consumption with an integrated data catalog
Modernize legacy Hadoop infrastructure with Dremio
- Reuse existing investment of Hadoop and get up to 20x faster query performance
- Decouple compute and storage with a flexible data lakehouse architecture for hybrid or cloud
- Govern access to data with Dremio native and Apache Ranger security policies

Lowest analytics total cost of ownership and fastest time-to-insight with Dremio
50%
Analytics TCO savings in one year
100x
Faster Query Performance
4x
Better Price-Performance than Trino
Why Customers Choose Us
1000s of companies across all industries trust Dremio
Dremio's data lakehouse helped Amazon achieve 10x faster query performance and reduce project completion times by 90%
10x
Analytics TCO savings in one year

“With its strong query performance and semantic layer capabilities, Dremio is the perfect backbone for our Henkel data lake,”
30x
Improved Price-performance

With Dremio, NCR directly queries data from the data lake with BI tools that are effective and timely. Users self-serve data directly through Dremio's semantic layer on top of the data lake. Development time for reports and dashboards is reduced from months to days.
30 %
TCO savings
Learn More About Dremio
Learn how Dremio is making lakehouse analytics faster, easier, and more cost-effective
Read our reviews on






