Dremio Unified Lakehouse Platform
Bring your users closer to the data with lakehouse flexibility, scalability, and performance at a fraction of the cost
The Dremio Unified Lakehouse Platform lets you connect, govern, and analyze all of your data, both in the cloud and on-premises.
UNIFIED ANALYTICS
Analytic insight at everyone's fingertips
Deliver seamless self-service analytics across all your data to accelerate speed to insight across the business. With intuitive capabilities for SQL developers, data analysts, and data scientists, Dremio makes it easy to move from data to insight.
- Self-Service Analytics for data-driven innovation
- Consistent, collaborative data with a universal Semantic Layer
- Centralized data governance to balance data access and control
- Frictionless connector integrations for all your data
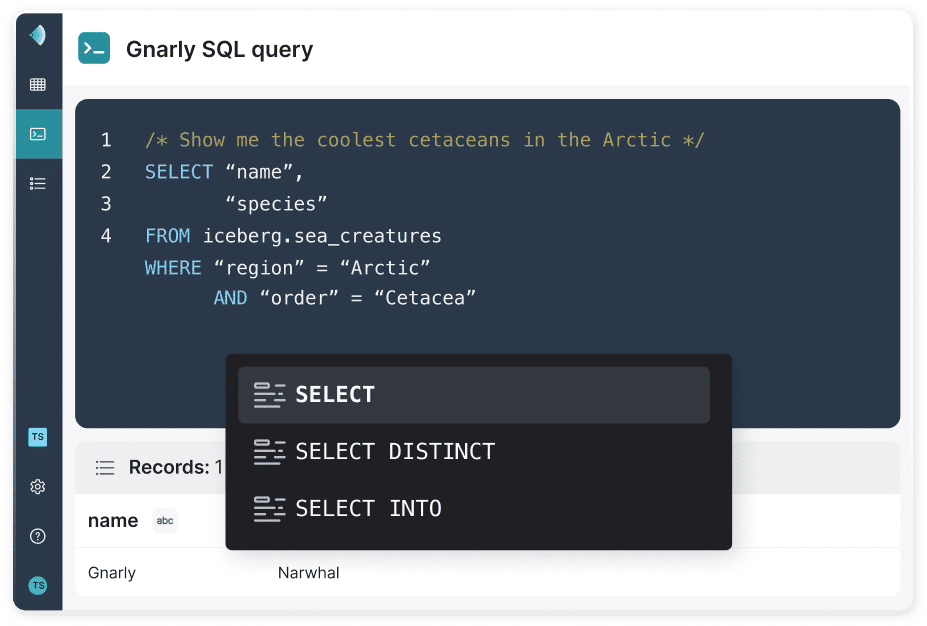
SQL QUERY ENGINE
SQL Query Engine for for high-performance BI and interactive analytics
The Dremio SQL Query Engine is designed for sub-second BI workloads directly on your data lake and across all your data sources with no data movement. Transparent query optimization and intelligent acceleration deliver a seamless, fast experience for all analytics users.
- Optimized price performance for every query
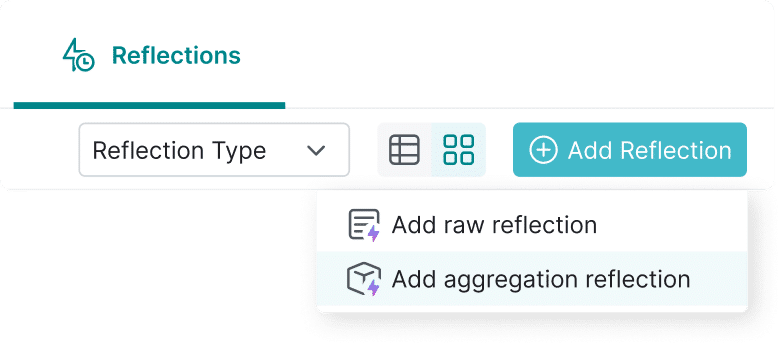
- Up to 100x faster performance with Reflections query acceleration
- Flexible, fast, lightweight data transformation
- Built for Cloud, multi-Cloud, on-premises, and hybrid environments
MODERN DATA CATALOG
Lakehouse Management for next generation DataOps
Dremio provides a modern lakehouse catalog that automatically optimizes Apache Iceberg tables and provides Git for Data management capabilities.
- Modern data catalog for easy data management and discovery
- Git-inspired data versioning
- Automatic optimization of Iceberg tables for high-performance analytics

Arctic Product Demo
2 mins
Dremio Customer Case Studies

Case Study
Improved Supply Chain with >10x Query Performance and 90% Faster Project Delivery
Dremio's data lakehouse helped Amazon achieve 10x faster query performance and reduce project completion times by 90%.
Learn more

Video
How Maersk adopted a Modern Data Stack and GenAI on a budget
Learn how Maersk is building the next generation data platform for unified analytics on Dremio’s Open Data Lakehouse, on a budget...
Watch Now

Case Study
Improved Project Delivery Speed and Lowered Costs.
Dremio's data lakehouse helps NCR complete analytics projects 90% faster and delivers >10x price performance.
Learn more